
LLMs and other generative models continue to make ripples across the product landscape and far beyond. Just over a year since the public release of Chat-GPT, we have seen thousands of attempts to productionalize GenAI. In turn, these attempts have uncovered many challenges from sending sensitive data to third-party APIs to the complexity of fine-tuning open-source models and evaluating their output.
We paired up with Root Signals to host our own Slush side event to reflect on 2023 and envision 2024 for all things production-grade GenAI.
But first, here’s a quick round of introductions:
-
Root Signals is a product company that provides an enterprise platform to build, measure, and control LLM applications that you can release with confidence.
-
Slush is an annual event in Helsinki, Finland bringing together the founders, investors, and startup operators in the startup ecosystem from around the globe.
In order to give a comprehensive overview of the topic, we invited 9 industry experts working with GenAI in diverse environments from innovative startups, established enterprises, consulting powerhouses, social institutions, and more.
Over 3 hours of talks, our guests got to hear multiple success stories as well as challenges and predictions. We put together all these insights and stories for your enjoyment in this blog post.
TL;DR:
-
Validating use cases for GenAI is vital for justifying the return on investment as the complexity gets out of hand throughout development cycles.
-
Moving beyond third-party APIs is necessary for retaining ownership of proprietary data and staying in control over costs.
-
Ensuring consistent and reliable output from generative models remains one of the greatest challenges.
- Expectations and use cases
Although the magic might be wearing down, many folks out there still have high expectations of generative models and their capabilities. In turn, these expectations get buy-in for initiatives where GenAI is not always the best pick. As the old saying goes, if all you have is a hammer, everything looks like a nail.
For production-grade GenAI applications, it’s important to distinguish between addressing internal use cases within organizations and building applications for use by customers and other external stakeholders.
In his talk reflecting on 2023, Teemu Toivonen (Senior Sales Specialist at Microsoft) shared that he had seen only one GenAI application developed for such an “external”, customer-facing use. In addition, prompt engineering and RAG (retrieval-augmented generation) made up over 90% of development projects whereas fine-tuning and custom-model training humbly took the remaining share.
One of the main reasons for these disparities is the lack of ways to consistently control the output of generative models (more on this later). Without this control, there are many risks to showing the output to customers. During our panel discussion, Eero Laaksonen (CEO at Valohai) illustrated the degree of risk in different use cases. There are far fewer risks in, namely, Adobe’s Generative Fill outputting a silly image for an in-house designer as opposed to a patient receiving a wrong diagnosis.
Later during the same panel, Fred Simon (Co-Founder and Chief Architect at JFrog) suggested that the LLMs are the new UIs. Instead of click-based navigation through predefined options, LLMs enable users to interact with applications by giving them open-ended requests.
This is akin to how Copado applied GenAI. Kimmo Nupponen (Director of AI Technologies at Copado) led the Applied Research Organization to build three GenAI applications in the style of an AI Companion, CopadoGPT, and Test CoPilot. Put together, these applications aimed to support a wide range of both internal and external use cases. Firstly, they enabled their sales and support functions to obtain information related to the product. Secondly, they enriched the core product capabilities with GenAI-driven features for streamlining deployment pipelines as well as development (code generation, debugging, and code review) and QA testing (dynamic test generation, debugging, and test review).
You can see a simplified infrastructure for these applications below. The Guardrails ensure that the user prompt is not harmful, whereas the Reasoning & Routing component figures out the intent of the user request to route it to the most appropriate algorithm. The Post-Processing piece enriches the output by retrieving additional media (such as screenshots) related to the initial user request.
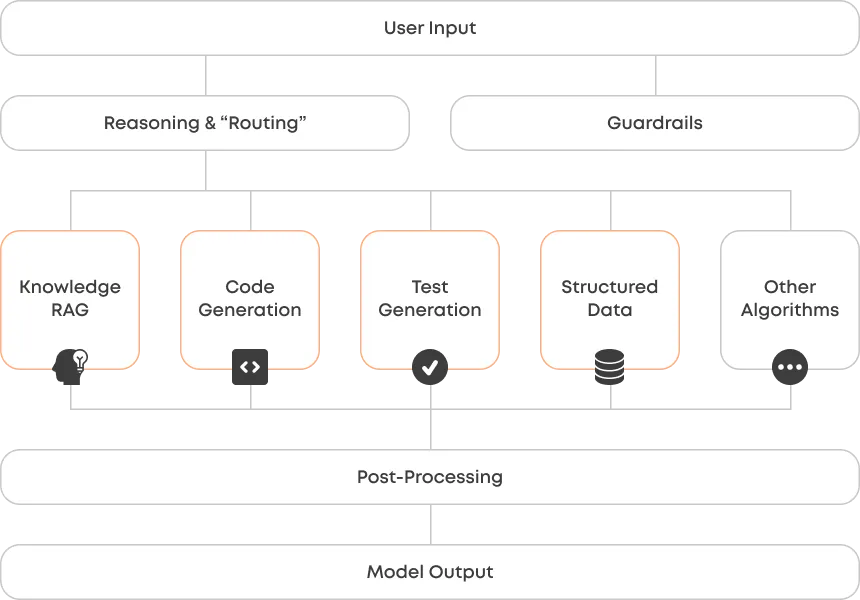
A simplified architecture for GenAI applications at Copado.
When working with Kela (the Social Insurance Institution of Finland), Marko Taipale (Principal Consultant at Solita) took an approach often seen in startups to an unfamiliar setting of governmental organizations. In short, the approach consisted of gathering input, scoping problems worth solving, and validating solutions. Together with the client, Marko and his team mapped out the role of AI in all future scenarios. As a result, they discovered three use cases where GenAI can have the most impact: making the social benefit structure understandable, ensuring whether a person is eligible for support, and enabling the support function.
One of their key takeaways was that adopting GenAI was much more than answering technical questions throughout the development process. Many breakthroughs were made thanks to effective communications with relevant stakeholders and navigating organizational structure. In order to support the adoption process, Marko and his team put emphasis on validating solutions in context as well as testing growth hypotheses.
- Moving beyond proprietary models
Oguzhan Gencoglu (Head of AI at Root Signals) hinted that more often than not the value of GenAI in production comes from the data rather than from the models themselves. Eero and other panelists agreed that many PoCs face significant risks when putting sensitive data into third-party APIs. While the data used for internal productivity tools can get a pass, the stakes are much higher for regulated apps (e.g. for medical applications with patient data) or core products.
Henrik Skogström (former Head of Product at Valohai) took a deeper dive into risks associated with proprietary LLMs (or as we call them LLM-as-a-Service). Henrik identified risks over cost, performance, and overall service in addition to data ownership. But most importantly, the severity of these risks varies depending on the use case.

It’s never been a good strategy to build your IP on top of unstable systems that you have no control over. Why would this be any different from the recent wave of GenAI applications?
Ari Heljakka (CEO at Root Signals) half-joked that the best thing about the release of GPT-4 was the subsequent release of LLaMA. Ari followed that smaller models can get the job done just as well in less time and at lower costs. Henrik further reinforced this by saying that fine-tuning open-source LLM (e.g. Mistral 7B) enables companies of all sizes to release GenAI applications without breaking the bank.
But while mitigating the aforementioned risks, the complexity of these projects can get out of hand rather quickly. Embarking on this journey requires having the necessary resources for preparing training datasets, fine-tuning models, managing infrastructure as well as deploying and monitoring the models. For some companies, it’s hard to justify the return on investment without a solid use case.
Reflecting on his experience, Kimmo said that it took his team about 2 weeks to build the initial prototype. However, further development took up to 6 months until the application was production-ready. Kimmo shared that the greatest challenges that his team overcame were perfecting RAG and ensuring consistently reliable output of the models.
Circling back to Teemu’s experience, prompt engineering and RAG made up over 90% of all development projects related to GenAI. However, the challenges for wide-scale adoptions extend beyond these technical challenges. Similar to Henrik, Teemu shared a wide variety of risks from the maturity of ML within organizations to cost and returns, control, and legal considerations: “There is a lot to be solved before wide-scale adoption.”
- Evaluation and monitoring
Among their predictions, Ari and Fred agreed that GenAI applications will go beyond interactions with human users and they will evolve to control other software systems. However, both emphasized that safety and consistency are the key elements for making this transition a worthy one.
When building for production, there’s a need to weigh between the maximum performance and consistent performance of generative models. In his portion of the talk, Oguzhan Gencoglu (Head of AI at Root Signals) covered how to evaluate, validate, and control the output of LLMs consistently and scalably.
Why do we need a thorough evaluation?
Firstly, LLMs are constantly changing, especially the proprietary models. For example, you can get one answer this week and a completely different answer (or no answer at all) next week after asking the same question to Chat-GPT. A while back, we covered that unannounced changes to third-party APIs can break (and actually have broken) thousands of applications.

Secondly, LLMs tend to behave unexpectedly, which is known as emergence. For example, a model might learn something different from what you intend to teach it. LLMs also come with hallucinations and biases. Another example is the “lost in the middle” phenomenon when the output of the model has high accuracy in the opening and closing parts of its output while lacking cohesion in the middle.
Thirdly, we expect rigorous regulation to affect the generative models in the very near future. Complying with these regulations might require showing how the model arrived at the output along with its lineage. Production models must have guardrails along with measurable and scalable performance metrics.
Last but certainly not least, applying GenAI to solve certain real-world tasks might have an especially strong need for evaluation. In other words, evaluating generative models is crucial for ensuring their effectiveness, safety, and control in certain settings, such as industrial or medical applications.
But why is evaluating LLMs so difficult?
The short answer is that LLMs are complex.
As of today, we lack well-defined metrics for measuring the performance of generative models for business usage (although some metrics exist within the realm of academia). As we covered earlier, we all once had (or still have) high expectations of LLMs. One of these expectations is having full trust in the LLMs to produce accurate output at all times. Would you feel at ease if your dog was out walking itself and would you trust it to be back home right on time?

An analogy for a generative model in charge of monitoring its own output.
Moreover, LLM-based applications have many moving parts. In addition to evaluation and validation, retrieval remains another challenge to solve. For example, the way you phrase your question in the prompt has a great influence over the answer. And for the exact same prompt, the output can be different between all the models out there.
As a much-needed side note, the team at Root Signals has been working on a platform for measuring and controlling the output of LLMs. If you’ve been trying to tackle these challenges in your development work, we warmly encourage you to get in touch with them here.
- GenAI Beyond Production
In addition to the insights on taking GenAI projects beyond prototypes, we got numerous perspectives on GenAI in other areas. Before wrapping up this blog post, we would love to share some of them with you.
GenAI for developer productivity
Fred admitted to using AI code assistants, adding: “The more you use them, the more they learn the way you code.” But in no time, he reinforced past concerns that for this your code base has to go somewhere. Just like with many other use cases, there is a significant risk in trusting your confidential data to third-party APIs.
We already covered alternatives (ahem, fine-tuning open-source models) and Fred said you can teach every developer how to use the right way. After all, Fred sees these assistants as accelerators for development projects (akin to the rise of distributed and parallel computing) rather than replacements for talented engineers.
Investor’s perspective on GenAI
As a venture capitalist at Angular Ventures, Gil believes that - despite their capabilities - AI assistants don’t change the fundamental equation of venture. With enough resources to get by, small teams of talented people can generate immense value. However, these AI assistants enable startups to come up with and execute increasingly more ambitious plans. Gil concludes that if you’re not planning with the “co-pilot efficiency” in mind, you’re probably doing it wrong.
When asked whether GenAI is truly a disruptive technology, Gil referenced a definition by which “disruptive technology disrupts incumbents and empowers the challengers.” However, Gil suggested that the opposite may be true with GenAI as it seemingly makes it harder for the challengers to penetrate and easier for incumbents to press their advantages. One of the reasons is that enterprises possess large amounts of proprietary data, which gives them a choice to pull their data away from third-party vendors and build their own solutions. Gil concluded by saying that “no one is going to create sustainable value with these tools unless they’re using proprietary data.”
We highly recommend you read more of his perspectives on “navigating AI’s iPhone moment” here.
The next 5 years for GenAI
During the panel discussion, Eero and Oguzhan reflected that it took more or less 5 years to take deep learning from PoCs to production-grade features. They agreed on a similar timeline for generative models.
Fred resonated with this by adding that it took so long to productionalize deep learning because we had to figure out how to get the value out of data rather than develop models.
“In the past, the output of software ranged from strings in databases to numbers on invoices or robots moving in the XYZ axis. But today, the output of LLMs is human discussion, language, and pictures loaded with creativity, and emotions. This is the stuff we haven’t really had until today.”
And what are your predictions?
We are only a couple of months into this year and we have already seen numerous developments, setbacks, and workarounds in the realm of GenAI. What we know for sure is that this year is going to be even more eventful and it will set the pace for years to come.
What are your thoughts on the perspectives above? And what are your predictions for all things GenAI in 2024? Feel free to share them with us below - we are looking forward to reading them!