
A trend we’ve been tracking for several years now is how the data science profession has steered away from being entirely independent, do-it-all unicorns into a more specialized work. It’s by no means that individuals with deep knowledge in several domains have disappeared, but rather, the need for data science has grown, and teams have increased in headcount. In larger groups and overall in a more active job market, there’s more room for specialization.
It’s not just that there are more cooks in the kitchen, but also machine learning solutions are much more ambitious in scope.
It’s becoming more important to think about the competencies of a team rather than expecting every individual to be an expert at everything related to machine learning. This is very similar to software engineering roles diverging into backend, front-end, and DevOps engineers.
The Three Main Roles in a Machine Learning Team
Machine learning systems tend to have the following three different types of contributors:
-
Data Engineer
-
Data Scientist
-
ML Engineer
Each of them focuses on a different part of the machine learning system. Naturally, there is overlap between each role, and we can identify a few critical parts of the system where these roles tend to collaborate the most.
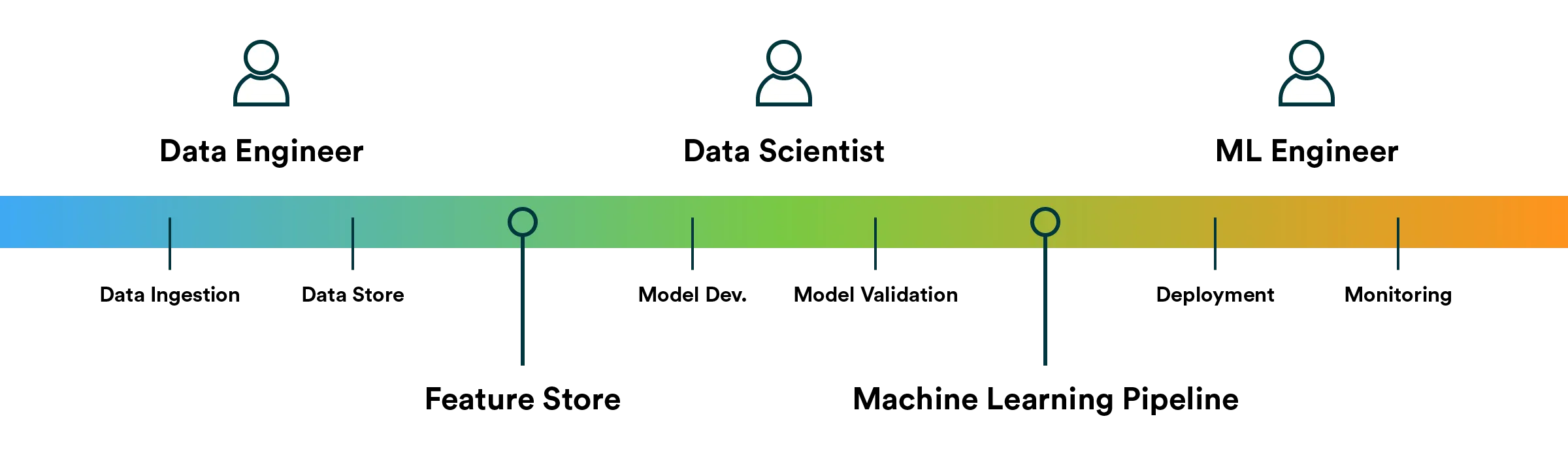
Data Engineer
Data is the foundation of machine learning, but data became a hot topic before machine learning had its relatively recent resurgence. Data engineers have been tasked with building data infrastructure for various other applications, such as business intelligence, for years, and it’s rather evident that their competencies would be needed for the adoption of machine learning.
So what does it mean that they build data infrastructure? In simple terms, they create systems that ingest, store, transform and distribute data. Exact terms depend entirely on what type of use case and data they are dealing with, for example, whether a data warehouse or a data lake is the right solution.
Data engineers interface with data scientists around issues of data. The most common topic would likely be the availability of it. A data scientist will need to have access to data to experiment and train a model, and the data engineer is there to facilitate that.
Feature stores: the intersection of data engineering and data science
More recently, feature stores have emerged as a solution between data engineering and data science. Feature stores consolidate data for machine learning into a single place and allow data scientists to define data transformations that distill information to highly valuable signals for the ML model (i.e., features). From the feature store, features can be delivered to the training pipeline and production without interruptions.
Data Scientist
Data scientists are tasked with finding data-driven solutions to business problems. For example, they might be looking at user data to find meaningful user segments and building models that can classify those users into segments to differentiate the end-user experience and drive more engagement.
While the primary purpose of a data scientist is to explore data and build models, cleaning and wrangling data tends to be the most time-consuming part of their workflow. This is why the feature store is emerging as a significant part of end-to-end ML infrastructure.
Data scientists’ primary focus is on building the machine learning algorithm. However, there is often quite a lot of distance between the scientist’s environment and the final destination — the production environment.
Many teams have adopted the role of machine learning engineers for the individuals who facilitate productionalizing the ML model.
Machine learning pipeline: the intersection of data science and machine learning engineering
The production environment is unlike the research environment. The models in production will need to perform even when the underlying world changes and data drift emerges. Many teams have realized that models will need to be retrained repeatedly with the same rigorous discipline as the first time around.
The machine learning pipeline is the intersection of data science and ML engineering, where the process of training and testing a model has been codified. The pipeline can then be run as frequently as needed. Collaborating on a pipeline is preferable to a handover between data science and engineering because it ensures that all the original intent and knowledge is carried over to production.
Machine Learning Engineer
Technologies that enable machine learning to be trained and served on the cloud (such as Kubernetes) are often not part of data scientists’ core competencies.
Therefore, machine learning engineers have emerged as the productization specialists for ML. To roughly characterize the workflow, data scientists build and validate the model while engineers ensure it scales from a model to a production system.
However, as with data engineering, thinking has shifted towards platforms where the objective is more towards building a shared system where engineers and scientists collaborate rather than handovers. While data engineers are responsible for the data management platform (or feature store), ML engineers take care of the MLOps platform that includes components to train, version, and serve models.
Additionally, ML engineers figure out how to monitor a production model to ensure that the served predictions are of expected quality and the service itself is available at all times. Monitoring also often ties back to the feature store and data engineering because what matters is whether the underlying data has changed from when the model was last trained.
How Do They Work Together?
Roles diverging offers the promise of individuals being able to specialize and therefore be more productive. Additionally, the promise for organizations is the ability to scale from one person per business problem to one team per business problem.
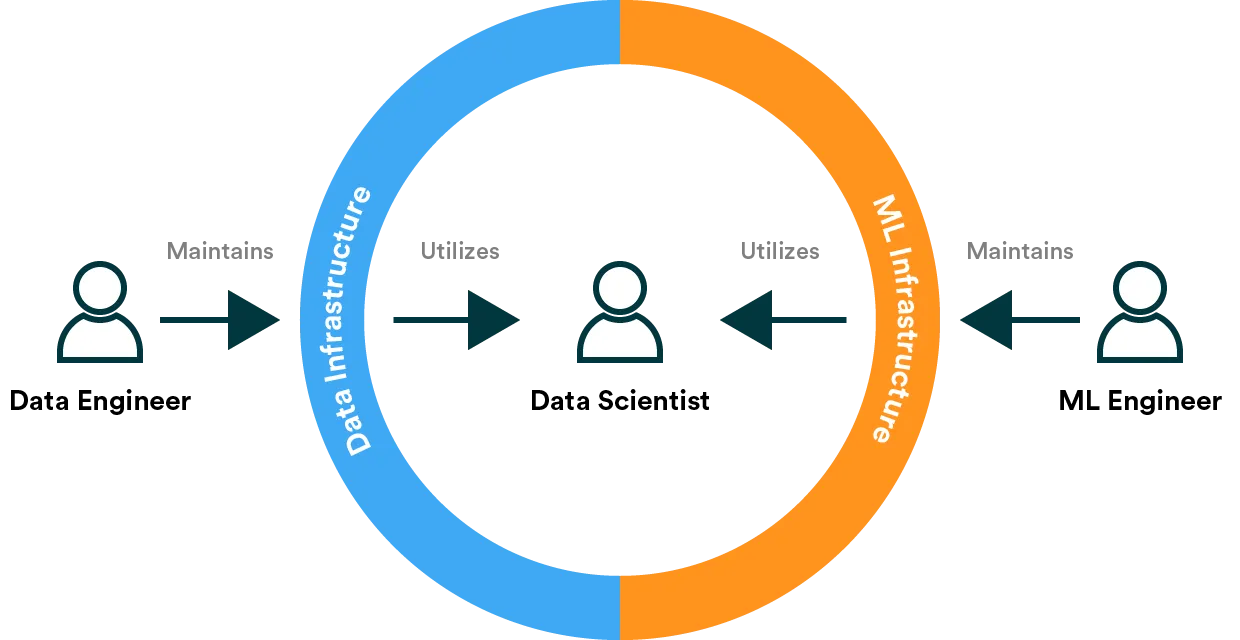
However, teams have to adopt a platform approach rather than siloing each role separately to fulfill these promises. Adopting processes and technologies (often categorized under MLOps) that allow experts in different positions to collaborate and build production machine learning systems together is paramount.