
Transfer Learning and Large Language Models
LLMs (large language models) have grabbed the public attention with ChatGPT and plenty of companies are looking at opportunities to incorporate similar functionality to their products but perhaps with more added domain expertise and focus.
This is possible through transfer learning, where you take an existing state-of-the-art model like GPT-3 and refine it into a model for your specific use case by teaching it with domain-specific data. For example, your use case might have a desired output style and format (e.g. medical notes). Through transfer learning, you can use your proprietary datasets to refine the LLM’s ability to produce something that fits the description.
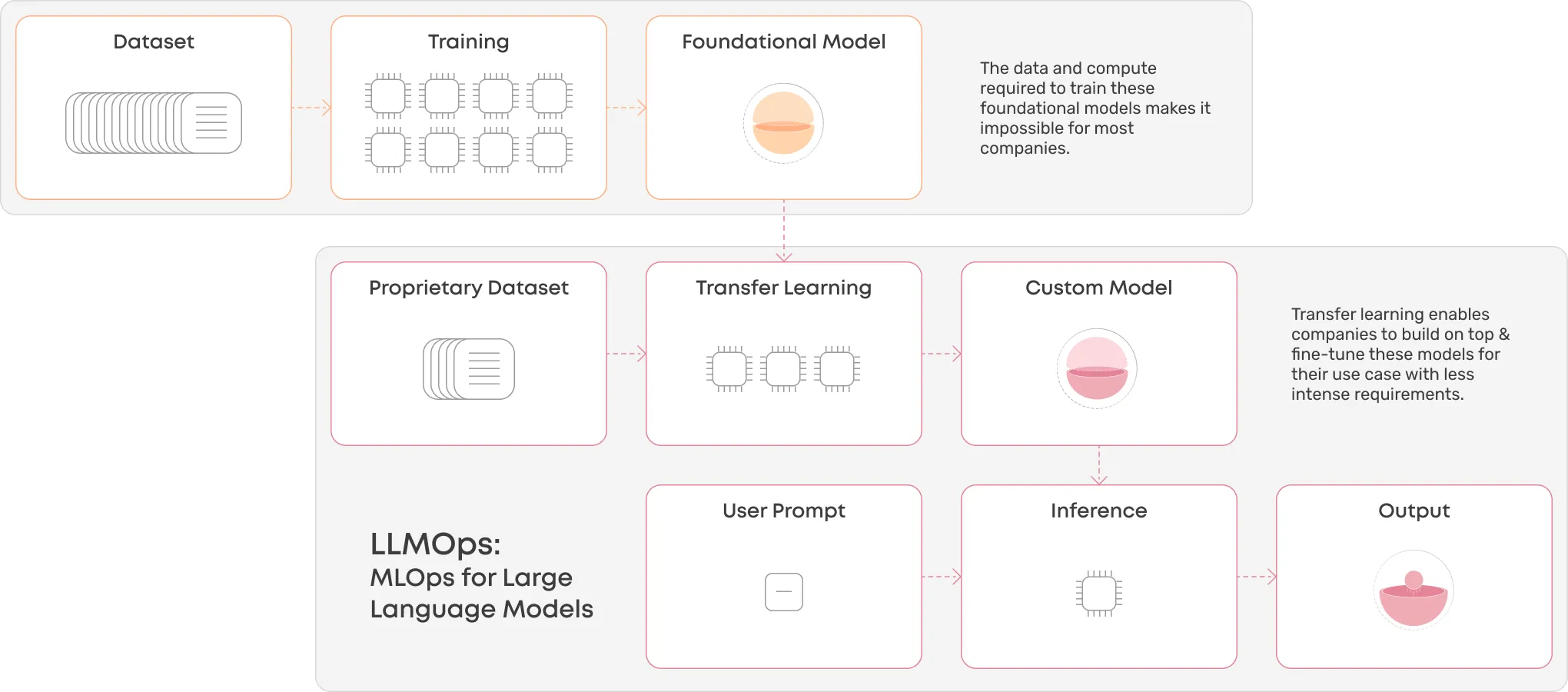
Transfer learning isn’t anything new, but the recent explosion in the popularity of LLMs has sparked discussion on how to train and deploy LLMs, hence LLMOps.
What is LLMOps?
Sidenote: A better term than LLMOps would cover other types of foundational and generative models too. LMOps? FOMO? Or perhaps, we should just stick to MLOps with different use cases.
LLMOps focuses on the operational capabilities and infrastructure required to fine-tune existing foundational models and deploying these refined models as part of a product. To most observers of the MLOps movement, LLMOps isn’t anything new (except as a term) but rather a sub-category of MLOps. A narrower definition might, however, help drill into more specific requirements that fine-tuning and deploying these types of models has.
Foundational models are enormous (GPT-3 has 175B parameters) and thus take enormous amounts of data to train, and the compute time to match. According to Lambda Labs, it would take 355 years to train GPT-3 on a single NVIDIA Tesla V100 GPU. While fine-tuning these models doesn’t require the same amount of data or computation, it’s by no means a lightweight task. Infrastructure that allows you to use GPU machines in parallel and can handle huge datasets is key.
Twitter went wild with napkin math around how much it costs to run ChatGPT (it’s a lot). While OpenAI has not released any statements publicly, the discussion highlights that the inference side of these vast models also requires a different level of computing than more common traditional ML models. In addition, the inference might not be just a single model but a chain of models and other safeguards to produce the best possible output for the end user.
The LLMOps Landscape
As mentioned above, LLMOps isn’t anything new for those familiar with MLOps, and thus the landscape will be similar. However, many of the MLOps tools that are designed for a very specific use case will not bend to fine-tuning and deploying LLMs. For example, a Spark environment such as Databricks works for traditional ML, but for fine-tuning LLMs, it likely won’t.
Broadly speaking, LLMOps landscape today has:
-
Large Language Models
-
LLM-as-a-Service is where a vendor offers the LLM as an API on their infrastructure. This is how primarily closed-source models are delivered.
-
Custom LLM stack is a broader category of tools necessary for fine-tuning and deploying proprietary solutions built on top of open-source models.
-
-
Prompt Engineering tools enable in-context learning instead of fine-tuning at lower costs and without the use of sensitive data.
-
Vector Databases retrieve contextually relevant information for certain prompts.
-
Prompt Execution enables optimizing and improving the model output based on managing prompt templates to building chain-like sequences of relevant prompts.
-
Prompt Logging, Testing, and Analytics … Let’s just say it’s an emerging space that has no categories yet. a16z took it up a notch if you’re looking for further reading.
-
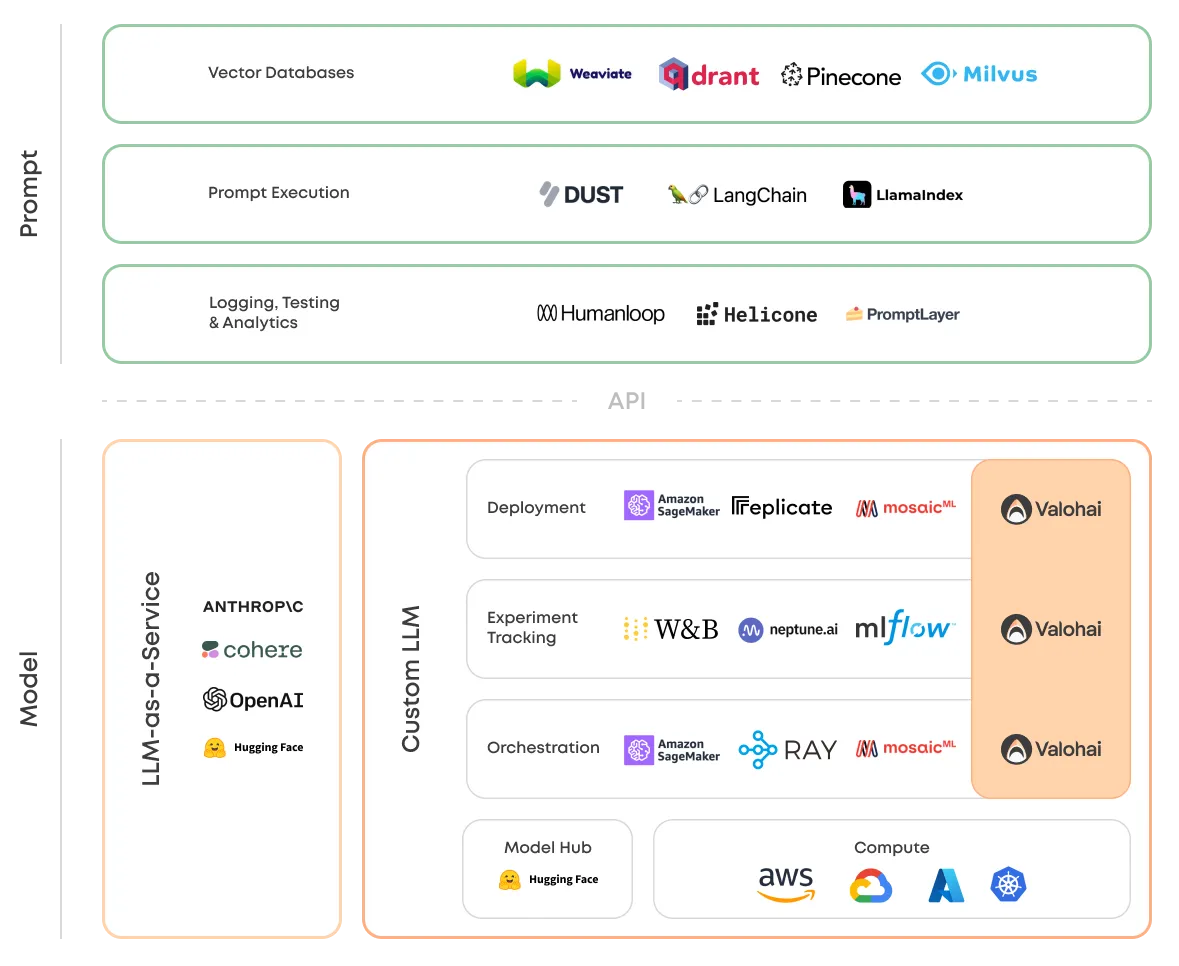
Updated Aug 24, 2023. The diagram above is for illustrative purposes only and this list is by no means exhaustive.
In the long-term, it’s hard to see LLMOps as a term having staying power, but its emergence is a reminder that ML is rapidly evolving and more use cases are popping up all the time.

If you are looking for a platform that works for LLMs and any other ML models, you should check out Valohai’s 14-day free trial.
Evaluating LLMs? Valohai LLM lets you compare models, prompts, and configs side by side with 3 lines of Python. Try it free →