

Datasets & Computer Vision
Data & Projects
The status quo in a machine vision enterprise is commonly one with multiple sources for unstructured data and multiple deep-learning projects consuming it.
Your data may include a combination of
- Data delivered by an outsourced 3rd party, such as a contracted labeler
- Data created by an internal tool, such as your labeling platform
- Data downloaded from a public source, such as ImageNet or COCO
All data sources might be similar but not similar enough to have a single pipeline.
While projects often have their own unique data source, it is common that they share some, too.
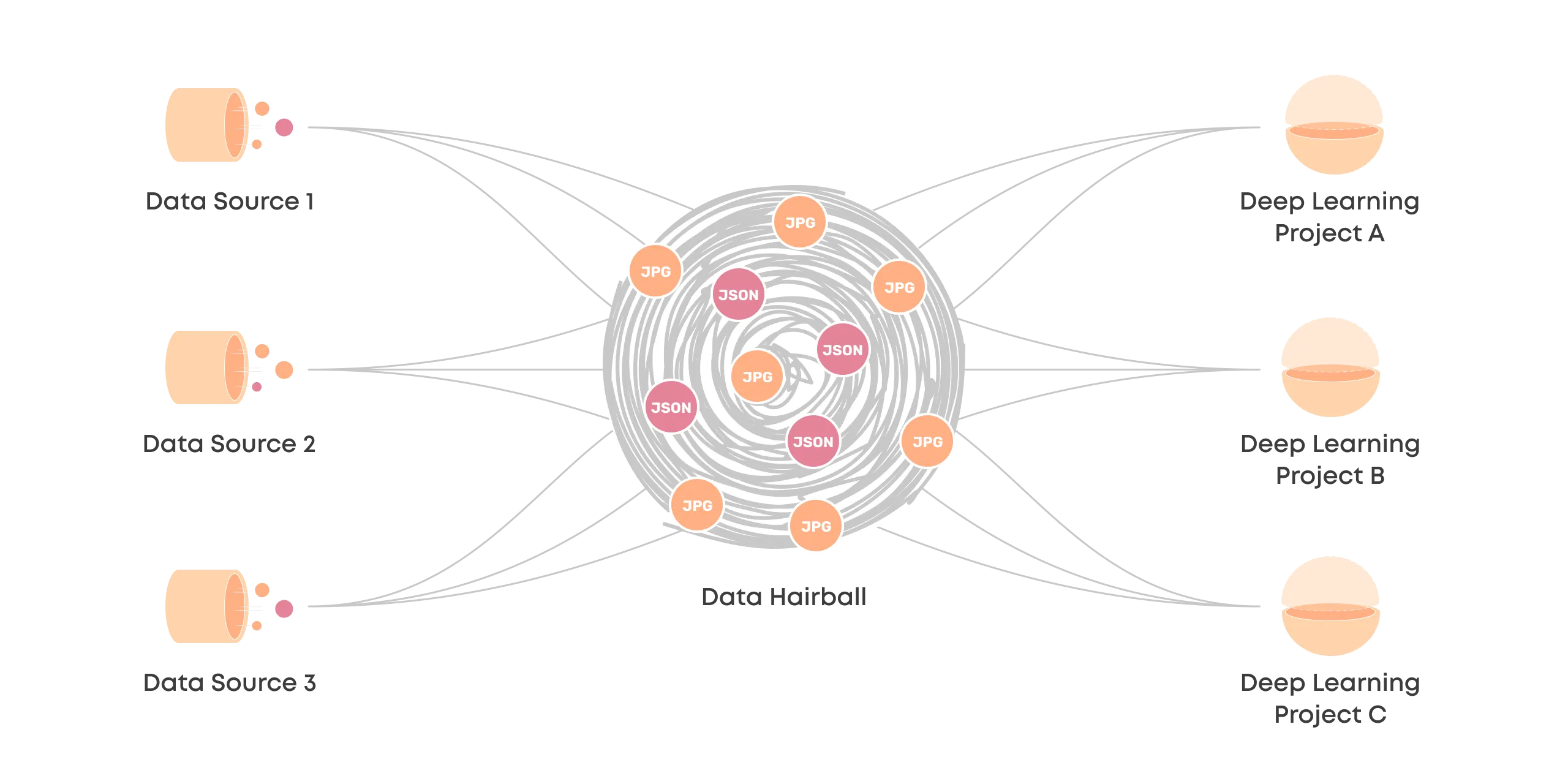
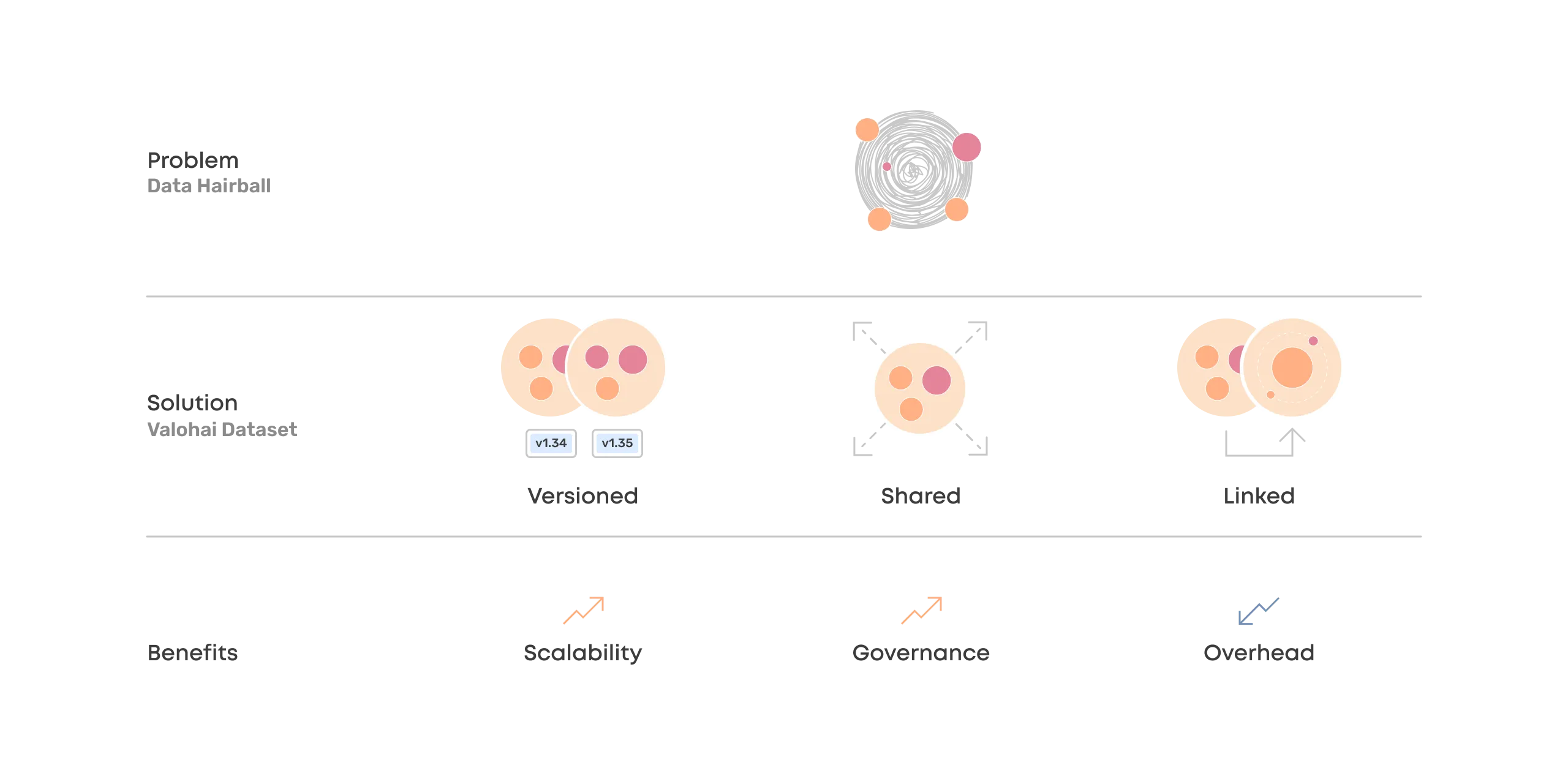
Data Hairball
After the initial pioneer's honeymoon, this operation starts to scale and eventually becomes unmanageable.
The lack of a unified process for linking the data sources with deep learning projects means no communication between the teams, no versioning of changes, and a situation where anything can potentially break everything.
This is the data hairball – and to put it simply, it's an unsustainable position for several reasons:
- First, unmanaged complexity will make it difficult to scale.
- Second, many workflows will be rebuilt again and again, draining resources.
- Third, duplicate workflows will use up computational resources.
- Finally, governance will be impossible as workflows are ad-hoc and opaque.
Unified Process
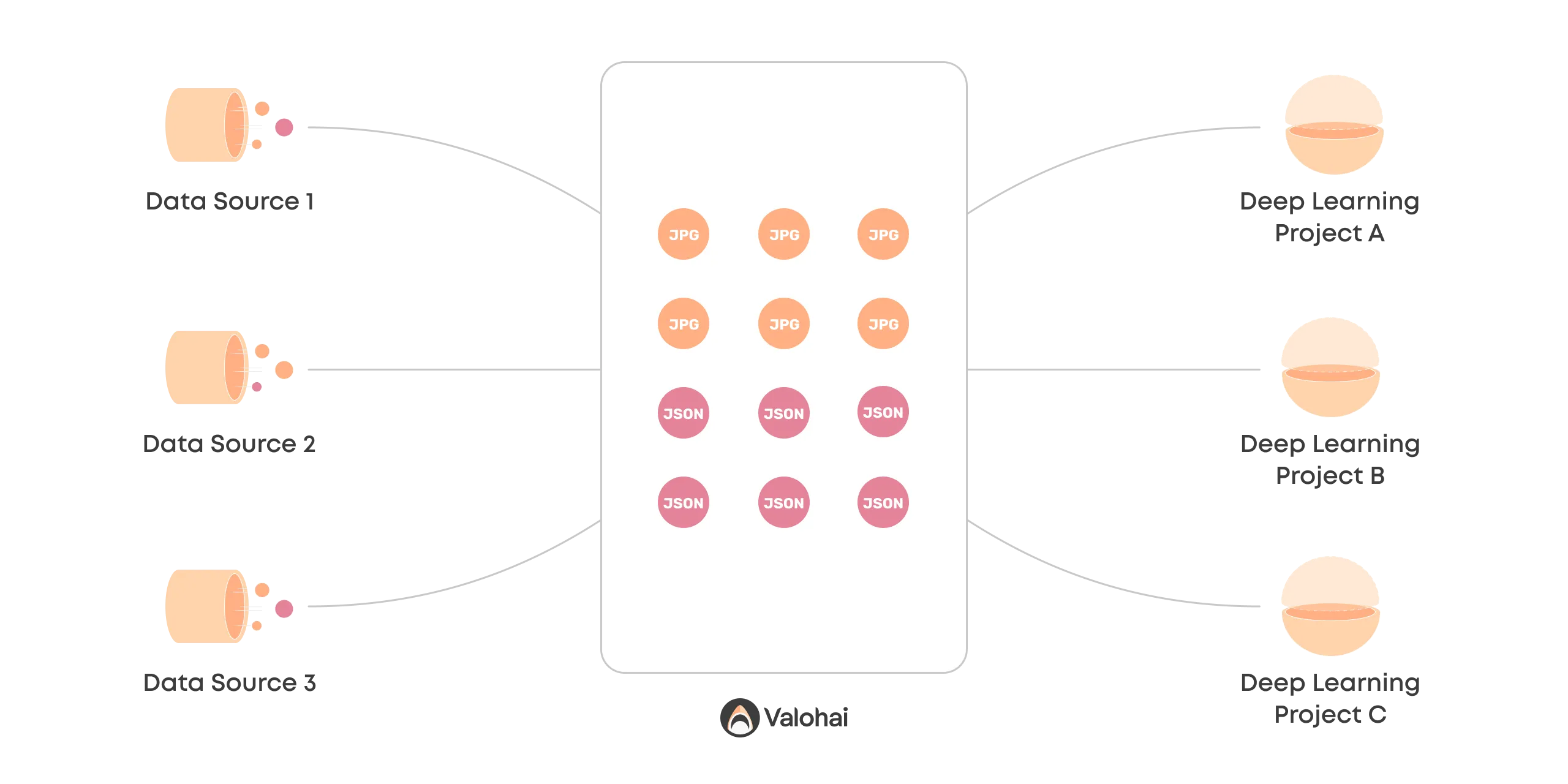
A unified process between the data sources and the deep learning projects is needed to untangle the data hairball.
Valohai creates a managed layer between data and projects, allowing communication and versioning over time. As a result, pioneers can keep experimenting at scale and building out projects towards production – without breaking things for others and creating a data hairball.
Let's be clear for a moment, though. Valohai, on its own, is not a unified process, but it does most of the heavy lifting automatically, taking away most of the discipline and implementation work.
Enter Valohai Datasets
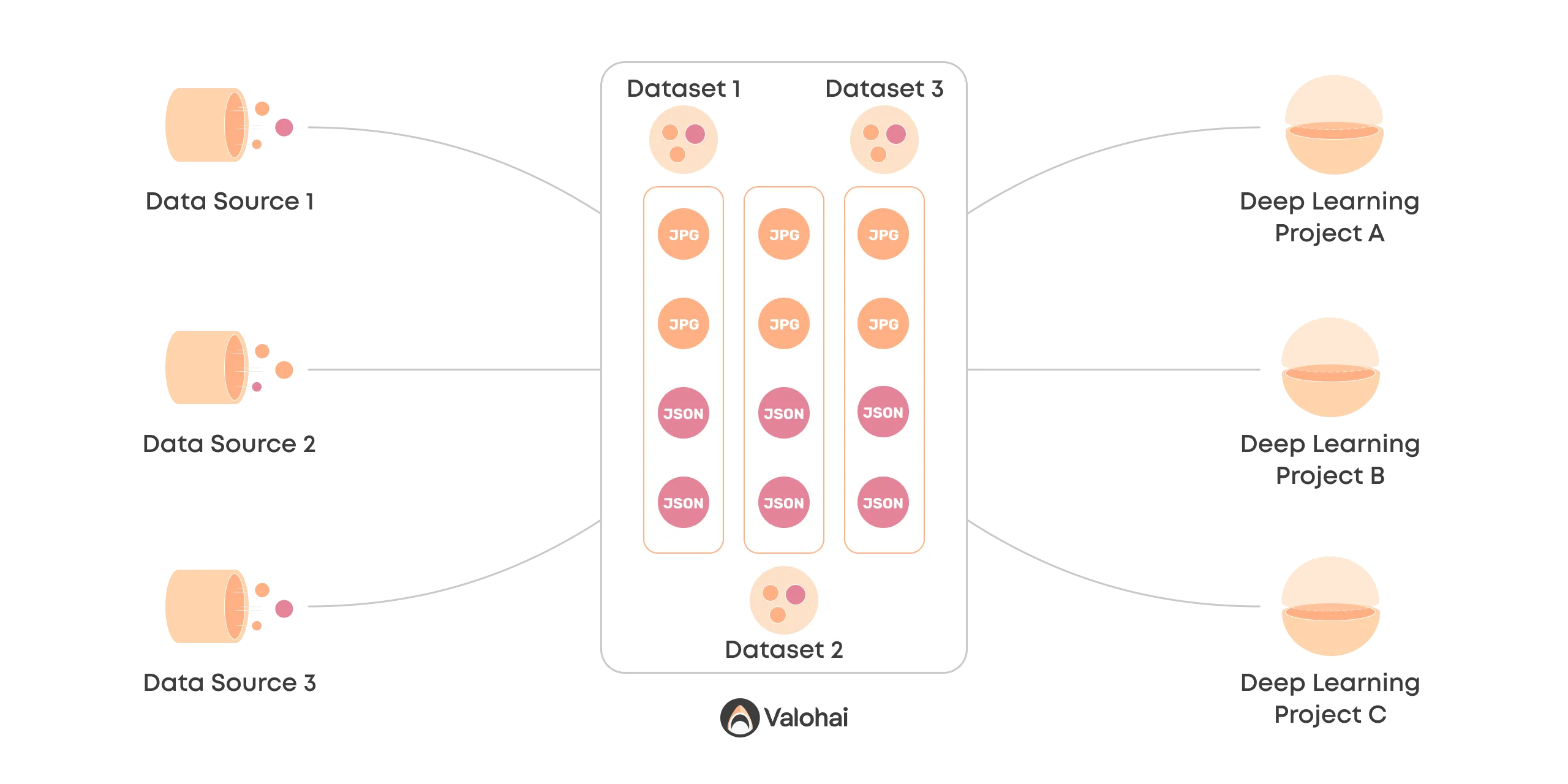
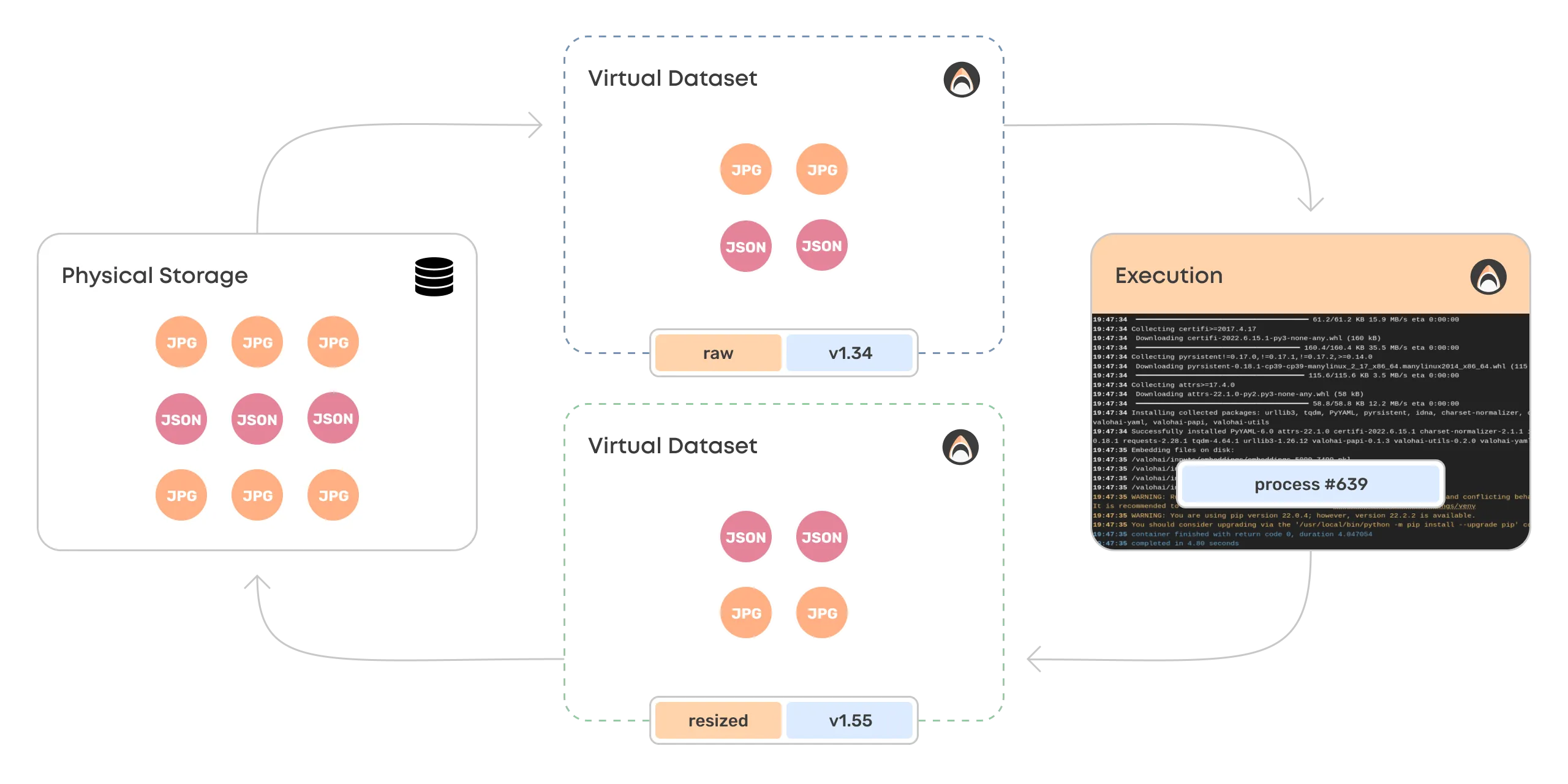
A new core concept for creating a unified process is the Valohai dataset. It creates a common ground for managing, versioning, and communicating unstructured data.
Files are no longer scattered around blob storage but managed with a single process and a single source of truth.
Let's look deeper into how Valohai datasets are created and what they can do for you.
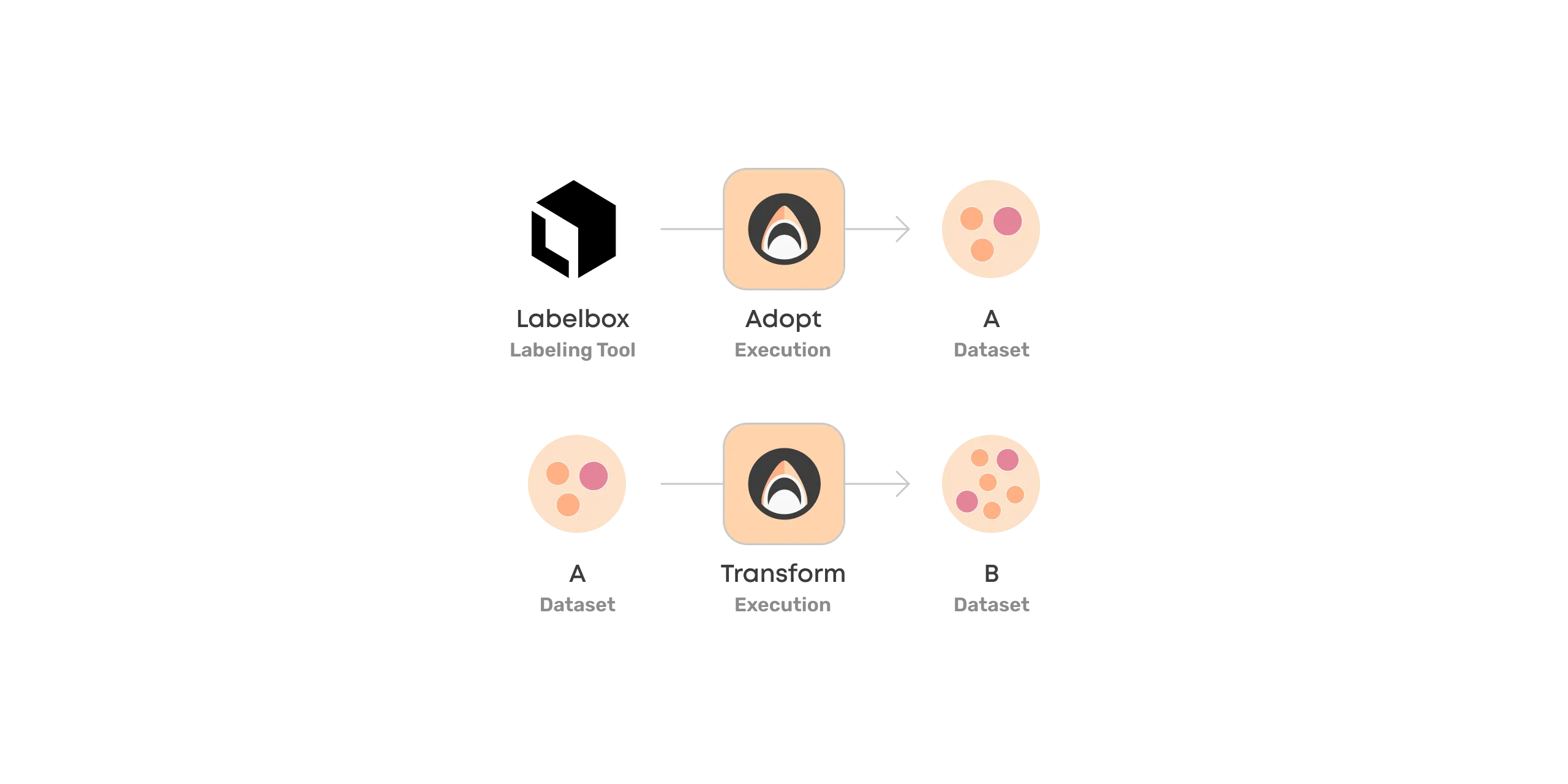
Adopting Datasets
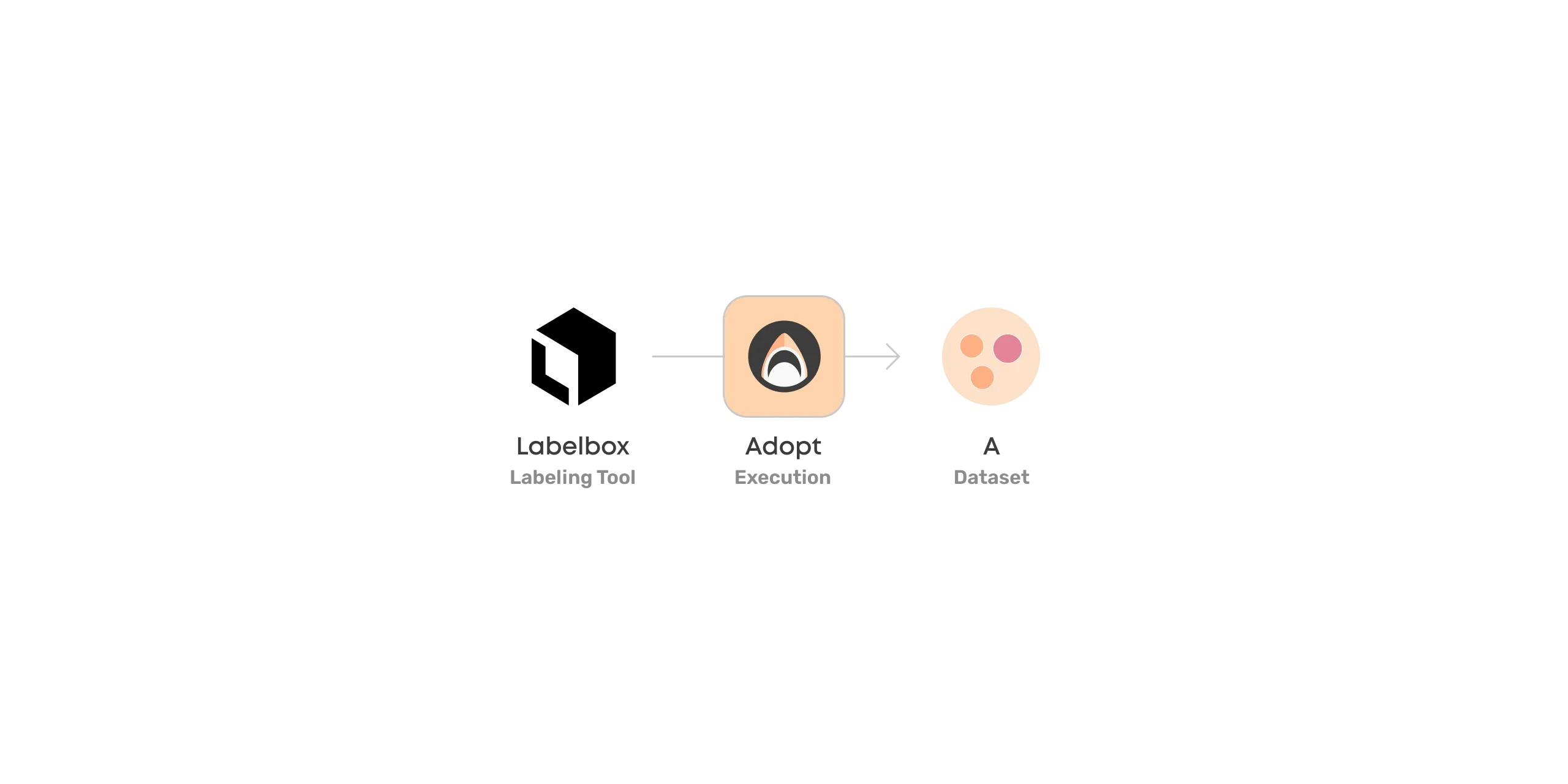
First way to create Valohai datasets is by adopting them.
You can point to a group of files in your data store (such as S3) and let Valohai know that they are meaningful together.
You can also adopt datasets from 3rd party tools, usually through APIs provided by these tools. The most common tools we encounter in the computer vision space are:
- Labelbox
- Sama
- Superb AI
- V7Labs
- SuperAnnotate
Adopting datasets can be done programmatically via a Valohai execution or in the Valohai UI by selecting files. You can find more on this in the documentation.
Transforming Datasets
Another way to create Valohai datasets is by transforming existing datasets into new ones.
The most common example is taking raw images and preprocessing them to create a dataset of images ready for training. This may include code for standardizing images or creating new variants with various transformations (data augmentation).
Another example is merging multiple datasets into a single one.
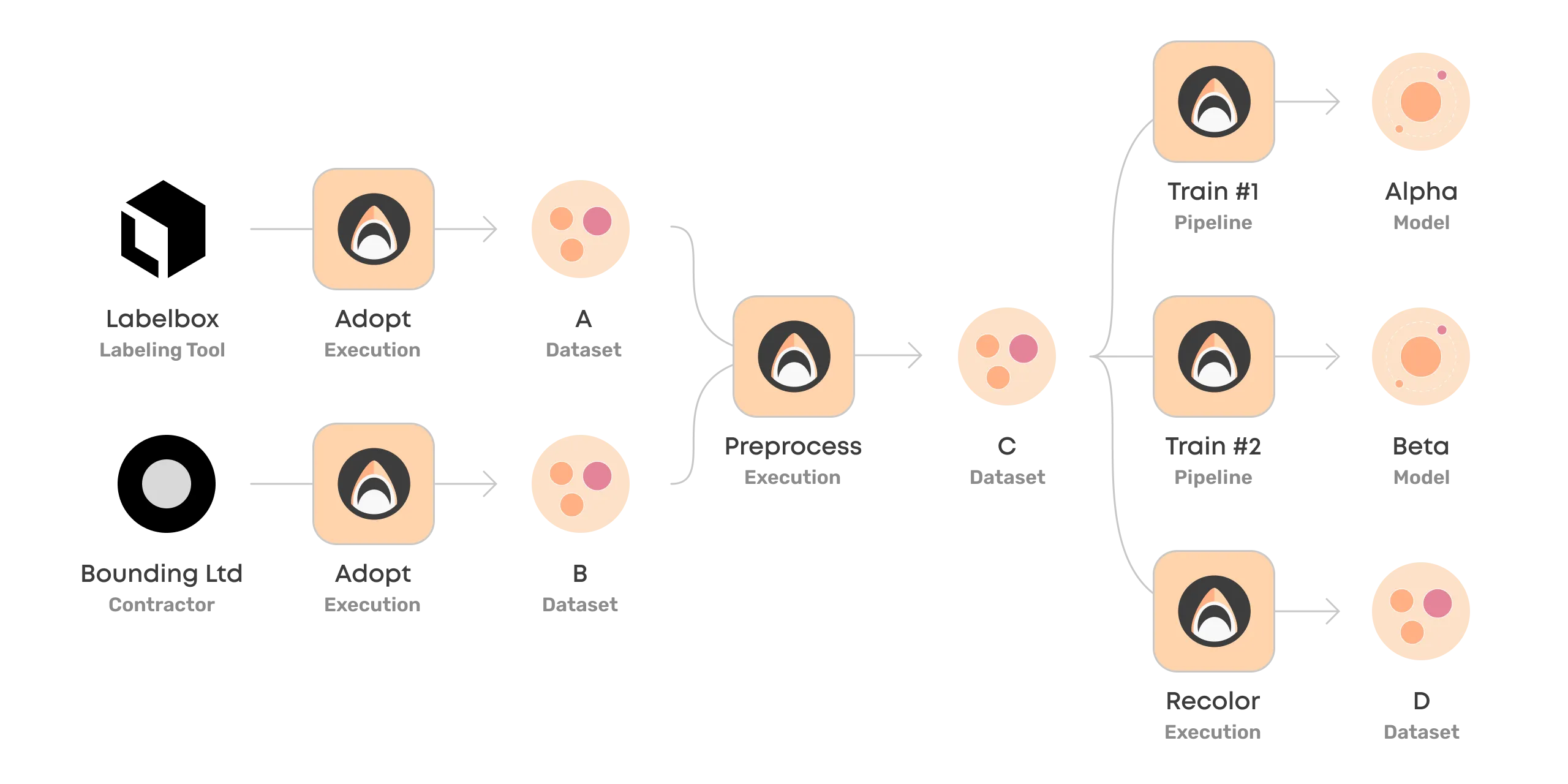
Using Datasets in Pipelines
Different dataset transformations and training steps can be combined into a reproducible Valohai pipeline.
Valohai pipelines are a flexible tool to systematize ML workflows for a few different reasons:
- Pipelines can contain any number of steps using different dependencies.
- Pipelines can be run on-demand or scheduled.
- Pipelines are automatically versioned and shared.
- Pipelines are not tied to any specific cloud provider or data storage and can mix and match freely.
Ultimately, every project – at least those that make it to production – should aim to mature into an automated pipeline. This will pay off in the long run as update cycles can be made quicker without increasing overhead.
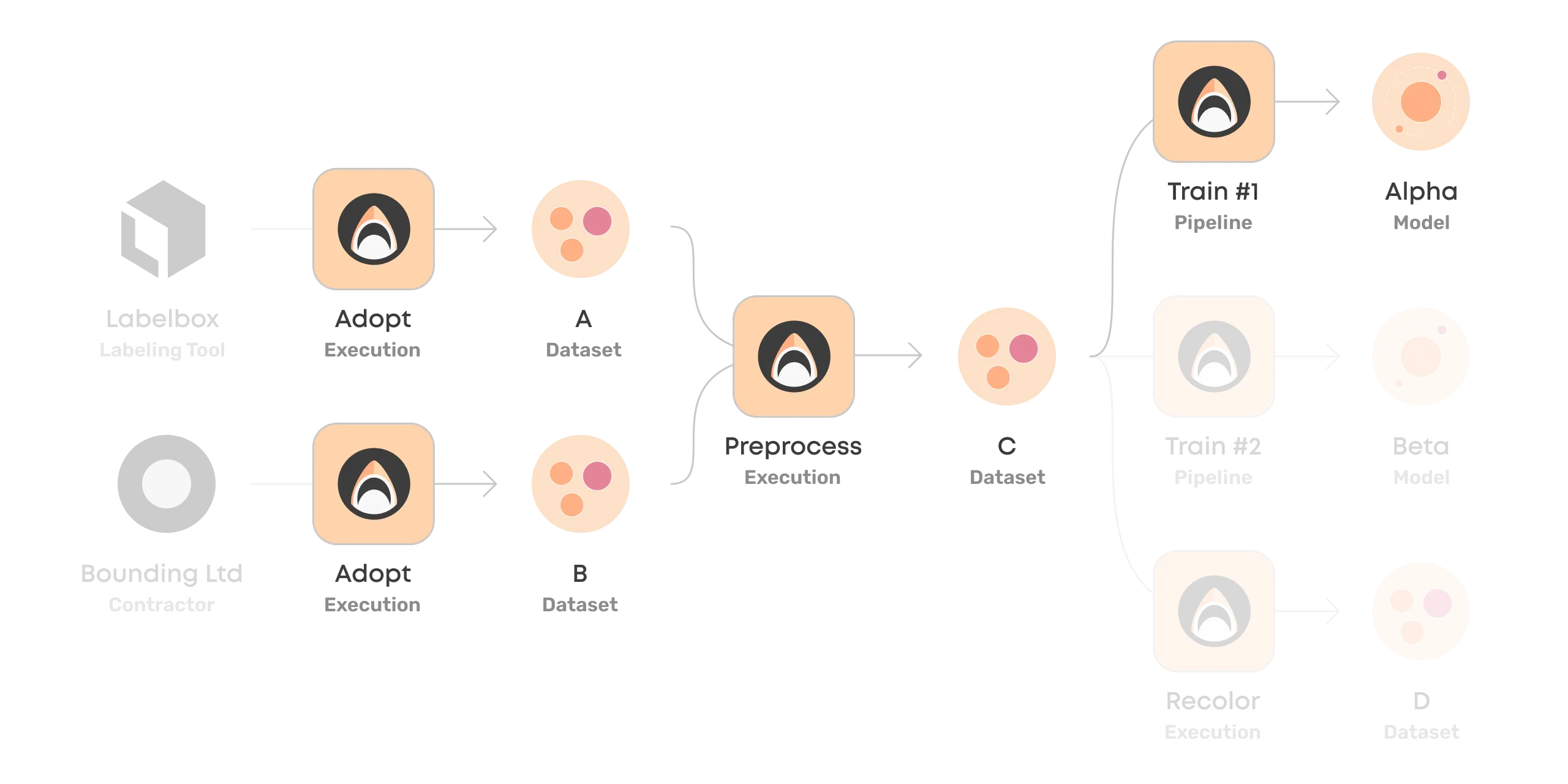
Ensuring Traceability
What seems self-explanatory at the moment will soon be a mystery. Therefore everything in Valohai is versioned and traceable. How a dataset or a model was created, when, by whom, and at what cost.
In our example pipeline, we can track every step, environment, and dataset that went into training the final model Alpha.
The linkage between datasets, pipelines, and pipeline steps makes Valohai datasets extremely powerful as it takes out the guesswork on whether the dataset was used as is.
Full traceability is critical so team members can reproduce each others' work, and models can be audited for governance reasons. Legislation around AI is slowly emerging, and it's better to be prepared.
Let's get technical!
Versioning and managing big unstructured data for machine vision is not a solved problem.
The data is dumped into data lakes, and the versioning is something everyone tries to figure out on their own. We lack a universal versioning standard that all pioneers love.
Versioning for other key ingredients - like code & dependencies - is more mature, though.
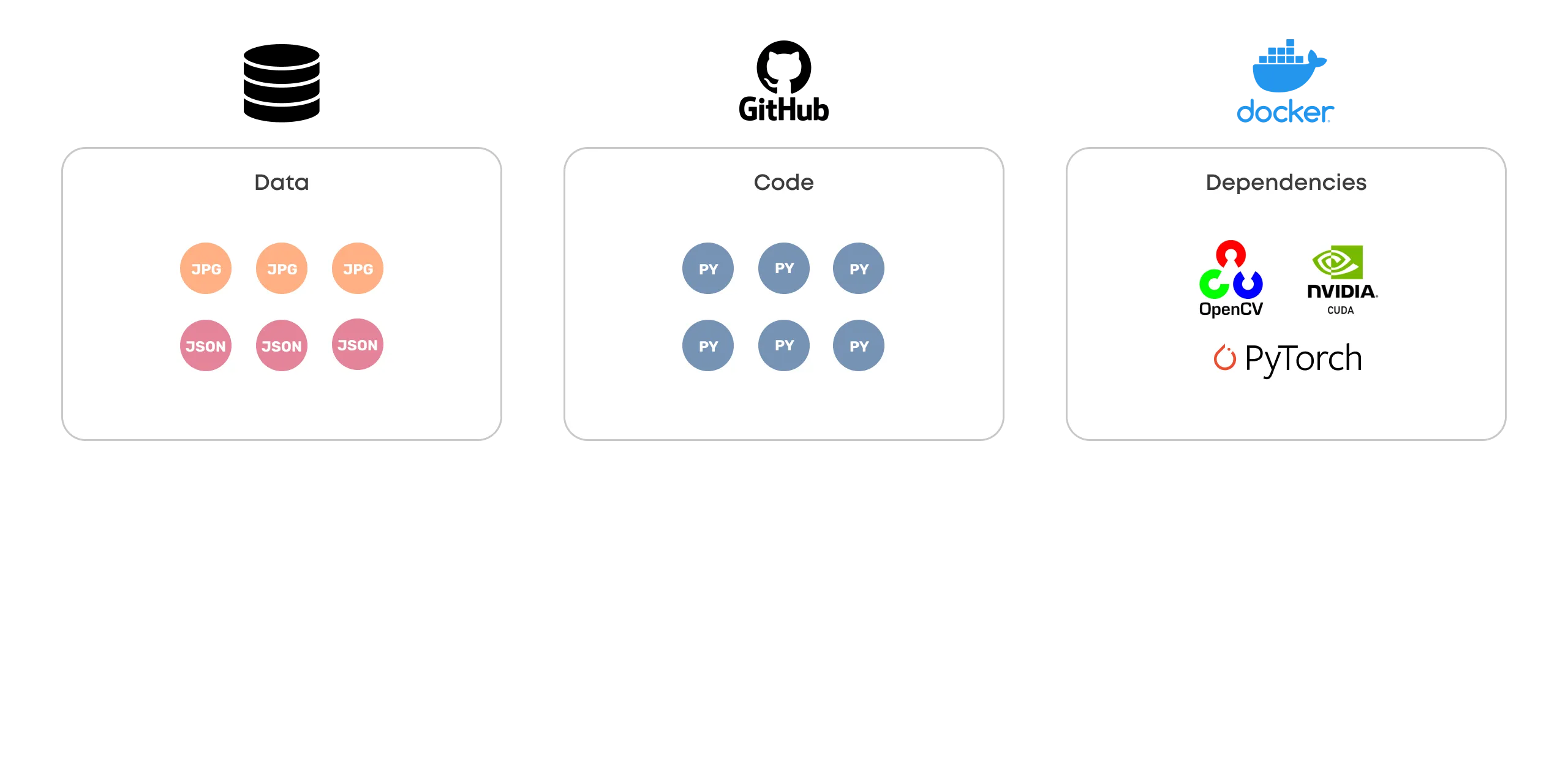
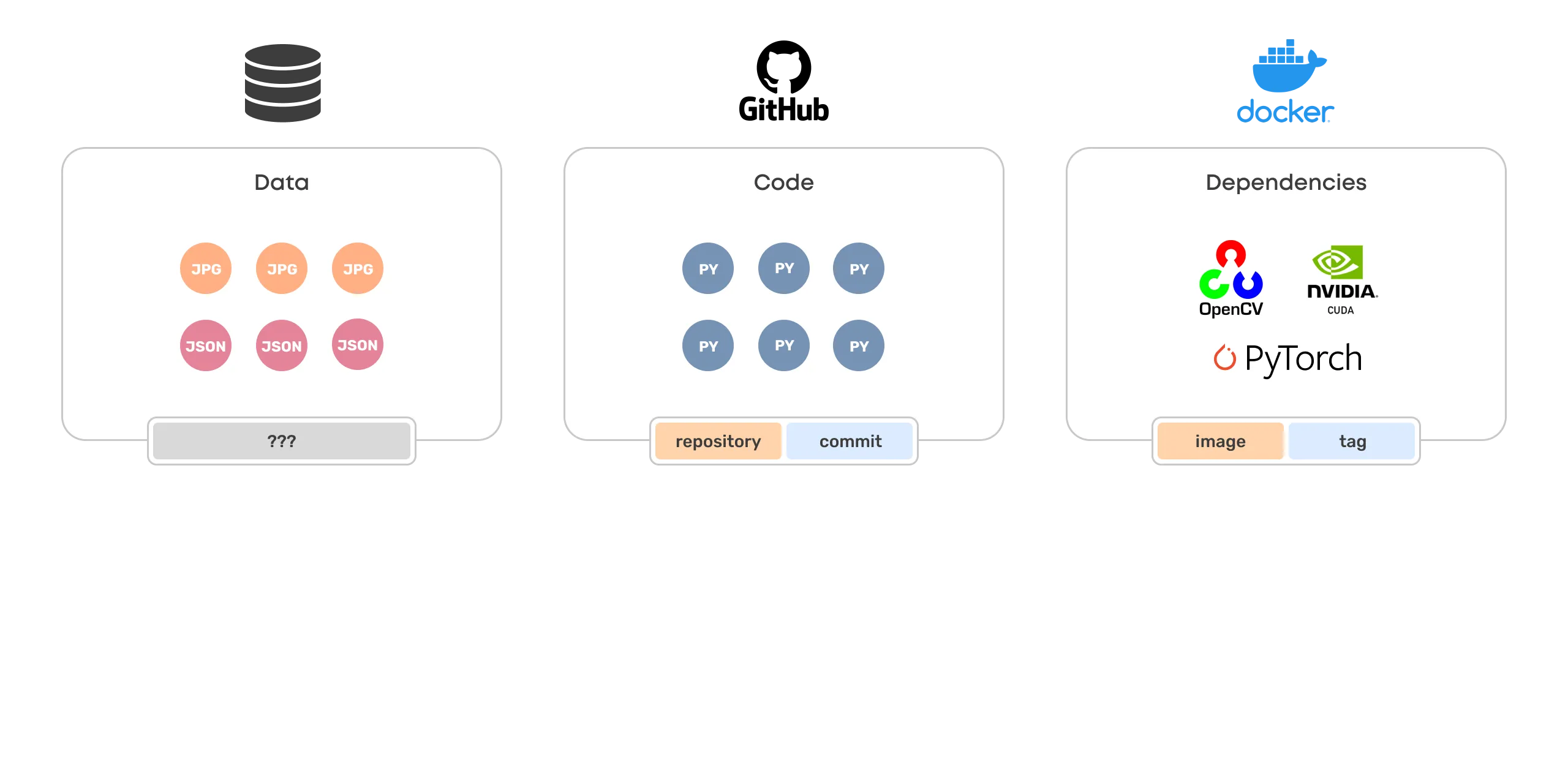
Data, Code, Dependencies
Code and dependencies are versioned and managed similarly across the industry, with clear winning standards:
- Git for code
- Docker for dependencies
- ? for data
No obvious standard for versioning and managing big unstructured data in a machine vision project exists.
Name and version
A common approach for managing collections of things in digital space is to tag them with a name and a version.
- In Git, a collection of code is referred to as a repository, and a version of it is a commit.
- In Docker, a collection of dependencies is packaged as an image, and a version is called a tag.
There are other naming conventions too, but they follow the same pattern. For a collection of unstructured data, however, there seems to be no ubiquitous convention.
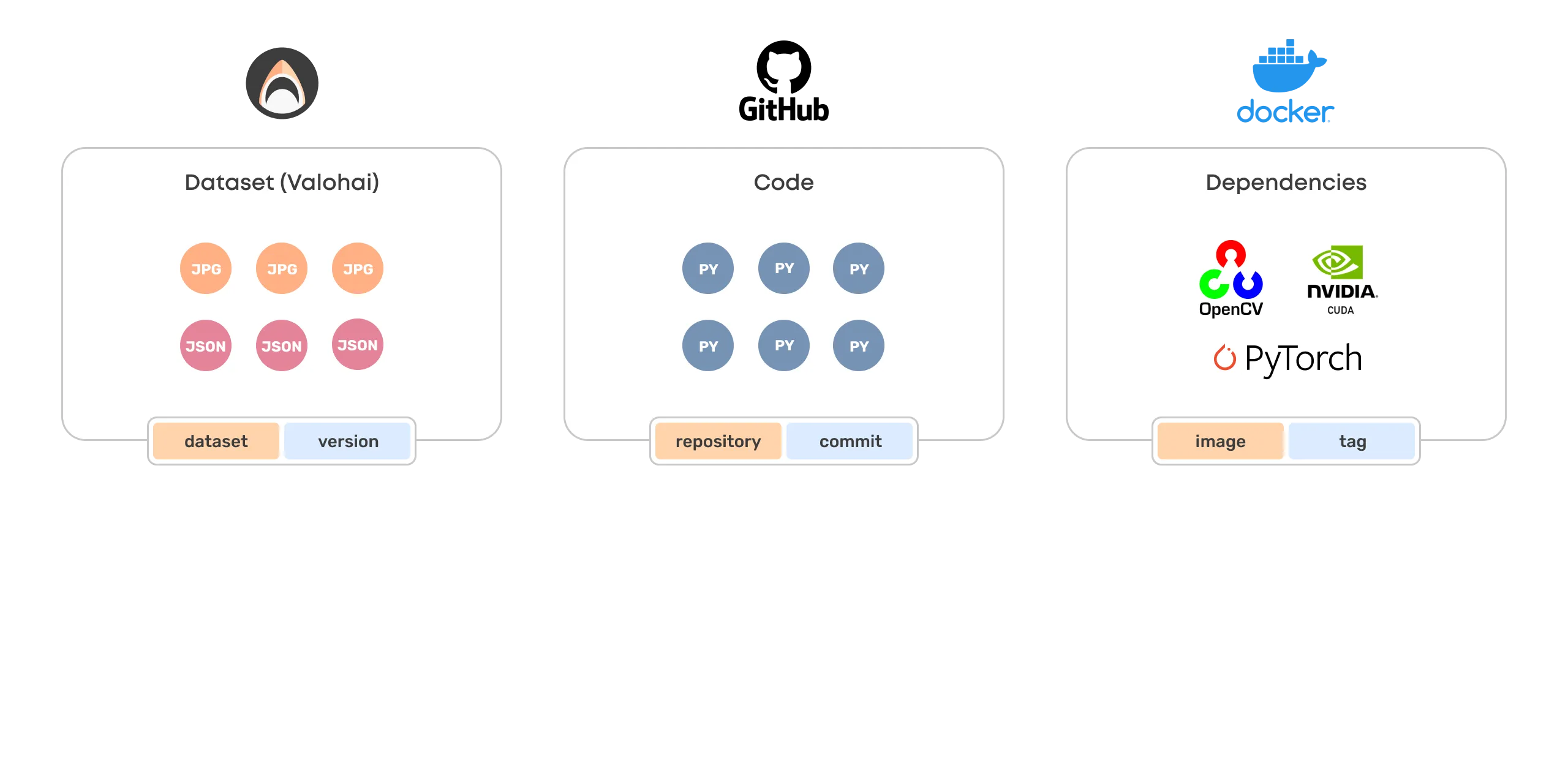
Valohai Dataset
Valohai datasets are the versioning standard that sits comfortably among the others.
Valohai dataset:version is to unstructured data what repository:commit is for code, and what image:tag is for dependencies.
Valohai datasets are versioned and managed with the same ethos as code and dependencies, and they are trackable and reproducible similarly, too.
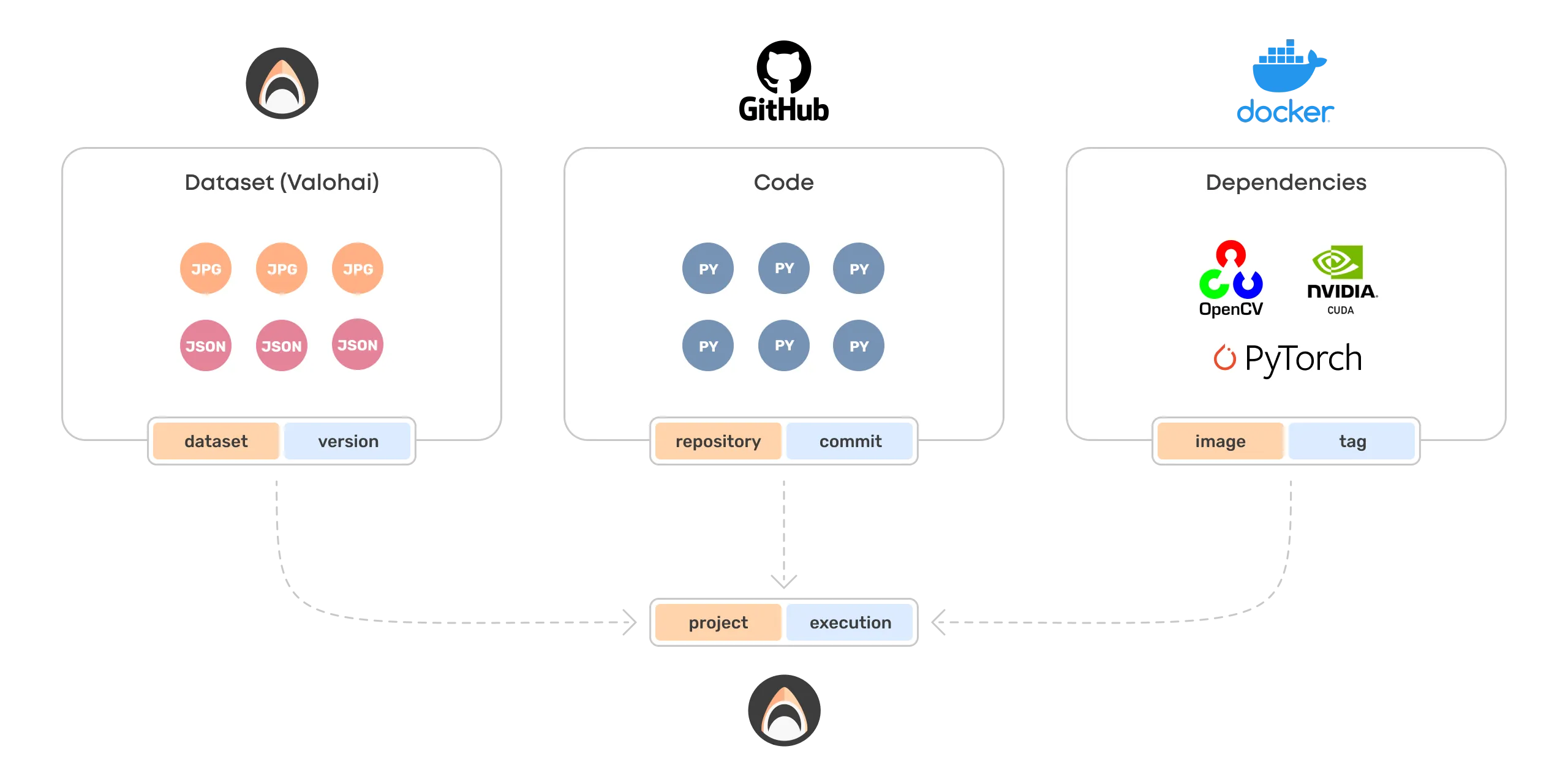
Valohai Execution
Now that we have solved dataset versioning, the data, code, and dependencies can come together in a fully reproducible and trackable ML experiment.
We introduce one final name & version pair, the project:execution in Valohai.
Every execution in Valohai is done within a project and is given a version number for tracking the progress of a project. Additionally, everything that goes into execution gets linked together.
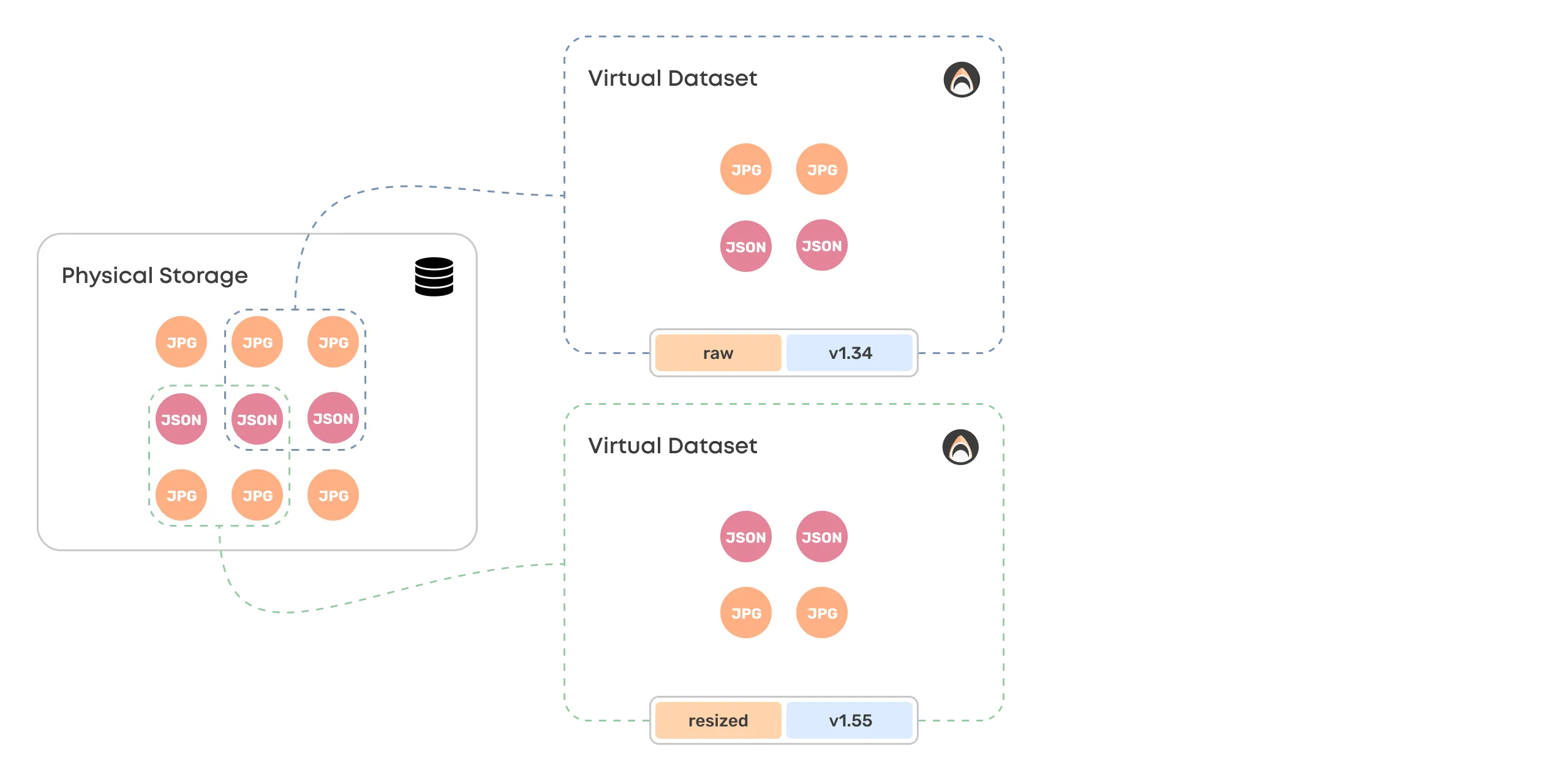
Storage
Valohai datasets are not physical but virtual, which means that the data is never duplicated. The same file can be in multiple datasets and versions at the same time.
In a private cloud setup, Valohai doesn't physically store the data. The datasets are references to the customer's data storage, which Valohai manages externally.
Versioning works by creating a hash for each file and a combined hash for the entire dataset.
Immutability
The dataset version is designed to be immutable to ensure full reproducibility.
A transformation step should always create a new version of the dataset instead of modifying existing files directly within the data storage.
As a pioneer-friendly platform, Valohai still lets customers manually modify the data at their own risk. The system checks the integrity of the data and alerts that the immutability has been broken and only partial trackability is possible.
TL;DR
- Connecting data and deep learning projects in a scalable way is a difficult problem. The Data Hairball is not the answer.
- Valohai datasets make implementing a unified process around data effortless through automatic versioning, sharing, and clear linkage between steps and datasets.
- Valohai datasets will ensure that governance and overhead don't become obstacles that hinder scalability.
More about Valohai
In this article, we've talked about Valohai datasets and pipelines but that's just scratching the surface of the platform.
Valohai is the MLOps platform purpose-built for ML Pioneers, giving them everything they've been missing in one platform that just makes sense. Now they run thousands of experiments at the click of a button, easily collaborate across teams and projects – all using the tools they love. Empowering the ML Pioneers build faster and deliver stronger products to the world.
