
Collecting, cleaning and labeling data is one of the most time-consuming problems in data science and this is especially true in NLP. Recently, we’ve seen data scientists utilize large language models such as OpenAI’s GPT-4 to help produce datasets to train smaller NLP models that solve a more specific task, such as text classification.

Here are a few examples of how OpenAI’s APIs could be used in existing ML pipelines:
-
Data labeling: You can prompt the GPT model to categorize product reviews into positive, neutral and negative to generate a labeled dataset for a classifier.
-
Data augmentation: You can prompt the GPT model to provide alternative ways to phrase a sentence to add your sample size. This paper (ChatAug) describes using this method, for example to generate alternative descriptions of an injury based on a pre-existing description.
-
Data filtering: You can prompt the GPT model to find only the relevant parts from a longer text, such as finding comments that may be hurtful from a thread.
Using OpenAI’s API in Valohai
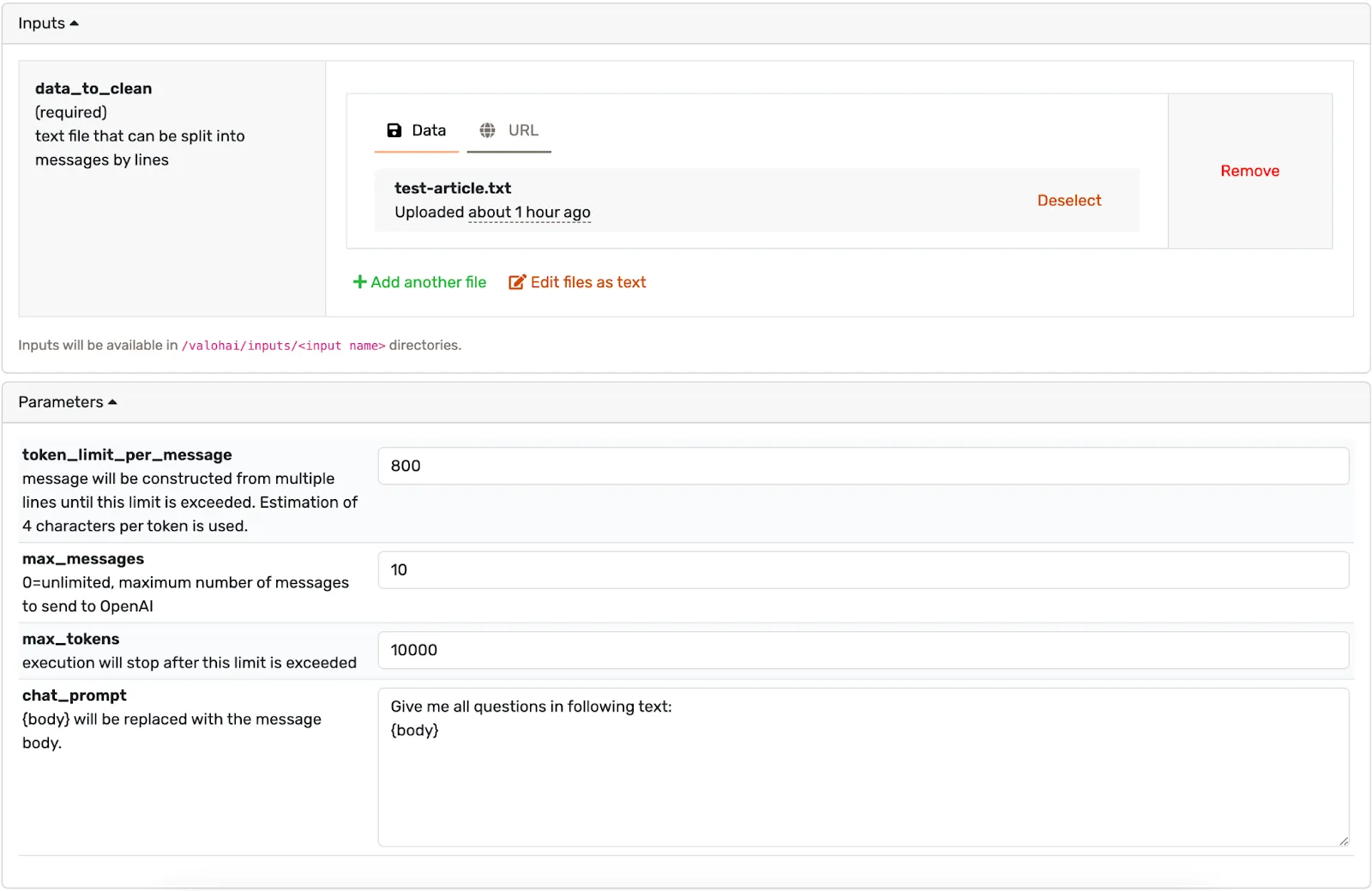
Below we implemented a simple step in Valohai that uses the OpenAI API to find questions in a long text input.
View code on GitHubSee the full repository here: github.com/tokkoro/openai-data-enhancement
The prompt can be given as a parameter and the main content can be passed as an input.
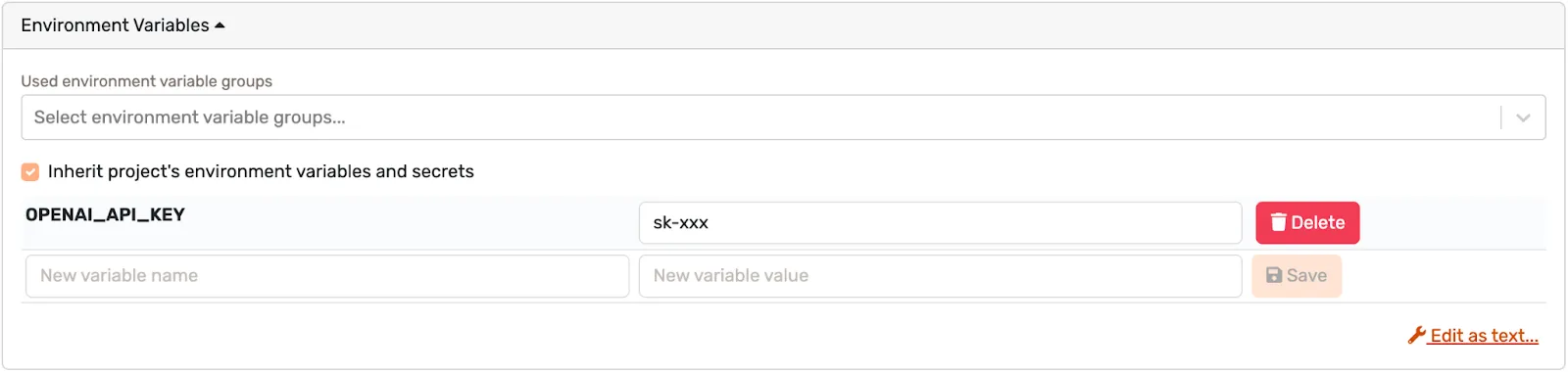
And naturally, the API key should be passed as an environment variable.
Logs in Valohai can be used to display real time information if your input is longer than a single API call.
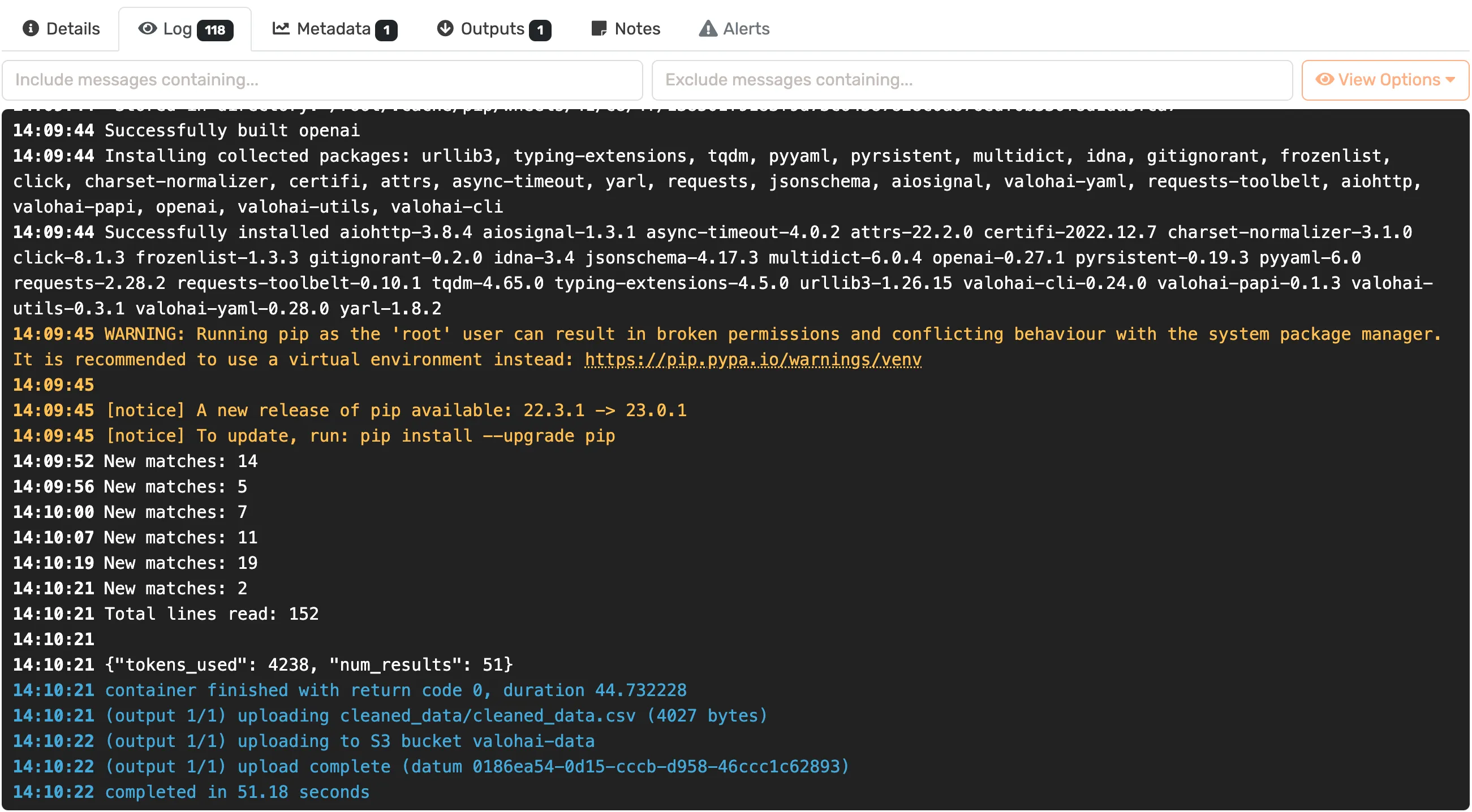
The data is outputted as a CSV which is versioned in Valohai and could be used for any follow-on steps.

Final thoughts
There are plenty of clever ways to utilize ChatGPT and other APIs in your own ML projects. Valohai’s Developer Core allows you to run anything inside Valohai executions, including API calls, which makes it easy to integrate outside services into your pipeline.
Find this example in full here: github.com/tokkoro/openai-data-enhancement