
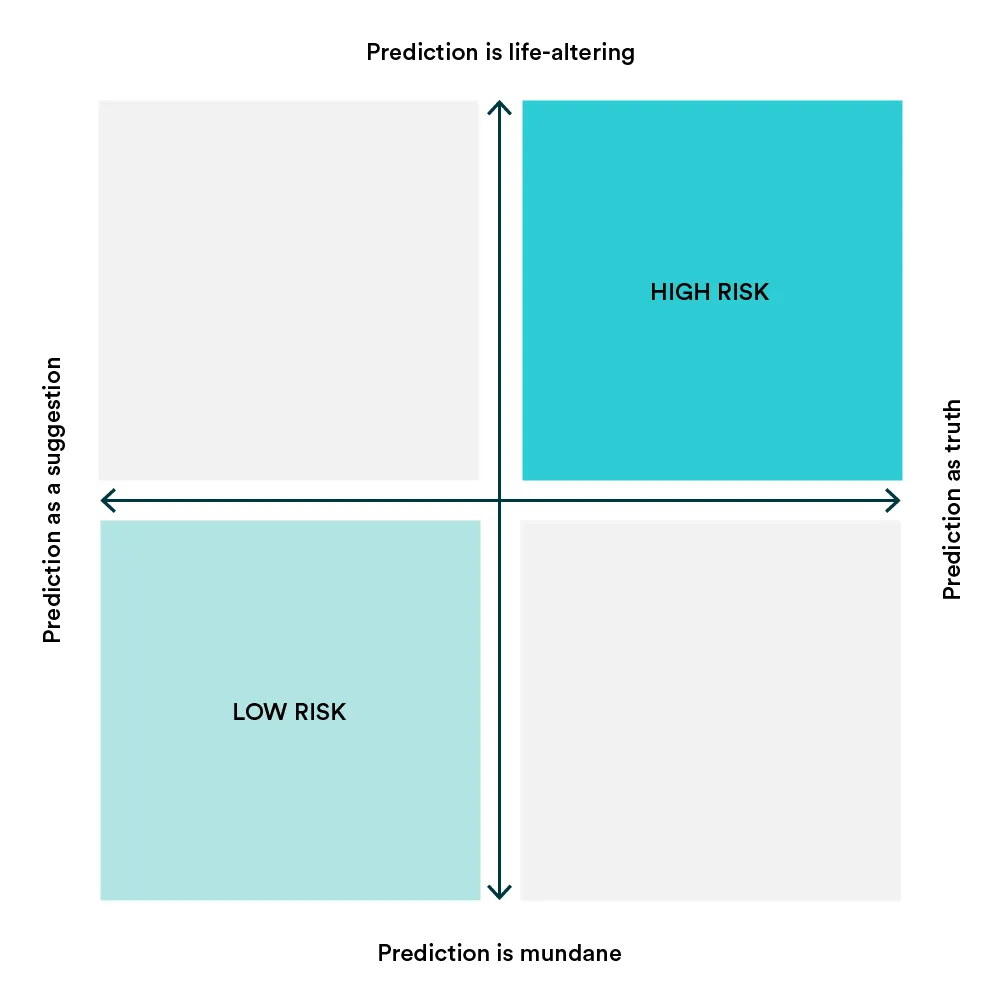
Every business and act on this earth includes risks and so does Machine Learning or, more broadly speaking, AI. However, AI risk isn’t often handled by your company’s traditional risk management for several reasons.
First, algorithms are usually based on proprietary data, and models and techniques are developed in the domain sphere of the particular (business) problem. Second, algorithms can be complex, unpredictable, and challenging to explain. Finally, the ML scene is relatively new, and thus, we also lack best practices and regulation is lagging.
We need to minimize the risk by addressing how we develop these algorithms and also how we apply these algorithms in the real world.
In this article, I’ll focus on the latter part. In other words, I’ll look at the outputs and how they are used since there is a lot of literature on data-centric AI and how to make sure your models are explainable. Unfortunately, the application of predictions isn’t always as close to data scientists as it should be.
How should you go about mitigating your output risk? The first step is to consider whether you need machine learning. A business rule programmed by a human will be less risky and more explainable than an ML solution. If that’s not possible, consider the least complex data science solutions, such as traditional, explainable (and boring 🥱) logistic regression.
Boring is good; boring is reliable. But if you can’t solve your business problem with boring, continue the ML route with the advice below.
1. Serve predictions as suggestions
An excellent way to start is to acknowledge and embrace predictions’ nature and uncertainty. Rather than presenting predictions as the truth, serve the outputs as suggestions or alternatives. For example, when navigating with Google Maps, you can pick between a few suggested routes or just follow your own logic. On Netflix, you can select the show recommended or just browse for something else. It seems self-evident, but we are often overly confident in the algorithms we create.
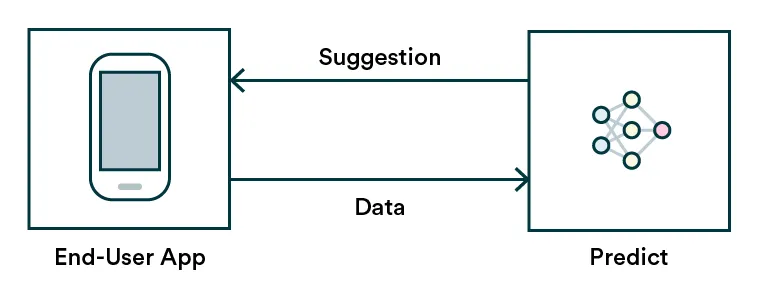
An example of this pattern is chatbots. They usually use suggestive language, not telling you exactly what you should be doing. Chatbot applications also let the customer interacting with it know explicitly that this is a chatbot and can make mistakes.
2. Predict in batches
If your problem-solution combo allows, one easy way to mitigate risk is to predict in batches instead of immediately posting the predictions. In batches, you can be sure of the distribution of the data you are using to make predictions and find unintentional anomalies and errors in input data before causing funky outputs. In addition, you can check the prediction output distribution for outliers and odd behavior too before using them in action.
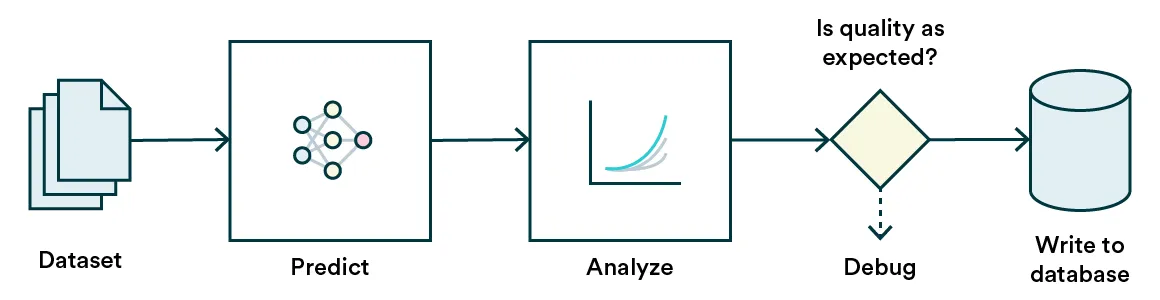
A practical example of this pattern would be business intelligence-related models such as churn prediction. The user is not expecting these predictions to update in real-time because the status of a client doesn’t change quite that rapidly. Updating these, for example, daily will allow you to check for radical changes in data (like a schema change) that might suddenly cause your model to predict every client to churn and cause panic in your business folks.
Psst! Batch prediction distributions can easily be monitored.
3. Keep humans in the loop
Before having enough data on all the possible scenarios, you might want to get a human involved in the process when your ability to predict on a certain confidence level fails.
One would introduce an extra step to the prediction process where it checks automatically, e.g., was the input data in the known domain, was the prediction within the bounds of known, or what was the prediction power, if available. If not passed, the automatic process would not go further, and a human takes over.
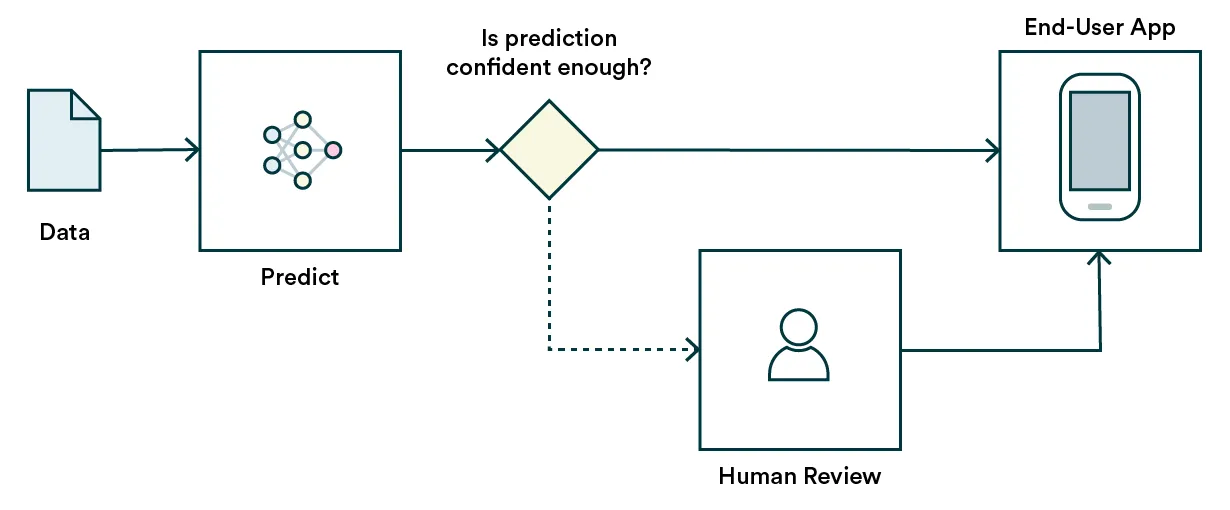
This pattern is vital for high-impact use cases such as financial and health predictions, where serving an incorrect prediction to the end-user can cause immense stress or worse. For example, if you work at a car insurance company where hundreds of window crack claims are processed every day, automatic fraud detection may be reasonable to enforce. Still, when your model is uncertain, it should be an obvious choice to spare the claimant a scare before a human operator looks through the claim.
Closing the case
As machine learning is adopted more in human-centric domains, we need to keep in mind that a single mistake by humans can be repeated millions of times by an algorithm. And as we all know, we need to be extra careful with the application having human-life-altering effects, such as who gets a loan or who gets what cancer treatment.