AI is having its Cambrian explosion moment (although perhaps not its first), led by the recent developments in large language models and their popularization. OpenAI’s ChatGPT has opened the public’s imagination on what kind of problem-solving AI can do, while OpenAI’s APIs have given app developers the ability to build on top of their state-of-art models. This mass popularization on both levels already shows rapid innovation akin to the early days of iOS and Android apps.
LLMs are magic until they aren’t
As a product person, LLMs add two superpowers to my toolbelt: the ability to make sense of a fuzzy task and to generate a humanlike text response. And best yet, I don’t need to come prepared with a vast data library. Together, these powers open up countless ways that apps can solve a problem for the user and how it can be presented.
Veterans in the NLP space are anxious about how suddenly every problem is an LLM problem. This meme sums it up nicely.
In the short-term, state-of-art large language models delivered through APIs (like OpenAI’s GPT-3) are an incredible leap for teams building the first iteration of an AI product. While we’re still in the honeymoon phase, folks deep in it are already starting to discover where the limitations lie.
I’d break it down to:
-
LLMs are not the right solution for every problem. Some tasks are not fuzzy, and sometimes the response needs to be very specific (and accurate). So you’ll want to take a wider look at NLP as early as possible.
-
Relying only on Machine Learning as a Service makes it hard to build lasting competitive value and raises questions about data ownership. Creative prompt engineering can only take you so far, and you’ll want to look into taking full advantage of your proprietary data in fine-tuning.
LLM products will evolve over time
As mentioned, GPT-3 and the like will introduce plenty of newcomers to building products with ML-powered features. I’d like to speculate that many of these products will go through some variation of the following three stages.
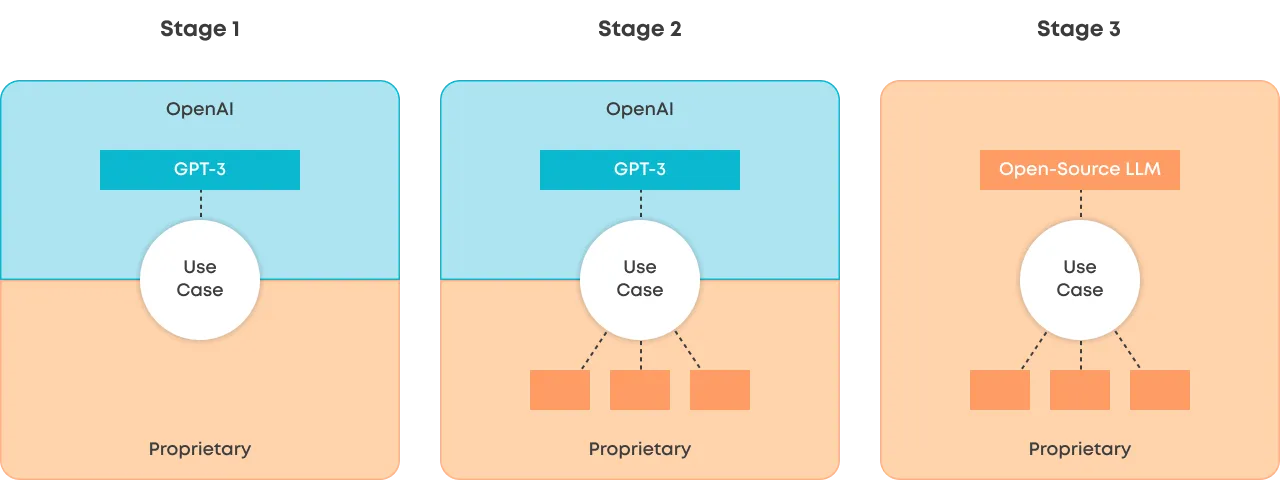
Stage 1 (The Thin Wrapper)
You build a UI that allows the user to invoke the LLM in a natural way. Then, add some creative prompt engineering behind the scenes, send it to the API and pass back the response (in some form) to the user. Boom, you’re off to a great start.
Stage 2
Over time, you find the LLM’s limitations, and your use cases requirements become clearer. Using other models together with LLMs can help solve those problems. For example, using Sentence Transformers and vector databases to search for relevant data to pass on to the LLM or using another model to summarize the inputs to overcome LLM’s token limits. It could also be using another model to change the output of the LLM.
The best part is that with the other models in the orchestra, you can train and retrain much more efficiently for your specific use case, with your data and in your infrastructure. So now you are building some unique IP on top of data that you own.
Stage 3
Today, OpenAI’s value is quite hard to beat (especially for new companies and products), but we’re bound to have better open-source LLMs (fingers crossed) and technologies that bring the cost of fine-tuning and inference down. For example, GPT-NeoXT is already gaining momentum in the Hugging Face community, but the landscape is changing daily.
Bringing the LLM capabilities to your environment won’t become relevant for all use cases, but arguably it will for most. In the long term, having more control over data and models is important for most business-critical applications.
Summary
It’s an exciting time in the ML space. With the popularization of large language models, developers and product folks are flocking to the space and testing out novel concepts. While NLP veterans might be slightly anxious about the “throw things at the wall and see what sticks” mentality, it’s important to remember that the things that stick (i.e. the use cases that prove value) will mature. They’ll go through many iterations of how the actual intelligence is provided to the product.
A worthwhile read on this topic is Diego Oppenheimer’s blog post: “DevTools for language models — predicting the future”.
Evaluating LLMs? Valohai LLM lets you compare models, prompts, and configs side by side with 3 lines of Python. Try it free →