Web scraping and data gathering are vast topics. There is no single correct way to programmatically collect data from sources designed for human consumption. The right approach for web scraping depends on the context, and in this article, we focus on an early-stage ML project needing time series data.
Let’s say we want to make predictions on New York housing markets and are convinced the best approach is to scrape data from the realtor websites. Your dataset will be an archive of all the apartments on the market since the day you started scraping. Think of it as a series of daily snapshots of the market state.
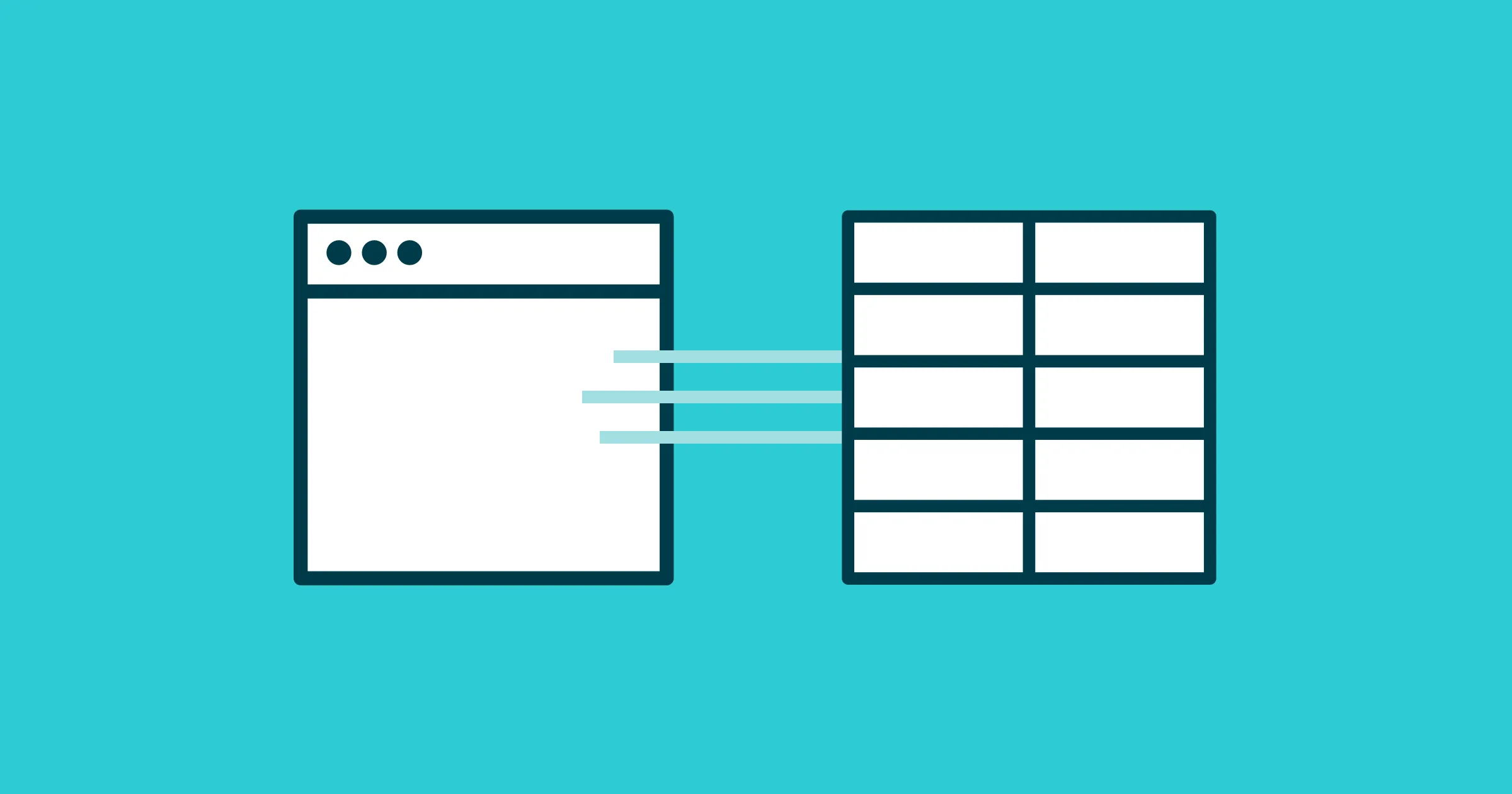
If you have no experience in modern frontend development - or the last time was a decade ago - your idea of how to scrape websites might be misguided. The naive mindset is that you make HTTP requests to a web server, get back HTML, parse features, and store them in a database. In rare cases, this approach may work out fine, but the chances are it won’t.
The first problem is the response from the web server. On a modern website, it is not HTML content ready to be parsed. Instead, the response is a hairball of Javascript, just the scaffolding for the final webpage. This hairball must execute on your local browser and build the final webpage asynchronously piece by piece before it can be parsed for features. The websites of today are dynamic beasts.
Luckily there are tools available for handling this. The most popular tool is Selenium, originally built for automated browser testing. It puppeteers popular browsers like Chrome or Firefox under the hood. With Selenium, you can programmatically navigate a website with a real browser, emulate mouse clicks to get to the right sub-pages, let the browser execute the Javascript scaffolding, and finally have your script scrape the features from the document object model (DOM), a well-defined API for HTML in the browser.
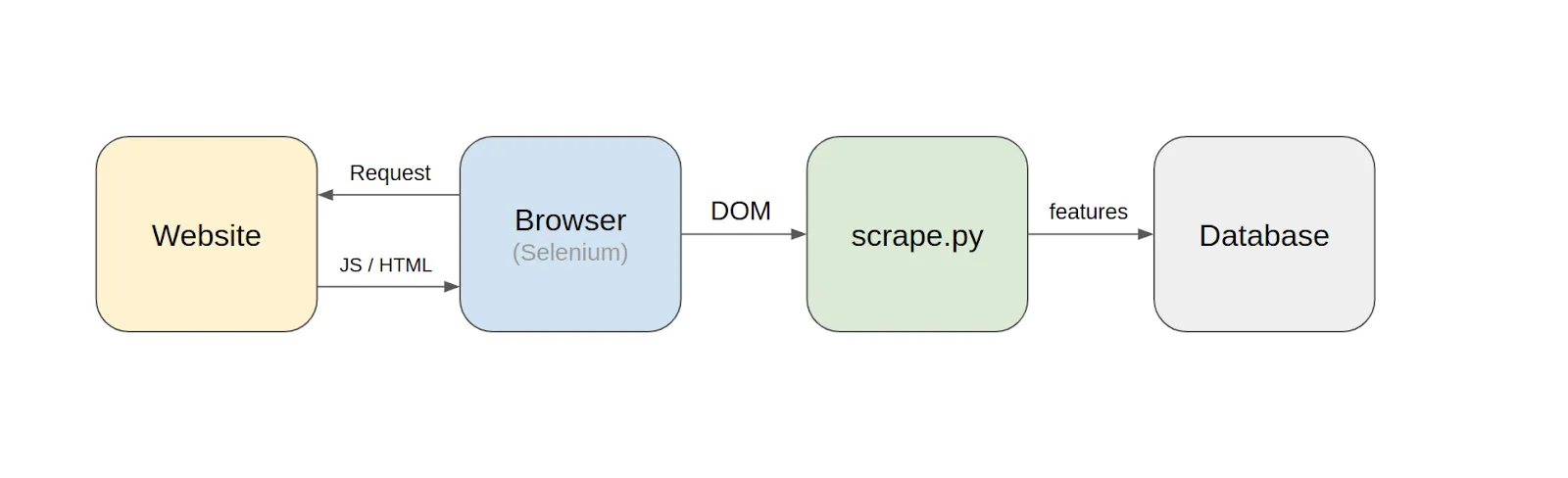
This approach, where we scrape features on the fly, might be fine for a simple operation, but let’s say we need to scrape two dozen realtor websites daily. Each website will have more than a hundred data points for each apartment, with varying layouts and terminology. Websites get updated all the time, and scrapers will constantly break. Maintaining a robust daily scraper producing clean data even for a single website is a lot of work. Doing it for two dozen websites is a massive undertaking.
At this point, we pause and remind ourselves that this is an early-stage ML project.
We are not sure if the scraped data is even useful. It is only a hypothesis. Should we painstakingly build a complex web scraping pipeline for hundreds of features when we might only use three? Or maybe we’ll use zero!? We got ahead of ourselves.
Another problem is that the data is only temporarily available. Once the apartments are sold, they vanish from the website. When scraping something over time, we have to get it right on the first day (and every day) to avoid inconsistencies. We also need to scrape for a long time to get a enough continuous data for our model. Deciding upfront what, how, and where to scrape is a high-stakes decision.
The answer is to rethink and simplify the scraping pipeline and align it better with the exploration-heavy ML project. We need a way to scrape websites without big upfront investments or early judgments about our final ML model.
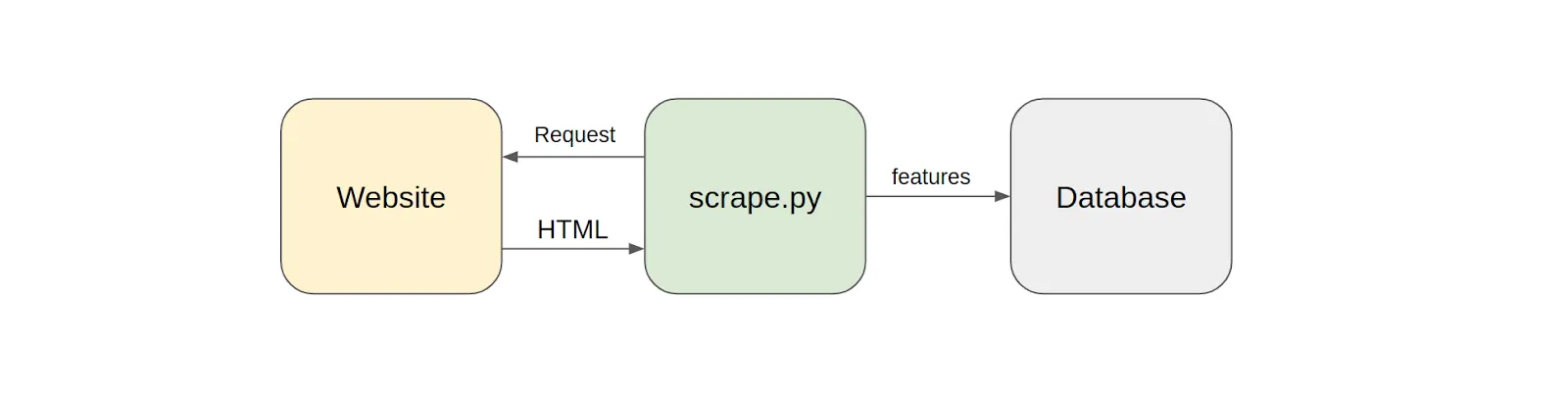
The key is to decouple HTML gathering from the feature scraping.
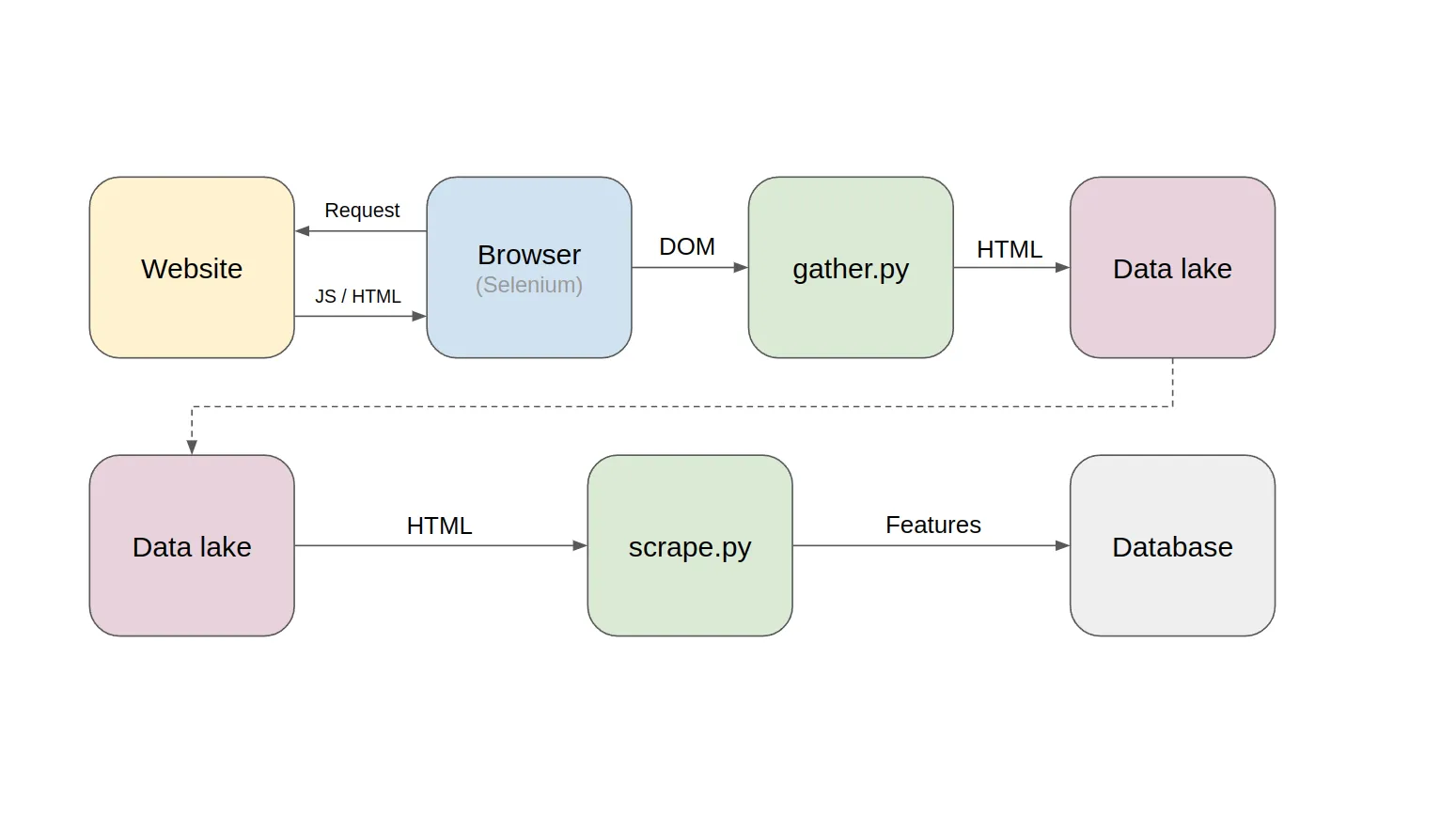
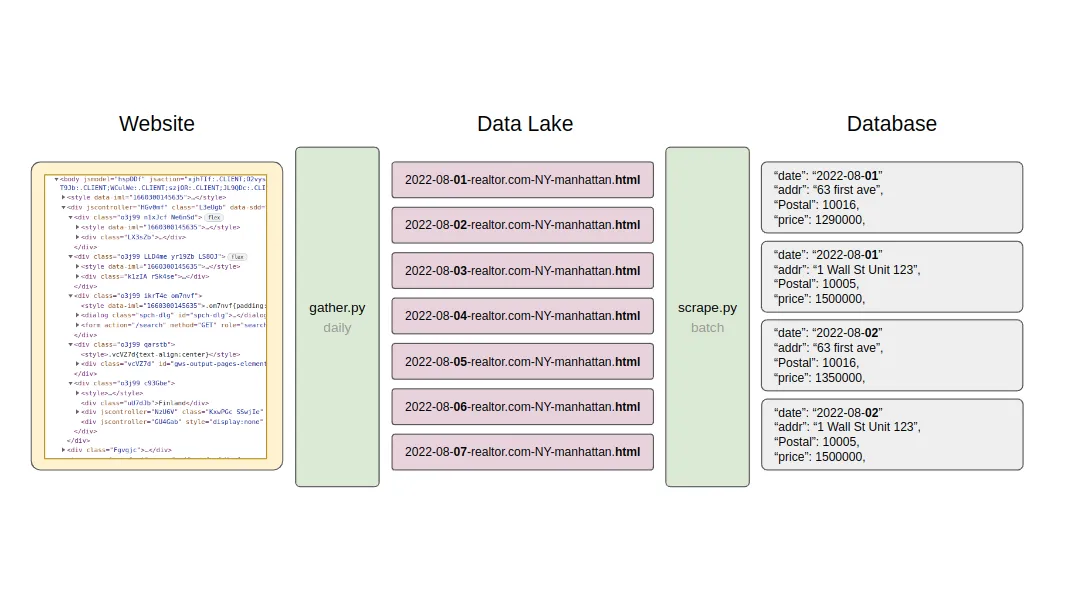
What runs daily is just a simple HTML gathering script, gathering the content using Selenium as bulk and saving it into a file without opinions. This HTML represents a snapshot of the webpage on that day. Nothing more, nothing less. A time series of HTML snapshots will slowly start filling up the data lake.
This raw HTML is later scraped using a decoupled feature scraper. The beauty of the setup is the ability to rerun the scraper over and over again. It’s like having a personal “Wayback Machine” letting you visit yesterday’s website and re-scrape it with today’s knowledge.
The Wayback Machine is a great example of an HTML snapshot pipeline
The benefits of creating your own “Wayback Machine”:
- Get started with minimal effort
- No high-stakes decisions upfront
- No loss of data from complex daily scrapers breaking
Valohai is an MLOps platform for trailblazing pioneers, offering end-to-end capabilities to manage custom data pipelines all the way from distributed data collection to the deployment of your ML models. Valohai is a create fit for creating a private Wayback Machine described here, as it can easily scale to hundreds of scheduled scrapers and handle all the data versioning needed to manage the ML pipeline.
Do you want to learn more? [Book a call] (https://valohai.com/book-a-demo/) and let’s find out how Valohai help your project.