As machine learning creeps into the mainstream of digital products, understanding the basics of machine learning is becoming more relevant to many product managers. Product people today are a rather heterogeneous bunch. For some, the focus is heavily on user experience (for example, if the main value proposition revolves around a killer UI), while others already manage products that require deep understanding of data and code.
Understanding ML will be necessary for both ends of the spectrum – only for slightly different reasons. For UI-focused products and PMs, fuzzy logic and machine learning features will radically change how the user interacts with the product. Thus the presentation of such features becomes very important. On the other hand, product managers who manage APIs or technical platforms would be more concerned with how the AI algorithm is integrated.
Product management is as massive a topic as machine learning so let’s start with a fundamental question. When is it worthwhile to develop an AI product? Of course, you can also apply this question to a feature in the context of a larger product.
A helpful tool most PMs have seen for this is the Sweet Spot for Innovation that IDEO popularized. It explores the feasibility, desirability and viability of a product and worthwhile ideas tend to hit all of these aspects. If you aren’t familiar with the framework, you should read this article.
Let’s look at these concepts from a perspective of a machine learning product.
Feasibility
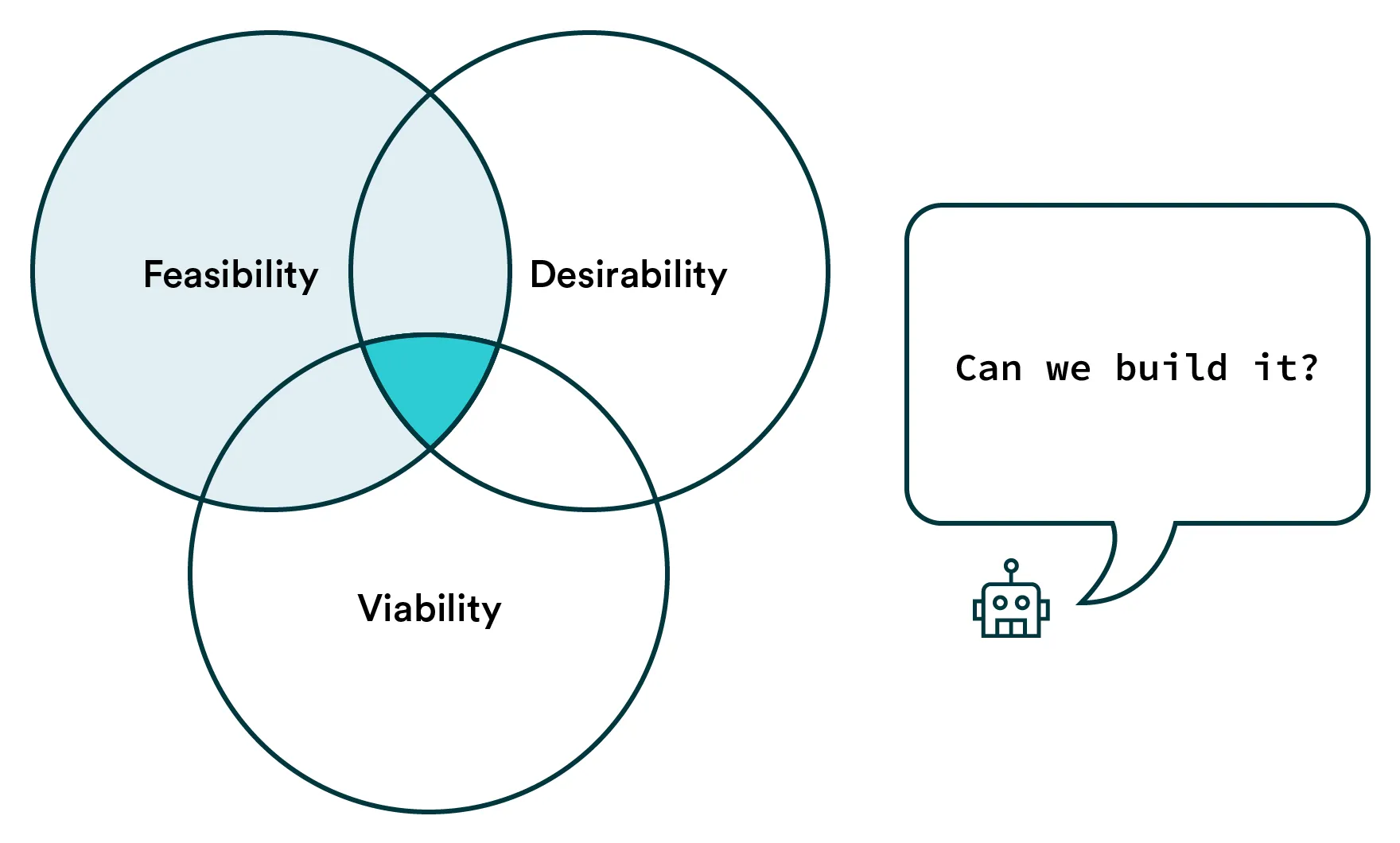
Feasibility isn’t usually the part that I’d recommend you start with when evaluating a product idea. Still, it’s perhaps the most different aspect compared to traditional software products, especially as we are only in the early innings of ML-enhanced software.
Even though time estimates are still hard, we’ve collectively become quite good at evaluating what is possible with software. When you describe a problem to a developer, they already think about technologies and libraries. You may be thinking about previous products where the problem in question has been solved. Similar thought patterns will pop up with time for machine learning.
The questions you should be asking yourself and your team when it comes to feasibility are:
What is the problem we want to solve?
Problem-setting is necessary for any problem, but it’s even more so when dealing with more significant uncertainty. For example, let’s say our idea is to detect flawed products in a production line. Granularity becomes important here: how big of an improvement are we looking for in faulty products sent to the customer?
Do we have data about the problem? If not, can we get data about the problem?
Machine learning is all about data. It doesn’t always mean big data, but enough quality data about the problem. Some data is easy to acquire, such as user actions from your application. They are probably already stored somewhere.
Other data types are more difficult, such as large, labeled image sets. Looking at our production line example, you’d need an image set that contains both flawless and defective products with the flaws labeled and shot from the same angles where you’d place the sensors in the production line.
Are there patterns in the data that make sense for an algorithm?
The hard part about machine learning is that often there’s a lot of work upfront by data scientists to evaluate a dataset and experiment to see whether there are patterns in the data that an ML model can make sense of. Unlike traditional software, feasibility is hard to evaluate without rolling up the metaphorical sleeves. For example, with your dataset of labeled products – both faulty and faultless, a model will be able to distinguish between the two.
In traditional software, feasibility can be almost described as binary (possible or not). However, in machine learning, feasibility may be more of a scale, which spills over to what’s desirable.
Desirability
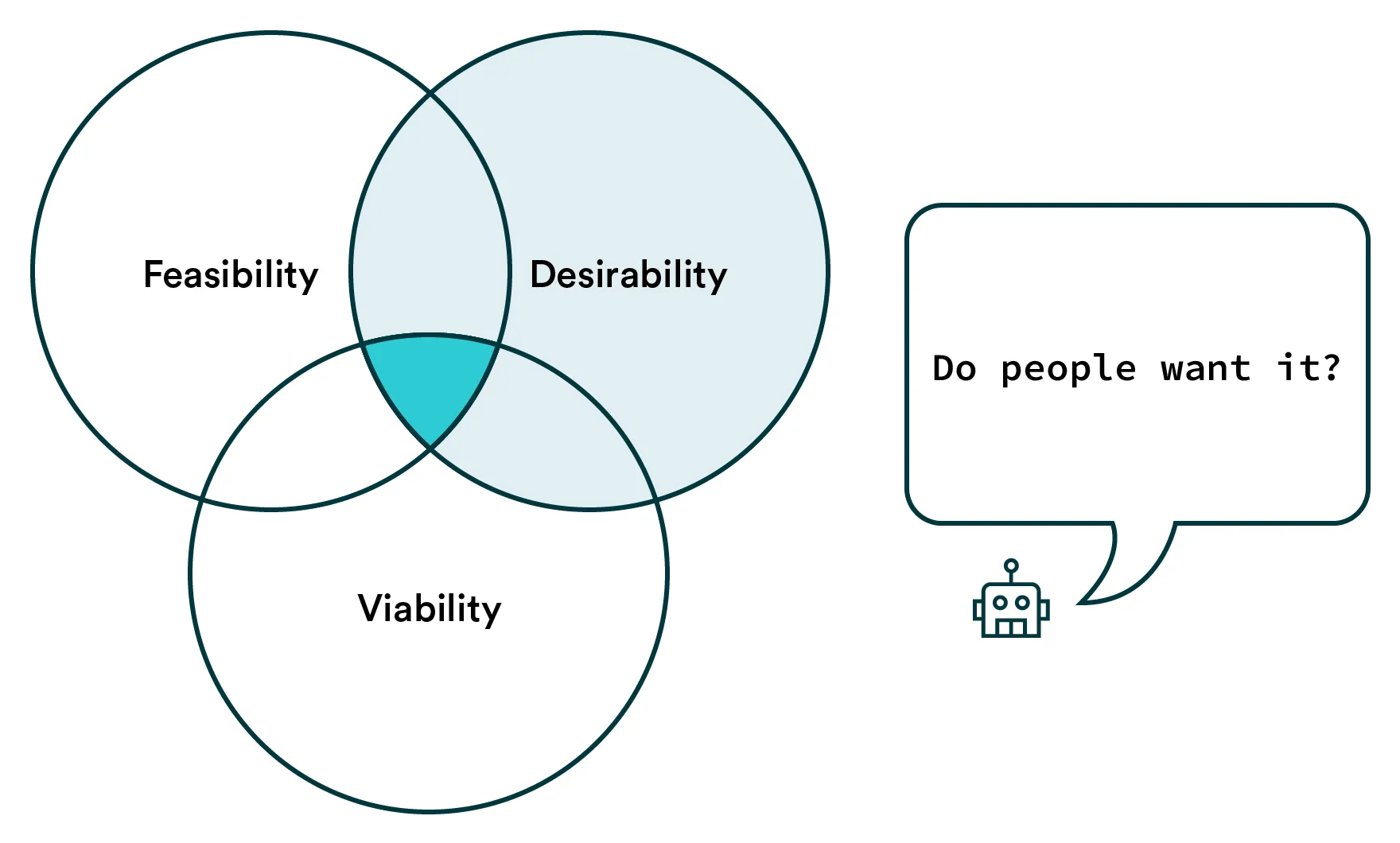
Figuring out what people want is a tricky business and with AI products, it’s no different. Evaluating desirability is the same as traditional software on the surface level, but there’s a trap. Having AI assess every product on a product line seems very desirable. In fact many companies are looking into these types of solutions. But there are additional questions you should be asking:
How well will the algorithm perform and how well does it need to perform?
This question ties to both the feasibility and the desirability of a solution. Again there are no easy answers before a data scientist applies some elbow grease.
You may find that an algorithm will detect faulty products at a great rate but also produces false positives. What will this mean for your production line? Perhaps the production workers will completely ignore the algorithm because of false positives, and your solution becomes undesirable.
It’s easy to describe a fully autonomous solution, but it’s not always feasible to build. Perhaps the product that you can feasibly build is simply a computer assistant to a human. A fully autonomous vehicle and computer-assisted steering are wildly different in desirability. It would be best to consider the point that something becomes desirable in your context. This ties to the next question too.
How much control will the user have? Does the user trust your solution and see the value the same way you do?
Trust is a big topic in AI and for a good reason. Machine learning models can be black boxes for the people developing them, so imagine how the end-user feels. An important aspect to consider is how much information you will have to convey to convince the user and how much control you give over decisions to the user.
For example, in our production line example, will you need to present the algorithm’s confidence about each prediction (i.e. this product is 70% likely to be faulty)? Will you give the production line manager the ability to adjust at what level of confidence a defective product is discarded?
This is a simplification of course. Handing over the reins of an algorithm to the user might be difficult to implement and difficult for the user to understand.
These questions become extremely important in sensitive use cases such as healthcare, as unintended consequences can be dire.
Viability
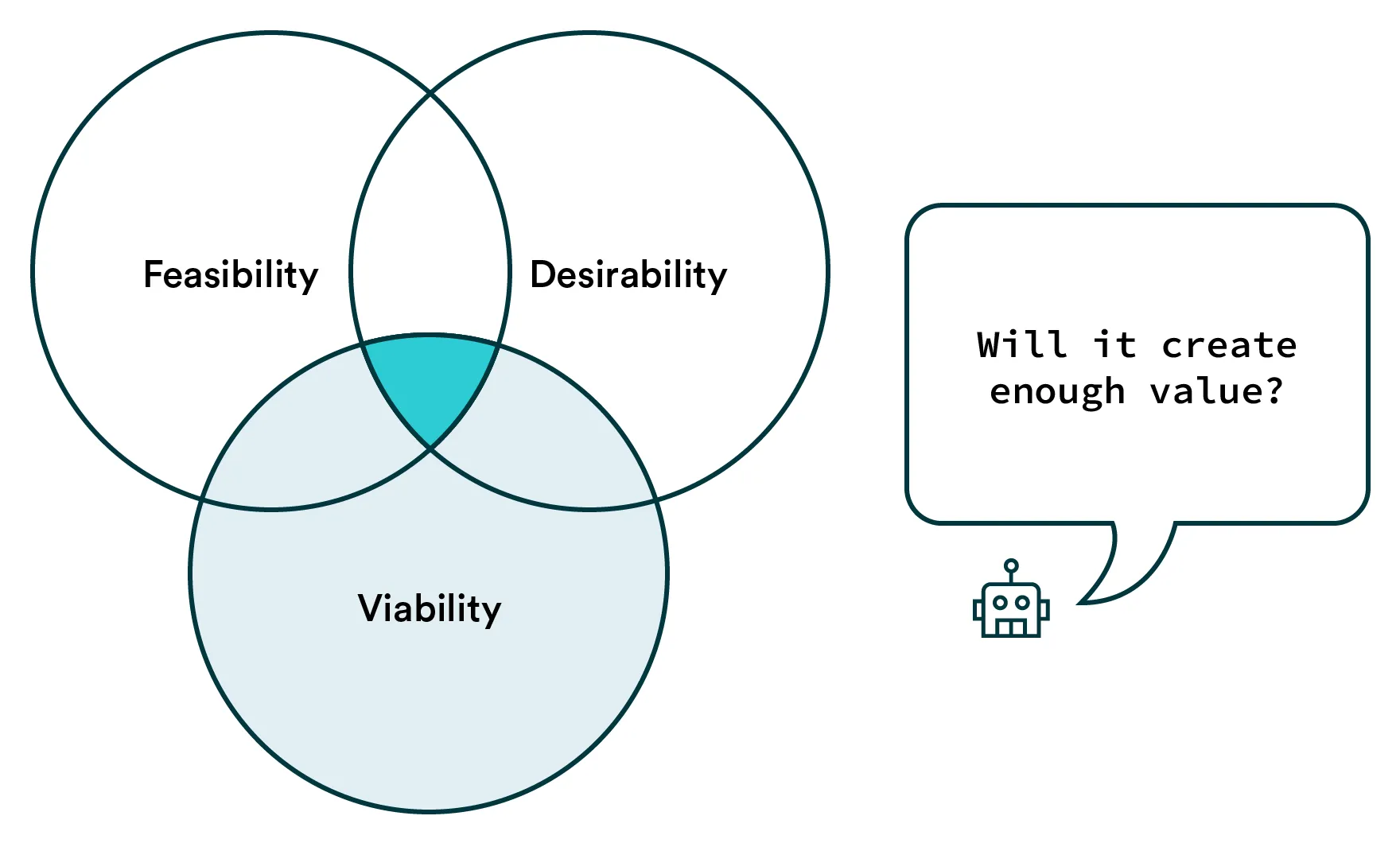
If you’ve presented a feasible and desirable solution, it becomes a question of how much it is worth to the user and, ultimately, you. There are many ways to evaluate commercial viability and often, PMs will have to consider whether the new product idea aligns with the company strategy.
Some more ML-specific questions that relate to viability would be:
Will the value generated in the long term be more than the short term cost?
Developing ML capabilities can be ridiculously costly. Consider that data scientists and ML engineers are some of the most sought-after talent today. Even if you already have them in your team, there are many other initiatives that they could take on. Additionally, ML-savvy designers and subject matter experts can be even rarer. Quality data can also be expensive to acquire and training models isn’t exactly free either.
There’s plenty of code to write and infrastructure to set up, ranging from data collection to model serving. On top of that, machine learning is new to most and there’s a significant amount of education and change management involved with all stakeholders.
Because of the cost and expertise required, it’s perhaps always worth starting by asking whether something can be solved with an expert system (i.e. rule engine) rather than AI. And secondly, ask how you ensure that your team uses research and technologies others have built before them. These two questions may save you and your company a pretty penny.
Will the problem change over time? Can the solution be expanded for other areas?
Two other aspects can significantly affect your AI product’s viability. The first is how dynamic the environment is where you are deploying your solution. Again in our production line example, will the product model change frequently? If so, the cost of acquiring data, training the ML model and doing other updates will compound overtime just to maintain the viability of your solution. This problem is more common than you’d think.
The other side of the coin may be that your solution is replicable to other similar problems, and you can use most of the engineering again and again. For example, you may have originally designed the fault detection solution for a single product. Still, the same sensors can be installed on other production lines, and training data can be collected. These types of opportunities can justify many hefty upfront investments.
Tying it all together
There’s a certain naivety among product managers (but not limited to) when it comes to machine learning. Attitudes range from ML being entirely outside the realm of possibility to ML solving every problem with ease. So naturally, the truth is somewhere in between.
As this article shows, feasibility, desirability and viability are very interconnected in AI products and uncovering their relationships will require more concrete experimentation and prototyping than in traditional software. It also emphasizes that data scientists, engineers, product managers and subject matter experts need to work together from the start.