
Putting together a suitable dataset for training a model can be one of the biggest challenges, especially for a new team, as collecting (and labeling) data takes time.
We’ve written about ways to tackle this challenge before with synthetic data. In the synthetic data article, we generated complete data using the popular game engine, Unity. However, data augmentation tends to be a more common approach where you start with an existing dataset and expand it to have more variety.
What is Data Augmentation?
Let’s start by reviewing the basics of data augmentation. In simple terms, it is the process of creating new and representative data using your existing data. You can do this by adding in modified copies of data that already exist or synthesizing new data.
The datasets you create through this process will improve your machine learning models by reducing the risk of overfitting. It is most popular for machine learning models that involve text or image classification since these are areas where collecting data may be difficult. The labeling process can also require plenty of manual work. Data augmentation allows you to artificially expand data sets to solve this scarcity issue by leveraging the limited, labeled dataset you already have.
An Example of Data Augmentation
Looking at an example of how it works is the easiest way to understand data augmentation.
Heuristic data augmentation is popular for working with models that will be classifying images. The process relies on simple transformation functions, where you rotate or flip the images you already have.

For instance, if you have an image of a car in your data set, you can rotate it, invert it, or flip it to create a new data point that can be used to train the model. In other words, not only will the model learn how to classify a car when the image comes through from left to right, but it should also learn to recognize it upside down or right to left.
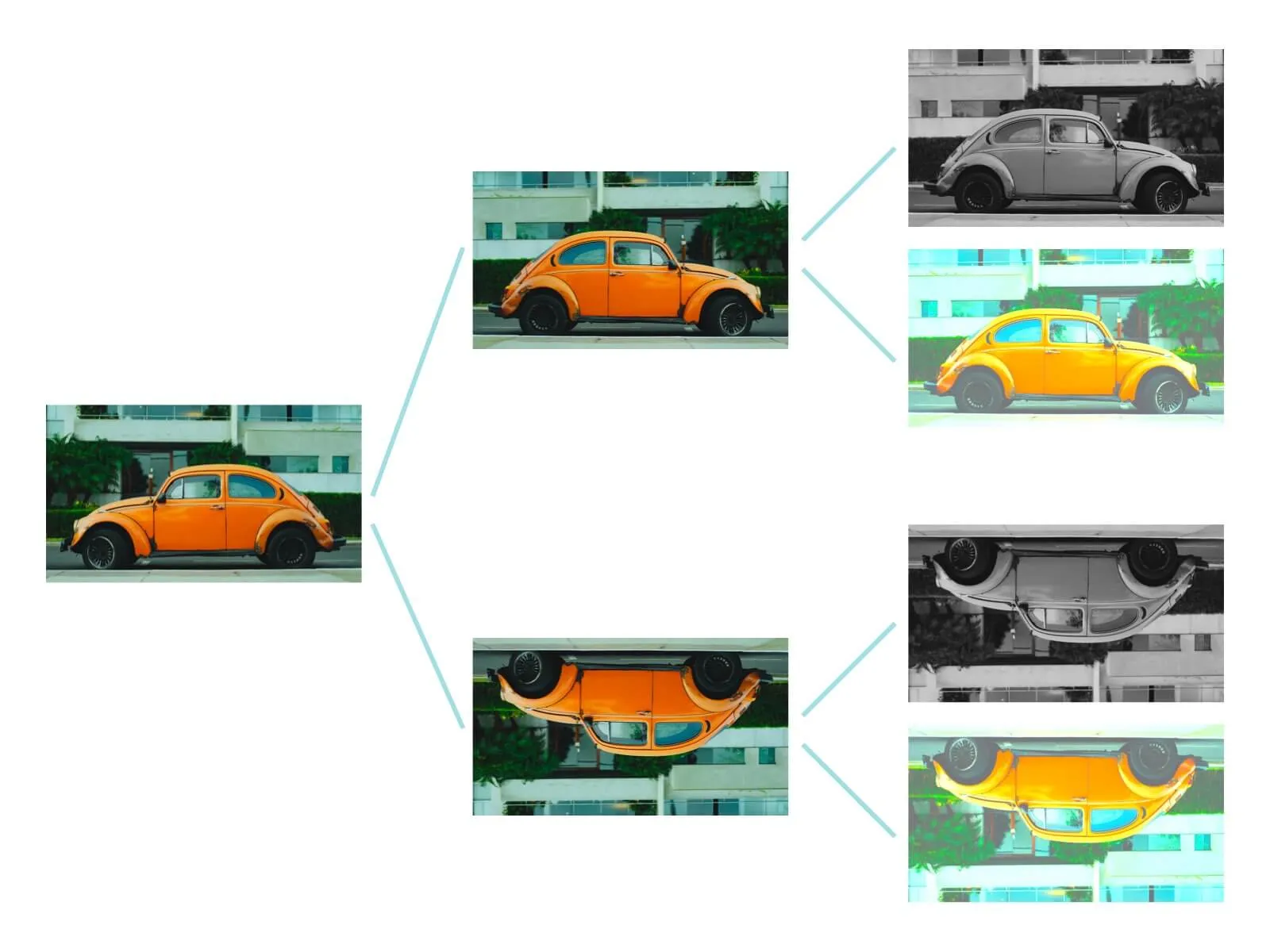
Another way to augment these images is to fade the colors or crop portions of the image. If your machine learning model can still accurately classify images that are cut in half or missing standard colors, then you are increasing its usefulness and reliability.
How Can Data Augmentation Help?
The benefit of data augmentation generally comes down to reducing overfitting. For example, a classification model trained on three images will be limited to recognizing and classifying those exact images. Even adding slight variations to data will improve the generalizability.
The two areas where data augmentation is beneficial are:
###When you have a small data set
Most machine learning projects tend to start with a smaller set of data than would be ideal. Simply put, the accuracy of your predictions relies on the amount of data you trained the model on. Data augmentation can help you expand your data set and ensure that you provide enough training to develop a reliable and successful AI tool.
###When you can’t control the input data
Generally speaking, training data sets tend to be relatively pristine, but real-world data is the opposite. What happens when you can control the data fed into the algorithm? Without data augmentation, your model will not be as accurate. For example, it won’t be able to account for grainy images or typos in text fields. When you use data augmentation, though, you can present the model with real-world scenarios that are less than perfect. This will allow it to learn how to adapt to unanticipated changes in the data or flawed inputs.
AugLy, a Data Augmentation Library from Facebook
Facebook recently launched a new library, AugLy, designed to help AI researchers with data augmentation. The open-source library contains data augmentation resources for everything from images and text to video and audio. In addition, AugLy allows you to tap into more than 100 data augmentations based on real-world examples from sites such as Facebook and Instagram.
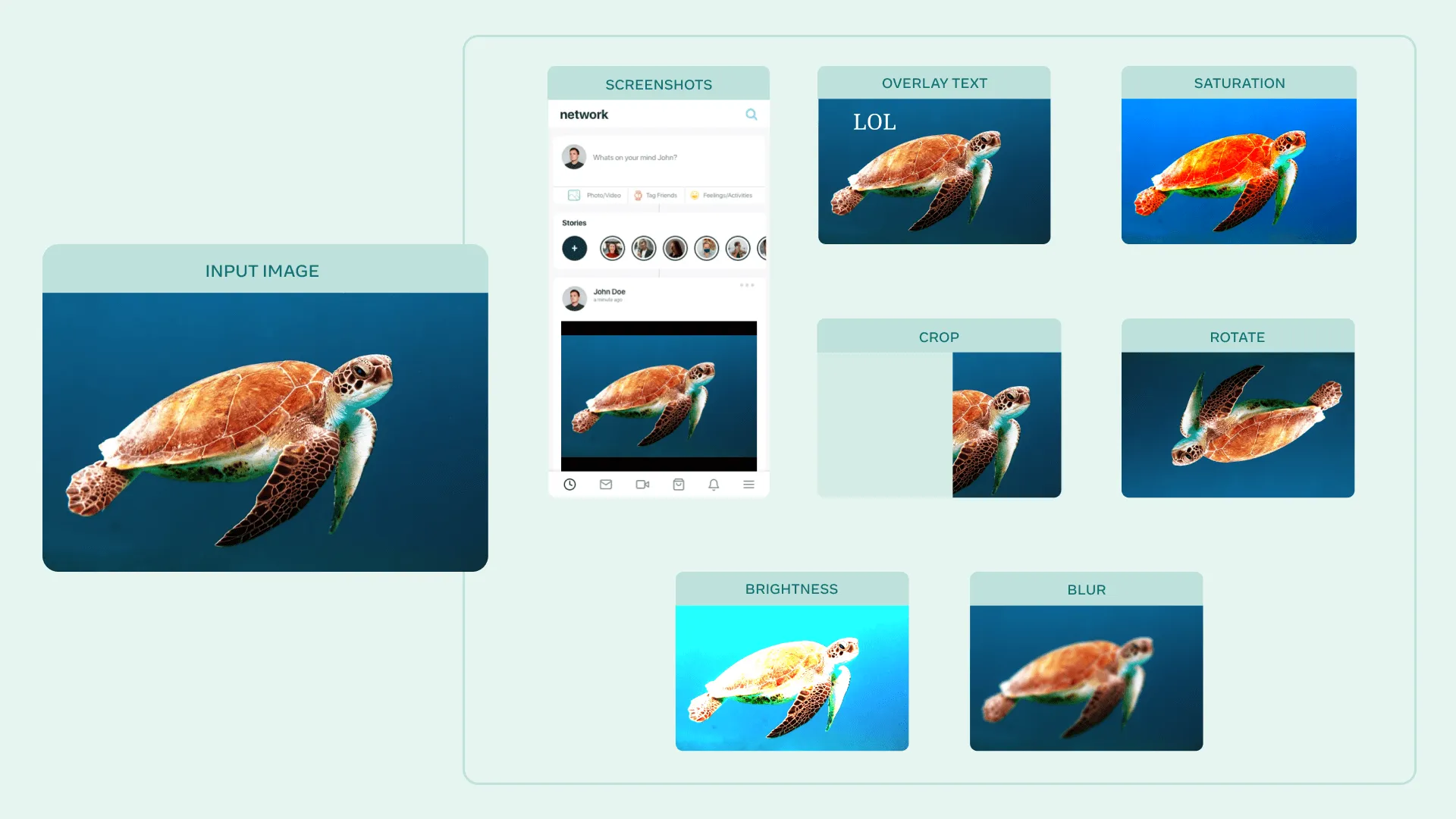
A library such as AugLy can easily be integrated into a data preparation pipeline within Valohai, and the augmented data can be used in model training pipelines.