
Some time ago our product lead Juha Kiili spoke at the Model Serving Event organized by AI Infrastructure Alliance about how batch inference compares to the online and which one is a better fit for the project. In this article, we have summed up the key takeouts from his presentation hoping to spread more awareness about the benefits of doing the delayed inference whenever possible. But first, the warm-up round with terminology updates.
Revisiting terminology
There is an established convention about naming for different types of inference and those are quite straightforward. Batch inference is for the delivery of value in batches, e.g. once per day. Online inference is for the on-demand delivery, just like a pizza being delivered per your order in a food delivery service.
However, we suggest naming things differently. What you know as a batch inference we call delayed inference. And both online and edge inference are real-time inference.

Why? Well, it makes more sense because it describes what happens during the implementation better. And everything you will read from this point onwards will prove the point.
The gray area
Most of the common machine learning use cases land in the spectrum between the two polarities of delayed and real-time inference.
On one end of the spectrum, we can find cases that can only be done as a delayed inference. For example, weather forecasts. These models are super-slow. Thus, it is unrealistic to expect them to be real-time because the simulation takes hours.
On the other end is the real-time inference and, for example, chatbots. They always need to be a real-time model. A chatbot that does not respond in seconds is useless.
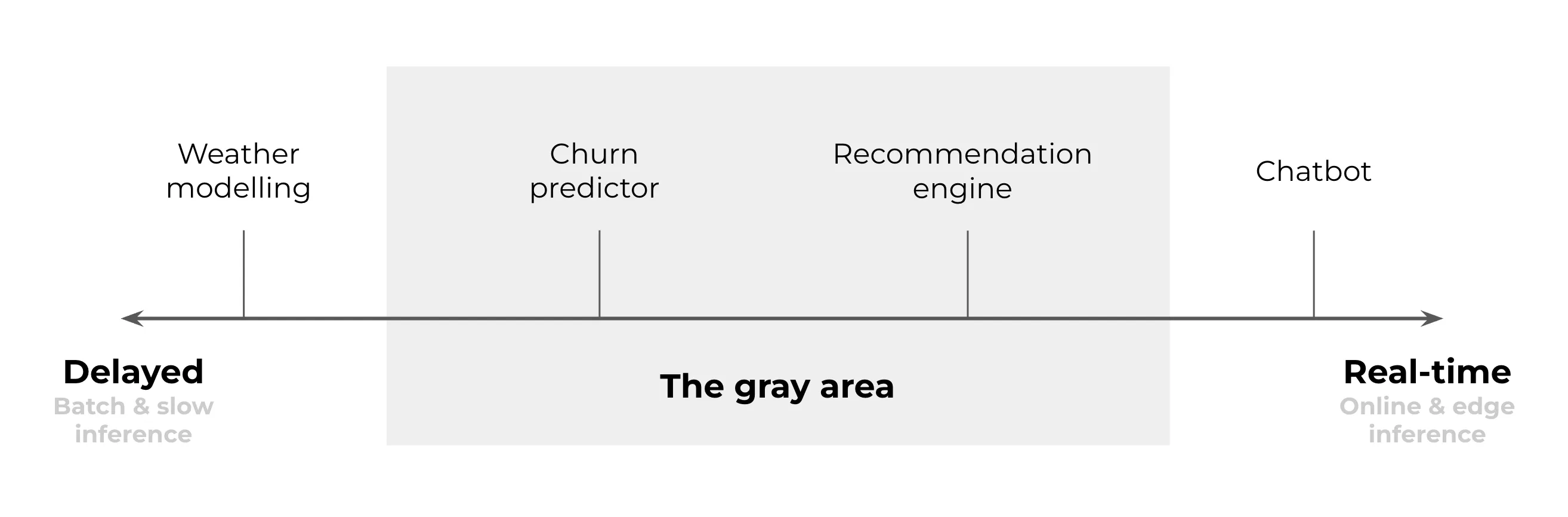
But a lot of cases stay in the gray area in the middle where both delayed and real-time options are possible. If you find your case to be in this area, you need to ask yourself which option you pick. Here are some things to know about each of them.
Implementation of different inference options
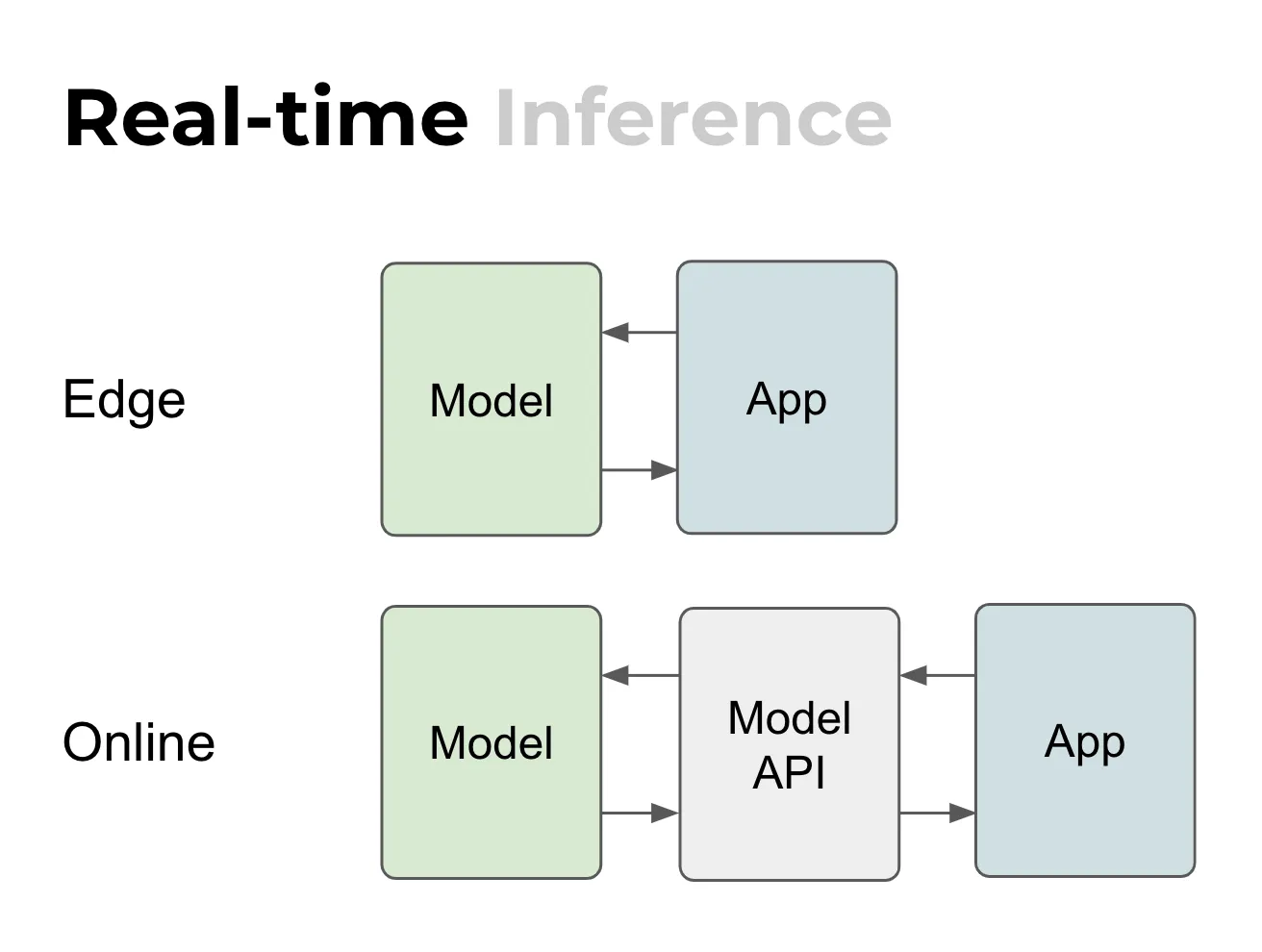
Edge vs. online
In edge, which means some IoT device or a mobile app, the mechanism of deployment is complex but the actual inference is quite simple. That is because the app and the model are local, they are in the same device, so it is very simple to do inference once you’ve got it deployed.
For online it’s a different story. There is a separation between the model and the app. So basically, you have the Internet in between. That means you often need some kind of API that is specific to the model. Then the model is served using some kind of a web server or a web service. Nevertheless, it is still quite straightforward: it’s a stateless web server, simple request and response. And that’s cool!
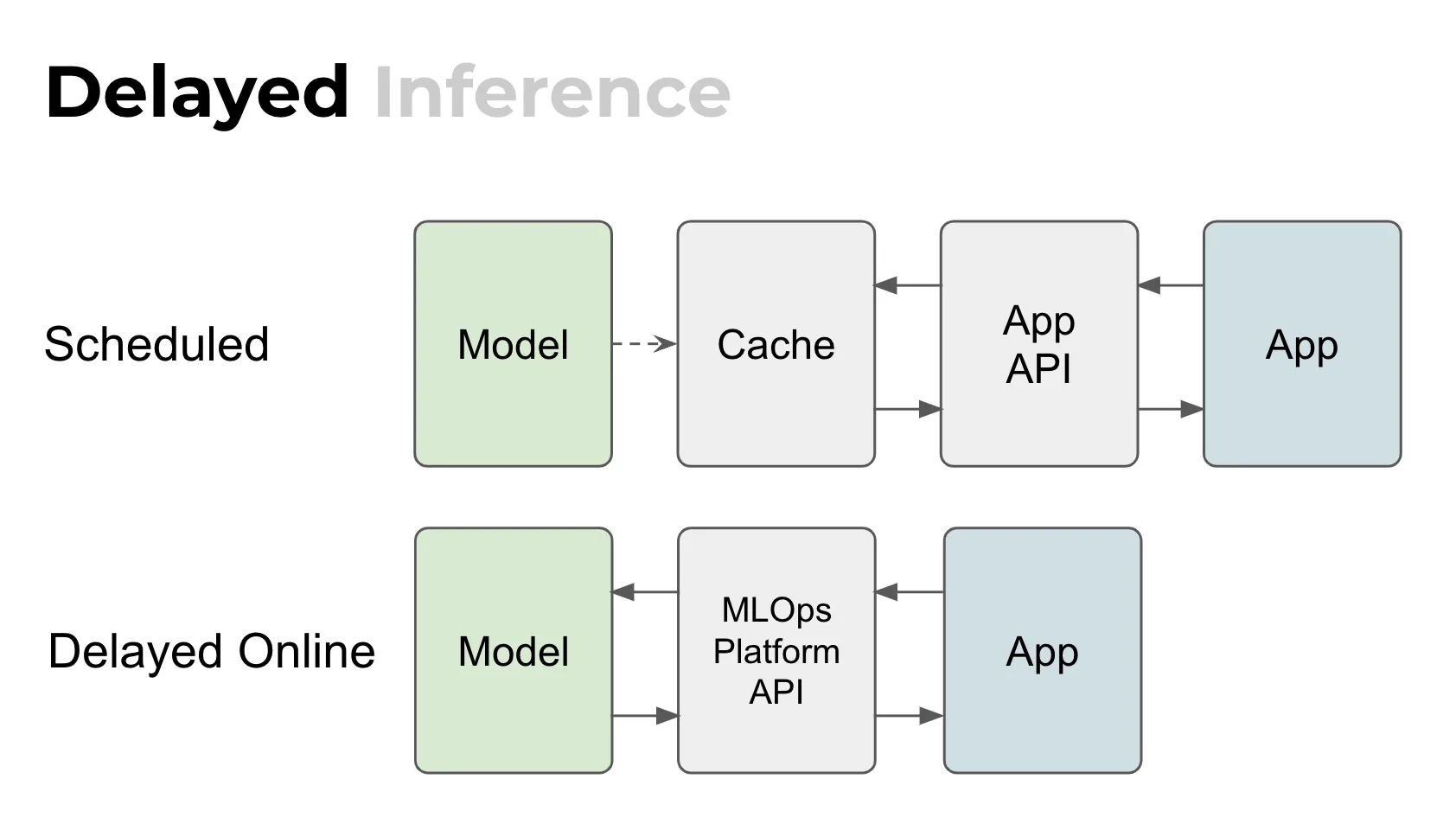
Scheduled vs. delayed online
For delayed assets, there are two ways to do inference.
There is a scheduled one where the model runs let’s say once per day or once per week. It fills the cache and the app is using the cache. It does not directly interact with the model.
But there is the other way, the delayed online way, which is not even a conventional technical term yet. Still, Valohai customers use this approach quite a lot. Here’s how it works.
If the model is quite slow or big, it is not realistic to do inference in real-time. But what if you still want to have this type of online API? What you do is you use the MLOps platform API and utilize it for doing the inference.
One good example is a CT scan since a medical image is huge in size. Just the upload could take too much time for it to be real-time. The actual pipeline can be quite complex. The app actually calls the MLOps platform API and triggers the inference. It can quarry the intermediate results or the final ones. It’s kind of like a hybrid between a real-time and batch.
This situation is quite common but it is not really discussed much. Maybe that is why it still doesn’t have a name.
Is real-time always better?
If you look at the benefits of real-time inference, what you get is the latest data, some kind of prediction right away, and it’s stateless. The request and response are pretty simple. This setup often entices people to think that real-time is always better, because of all these benefits.
However! At Valohai we believe that it is not always better and the default should be the delayed inference if you have such a choice. Let’s look at why it is a preferred option compared to real-time inference.
Delayed inference and all the good stuff
Solving production issues
Specifically for online inference, which is the most common way to do real-time, you always end up with a separation between your production and your development environments. This is particularly tricky with features when training and when doing inference. Can you use the same code for data transformation in production that you used when training the model? Will it meet the latency criteria? You might end up using slightly different features in development and production.
From Juha’s 20 years’ worth of experience it is clear that the setup where the development environment and production environment are separated, is going to cause a lot of pain: if one can’t trust the development environment to match the production, then what can be trusted really? This is a huge problem and a huge red flag.
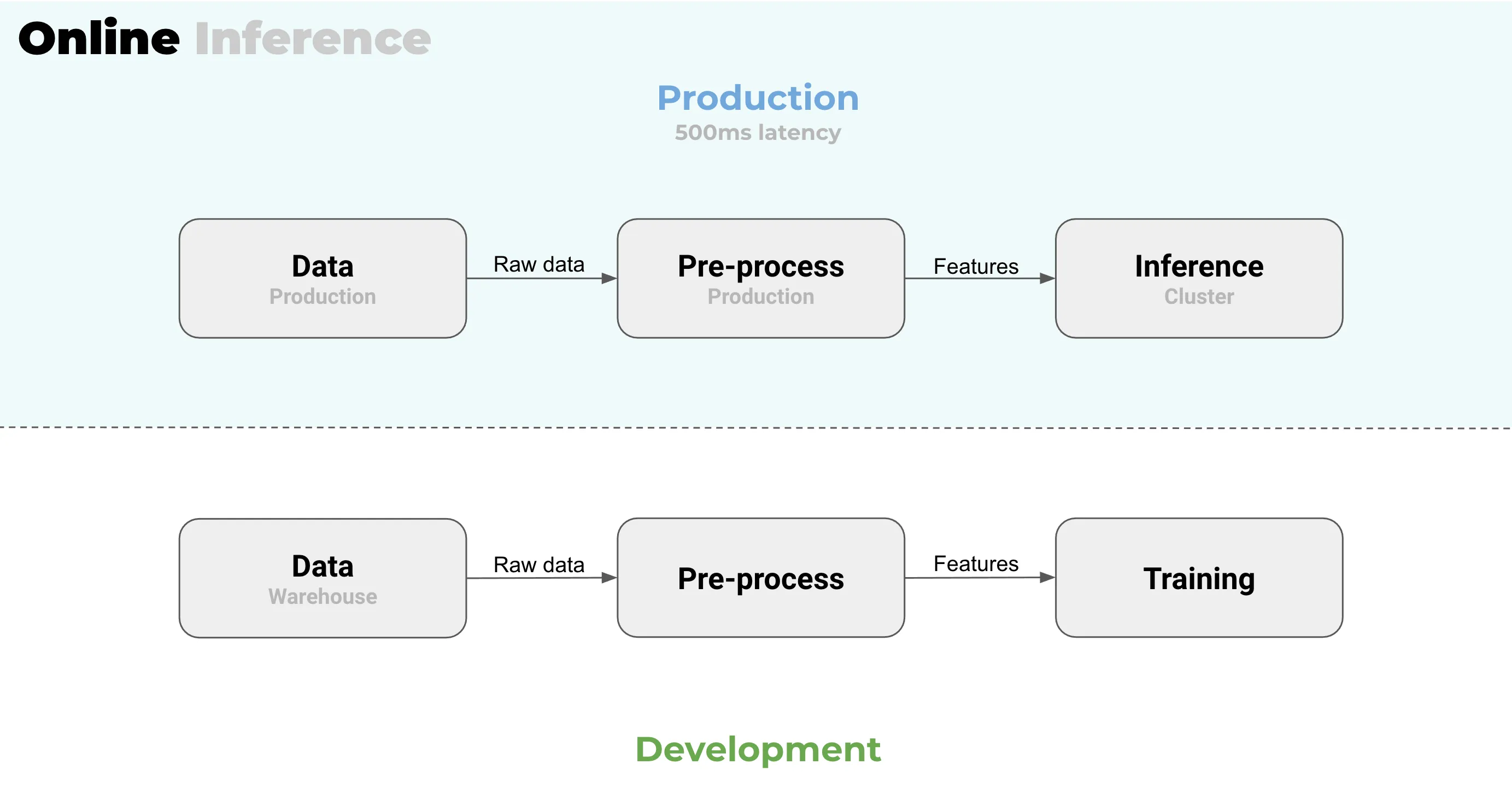
The modern fix for it is feature stores. They can be quite powerful for solving this problem but with a cost. So the actual question should be “Do we even need a real-time inference?” If you do not need the real-time inference, you do not need a feature store. One less system to set up and manage. Simple!
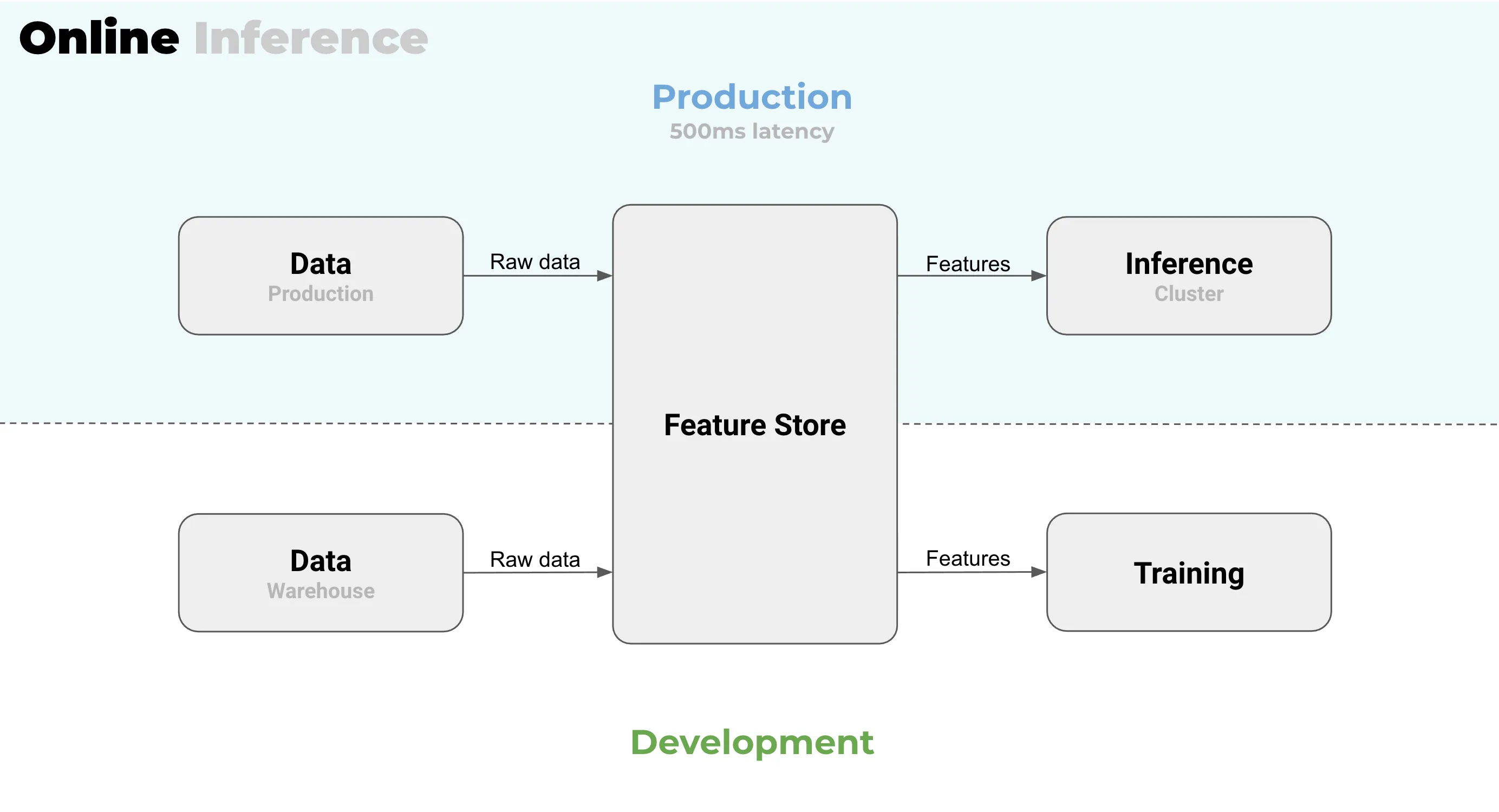
In delayed inference, your production and development environments are one and the same. At Valohai we call this “build in production” - the same infrastructure and the same platform that you used for training can be used for your inference. And that is really powerful.
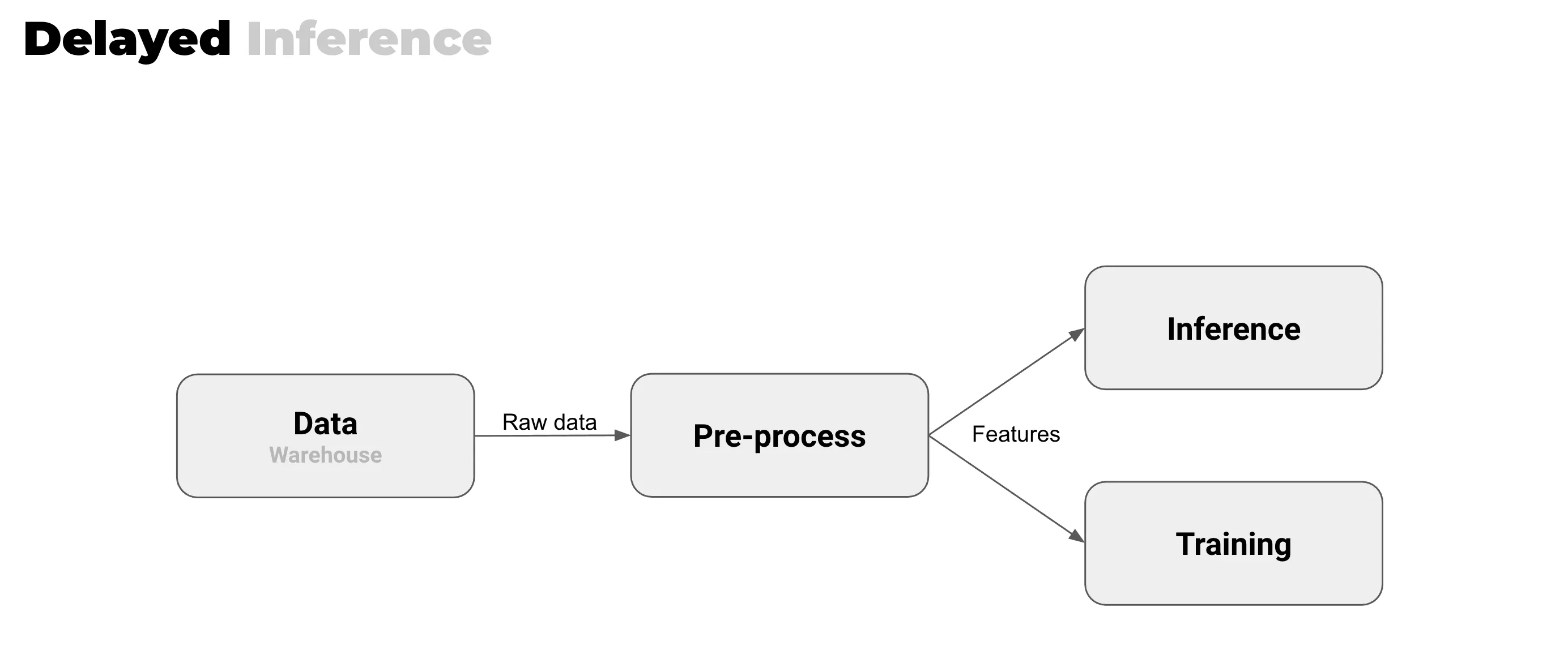
Avoiding model size and latency problems
If you’re doing delayed inference, your model can be anything, and you do not need to optimize it for your production. On the other hand, if you want your model to be a real-time one, then you have to meet all of the latency requirements. You always need to build a different image for production, be aware of the memory requirements, etc.
Minimum viable product available right away
We think that no one should do their inference production on a laptop even though it is possible. If you’re doing the delayed inference you can use whatever infrastructure you used for training for production as well. Whereas for real-time you always need to set up some sort of a web service or a server.
Easy deployment mechanism
The deployment mechanism for the real-time is mostly complicated. You need to build some kind of image and you need to deploy it to a cluster. Then you need to have shadow deployments, canary deployments, or all those fancy shimmy things.
But for delayed inference, it can be as simple as tagging your model to be your current production model. Next time your batch pipeline runs, you’re gonna use that new tagged model instead of the previous one. There’s a lot more simplicity in the batch approach: you tag it and that’s it.
Easy monitoring with a margin for errors
To put it shortly, in delayed inference fires are delayed. But for real-time, the fires also ignite in real-time and you need to react right away.
Monitoring a real-time model is an entirely different story: it’s 24/7 standby for alerts. You will get alert fatigue really quickly. However, if your pipeline is scheduled, let’s say once per week, you are not going to worry about it too much. It runs and you get the logs. If there’s an error, you have time to fix it, so there is no stress.
In the same way, if you mess up your batch pipeline, in a way it is still fine. You can fix it and no one will ever know. But if you mess up your real-time inference, the problems are immediate and the pain is immediate.
Conclusions: suffer well
Suppose you find your projects to be in the gray area between the extremes of delayed and real-time inference where you can go with either one, ask yourself if you can delay. And if you can, you should! There’re still errors and pains to deal with, but you have more leeway for maneuvering and peace of mind as a bonus.
Not sure if this is the right choice for you? Talk to us and we will help you figure it out.