
Running machine learning (ML) inference in Edge devices close to where the data is generated offers several important advantages over running inference remotely in the cloud. These include real-time processing, lower cost, the ability to work without connectivity and with increased privacy. However, today, implementing an end-to-end ML system for edge inference and continuous deployment of models in distributed edge devices can be cumbersome and significantly more difficult than for centralized environments.
As with any real-life production ML system, the end goal is a continuous loop that iterates and deploys the model repeatedly.
This blog post describes and shows a real-life example of how we created a complete ML system that continuously improves itself using Valohai MLOps platform, JFrog Artifactory repository manager and JFrog Connect IoT Edge device management platform.
Real Use Case: Construction Site Safety Application
For our use case example, we’ve selected a practical application highlighting the edge inference’s advantages: Worksite safety monitoring.
Most regulations demand that everyone on a construction site uses the required safety equipment, such as hard hats. It is important for worksite managers, because failure to comply with safety regulations may lead to increased injuries, higher insurance rates and even penalties and fines.

To monitor the sites, we set up smart cameras based on Raspberry Pi 4 devices running an object detection ML model, which can identify whether people captured are wearing a hard hat or not.
The benefits of edge inference are evident in a use case like this. Construction sites often have unreliable connections, and detection must be done in near real-time. Running the model on smart cameras on-site instead of upstream in the cloud, ensures uptime, minimizes connectivity issues or requirements, while addressing possible privacy and compliance concerns.
The following describes the details of how we implemented this solution.
Solution Overview: Continuous ML Training Pipeline
Our continuous training pipeline setup for edge devices consists of two main elements:
-
The Valohai MLOps platform responsible for training and re-training the model, and
-
The JFrog Artifactory and JFrog Connect responsible for deployment of the model to smart cameras at the construction sites.
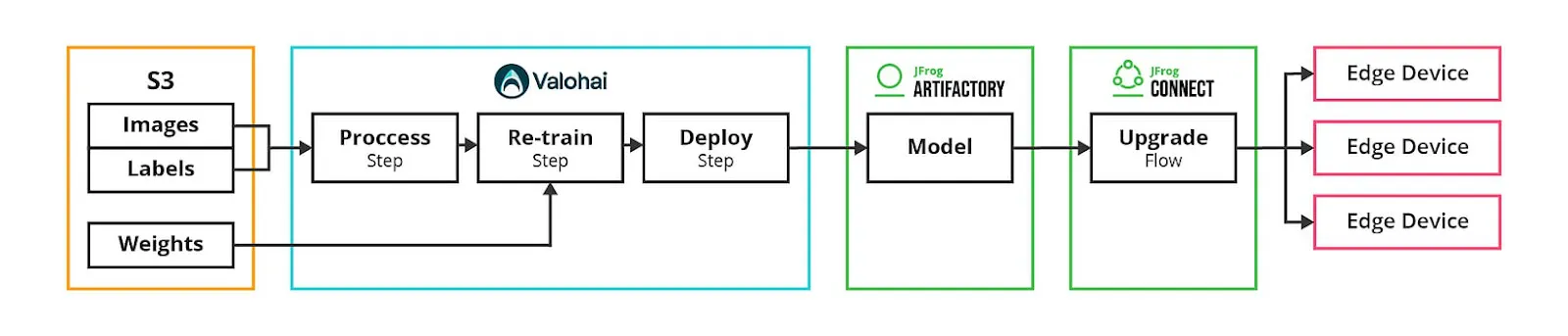
Solution Components
| Layer | Products | Function |
|---|---|---|
| Data Store | AWS S3 | Store training data (images & labels) Store model weights |
| MLOps Platform | Valohai | Integrate with S3 & Git Orchestrate training on GPU instances Package model for inference Collect new training data back from the fleet |
| Artifact Repository | JFrog Artifactory | Store and manage life-cycle of model’s packages Serve download requests from Edge devices |
| Device Manager | JFrog Connect | Manage, monitor and troubleshoot edge device fleet Deploy and install model to the fleet’s devices |
| Edge Device(s) | Raspberry Pi 4 | Run model inference |
Training and Deploying the Model
In the Valohai MLOps platform, we defined a typical deep training pipeline with three steps:
- Pre-process
- Train
- Deploy
The pre-process and training steps are what you would expect from a deep learning machine vision pipeline. We mainly resize the images in the pre-processing, and the training step re-trains a YOLOv5s model using powerful GPU cloud instances.
The more interesting step is the deployment step, where we integrate Valohai platform with the JFrog DevOps Platform. The valohai.yaml is a configuration file that defines the individual steps and the pipelines connecting these steps. Below is our example deployment-jfrog step defined in YAML.
Code snippet: valohai.yaml
- step:
name: deployment-jfrog
image: python:3.9
command:
- cp /valohai/inputs/model/weights.pt /valohai/repository/model/yolov5s.pt
- zip -r /tmp/model.zip /valohai/repository/model
- curl >
-H "X-JFrog-Art-Api:$JFROG_API_KEY" >
-T /tmp/model.zip "$JFROG_REPOSITORY/model.zip"
- python jfrog-connect.py >
--flow_id=f-c4e4-0733 >
--app_name=default_app >
--project=valohaitest >
--group=Production
inputs:
- name: model
default: datum://017f799a-dc58-ea83-bd7f-c977798f3b26
optional: false
environment-variables:
- name: JFROG_REPOSITORY
optional: true
- name: JFROG_API_KEY
optional: trueLet’s see how the deployment step works.
First, the deployment step builds a zip archive containing the model + weights and then uploads it to JFrog Artifactory. Valohai provides the step with the weights from the previous training step as an input file and the required JFROG_API_KEY and JFROG_REPOSITORY secrets as environment variables.
The next step starts an update flow that delivers the new model across the fleet of smart cameras, using a call to JFrog Connect API.
We’ve set up a Valohai pipeline that uploads the model to JFrog Artifactory and triggers deployment of the model in the JFrog Connect service, which delivers the new model across the smart camera fleet.
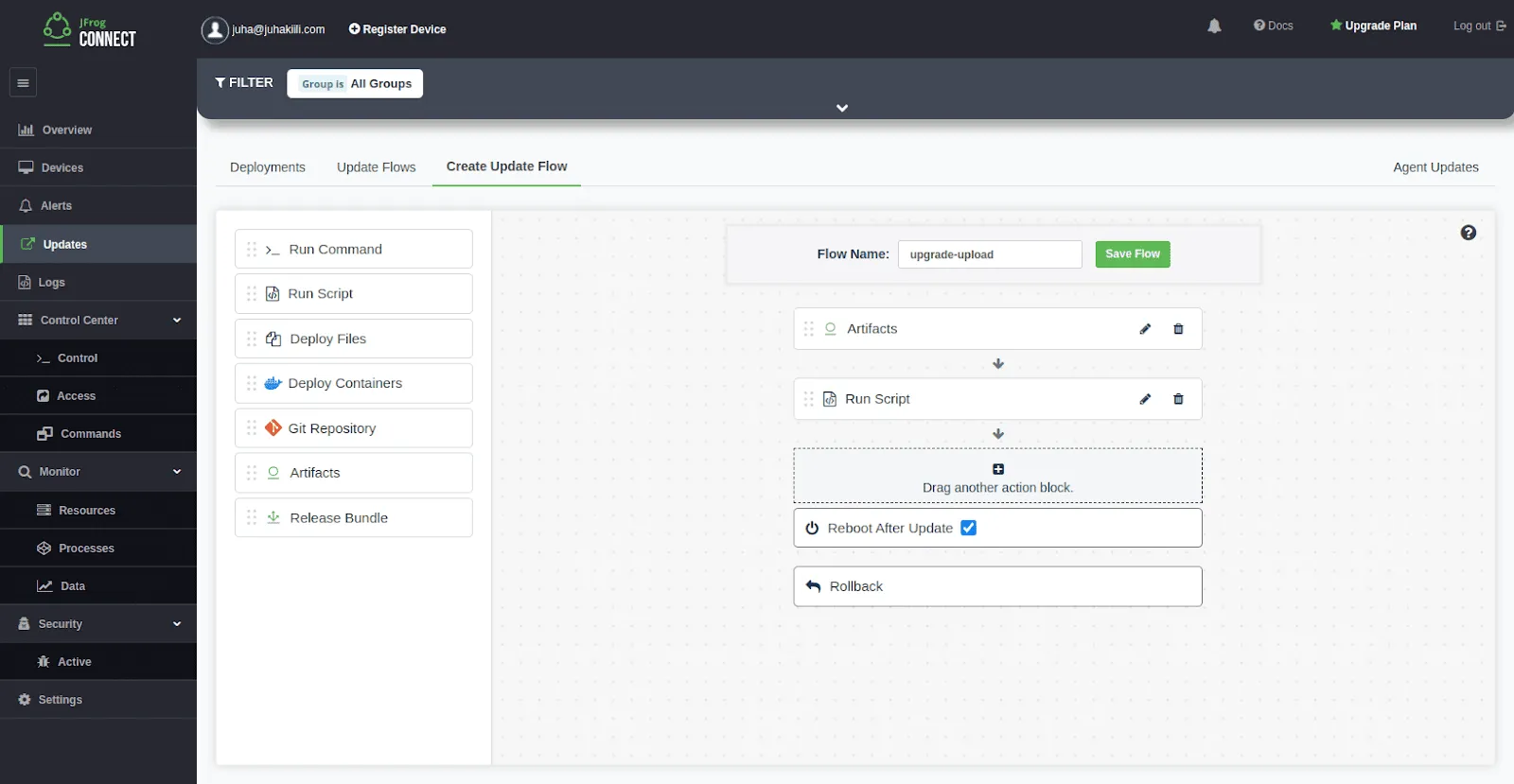
The model deployment process is represented as a JFrog Connect Update Flow. An Update Flow is a sequence of actions that needs to take place in the edge device. Using the JFrog Connect’s drag-n-drop interface we created an Update Flow that includes the steps needed to update the model in the smart camera. These steps are:
- Downloading the model from JFrog Artifactory,
- Running a script to install the model, and
- Rebooting the device.
If one of the steps fails, JFrog Connect will roll back the device to its previous state, so the device always ends in a known state. Learn more about JFrog Connect Update Flows.
Continuous Training
Our work is not done once the model is deployed across the entire edge device fleet. The cameras are collecting potential training data 24/7 and encountering interesting edge cases.
At this stage we need to create a pipeline that collects labeled images from the fleet of smart cameras every week and uploads them into an S3 bucket to be manually re-labeled and eventually used in re-training the model.
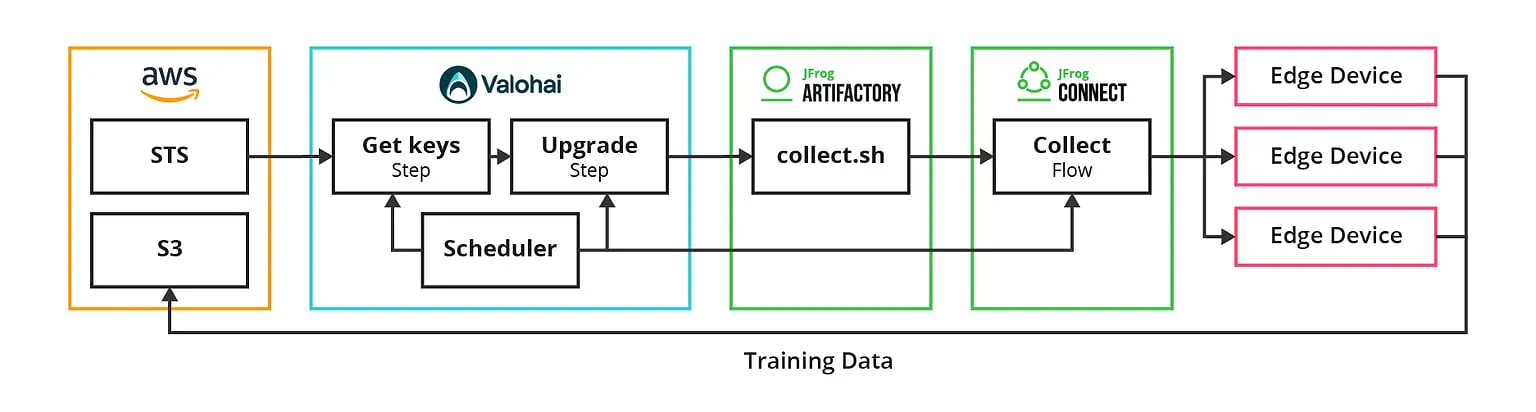
How the scheduled pipeline works:
- Create temporary credentials using AWS STS with write-only access to the S3 bucket
- Upgrade the upload script in JFrog Artifactory with temporary keys baked in
- Trigger JFrog Connect Update Flow to run the upload script across the device fleet
- Each device uploads a batch of new images into the S3 bucket
The new training data uploaded by the device fleet is manually labeled by humans using a platform like Sama or Labelbox, which use our upload S3 bucket as its source and another S3 bucket as the target once the data is labeled.
Note: A massive fleet generates too much data for manual labeling, and the devices themselves may run out of space quickly. Luckily, machine vision models like YOLOv5 usually have a confidence metric and the predicted labels. We filter the stored training data on the device with a confidence threshold that prioritizes the edge cases.
Conclusion
In summary, we showed how to create a continuous loop that iterates and deploys an ML model repeatedly in production across a fleet of edge devices. The Valohai MLOps platform, combined with the JFrog DevOps Platform’s Artifactory and Connect, allowed us to achieve this and create an ML system that continuously improves itself.
Ready to try it out for yourself? Start for free or book a demo of the Valohai MLOps Platform and JFrog Connect to continuously train and deploy your ML models in edge devices!
Originally published at
JFrog Blog
.