If you follow the big names of the industry, you have probably noticed the competition on Data-Centric AI by Andrew Ng that trended this year. We, Valohai and Ingedata are so glad that there is finally proper focus on the data, its validity, and reliability, after a decade of hype, first on BIG data and then the machine learning models and AI systems. Everybody knows this; data and especially its quality is what matters. Most of the datasets aren’t that big, and good old logistic regression will do the magic most of the time yielding explainable results.
What is data-centric AI?
“Data is food for AI” is a quote from Andrew Ng used in many posts and materials this year. He means that what you train the model with is what the model can actually do - garbage in, garbage out, if you will. This is tightly related to the discussion on ethics; whether your model is biased or not is based on your training data and whether it is so on purpose. And tied to the fact that the data you have, is, if not the most, at least close to the most valuable asset you’ve got when creating AI systems.
“What we’re missing is a more systematic engineering discipline of treating good data that feeds A.I. systems,” Ng said. “I think this is the key to democratizing access to A.I.” – Fortune, November 8th, 2021
In addition to the relevance of the data, Data Scientist spends most of their time on data preparation-related tasks according to multiple surveys (Forbes & Datanami) and also according to my own experience. The focus in research and topics discussed around AI and machine learning should be proportionately this way as well. But it is not. Only 1 percent of the AI-research focuses on data.
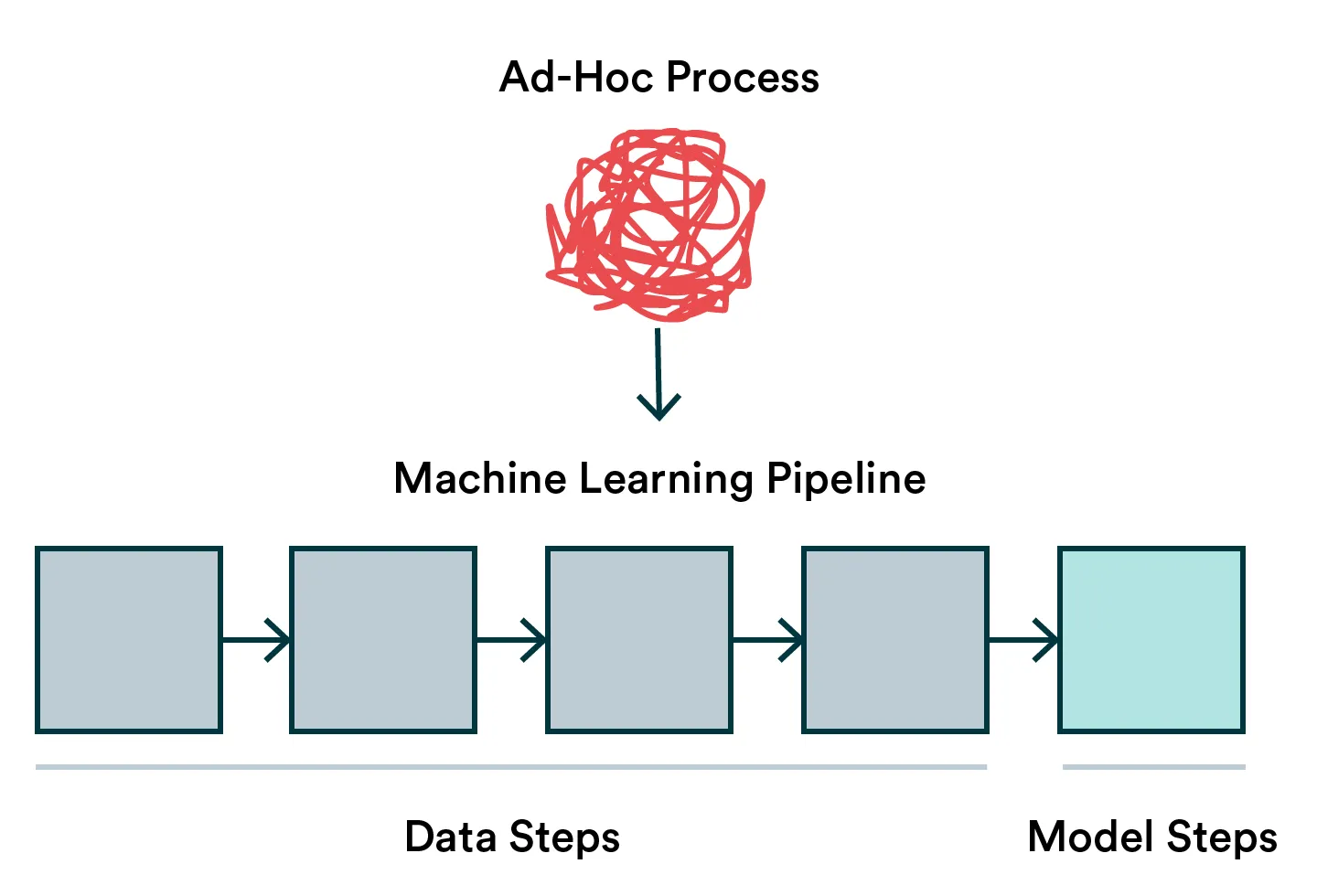
MLOps is all about turning data science into a repeatable workflow. If you start unbundling your activities, you’ll notice that around 80% tends to be focused on data-related things. When building a machine learning pipeline, there’s no reason the focus should be any different.
So in practice, what can you do to embrace more data-centric AI then? We have prepared some simple steps for you to keep in mind and implement.
Rules of thumb to follow for data-centric AI
Whether you are in the phase of building your first dataset for the problem at hand or you have already established an ML pipeline in place, please check these steps and transfer your thinking from model-centric AI towards data-centric AI. Let’s begin!
Your dataset should be created with domain experts
Your problem and solution - thus the dataset - should be defined iteratively with domain experts. The so common disbelief is that a Data Scientist just takes data and sprinkles some modeling fairy dust on it and voila, here you go. But a Data Scientist is an expert on representing your world in a format that is suitable for the machine to learn patterns from, not an expert in the business domain.
You need to know how the reality of the specific (business) problem is represented with the data. Or invent the way if there’s no data available yet. Let’s take a simple example, a marketing manager wants to detect Christmas trees from images and asks a Data Scientist to build a model. Without further definition, the Data Scientist could develop a training set with only real Christmas trees. But maybe the marketing manager also wanted to identify products shaped like Christmas trees, not just strictly Christmas trees.

Your dataset should answer the task at hand. For example, is the purpose of your model to classify a strictly defined object or objects that have vague characteristics?
Using supervised learning, you need to define the independent and dependent variables, i.e. inputs and outputs in modern lingo. In this example, the set of images and labels for them. Or if you are using unsupervised learning, it is even more critical that you have your problem well defined and represented with the data, i.e. having the dataset of only Christmas trees and not the surroundings or other decorations in the images.
An excellent way to start is to use tools from design and scrum, defining the problem you are trying to solve with Data Science together with the domain expert. Creating feedback loops and iterating on the data as you progress through creating the dataset ready for modeling is crucial.
Your dataset should be sufficient
One needs to have sufficient data to learn patterns from data and do it robustly, canceling out the random noise that inevitably is present in real life. Sufficient isn’t still a synonym for more data.
Let’s say you have a dataset of 10 images. Seven of the images represent only Christmas trees and three are some trees with lights on them. If you train your model with this dataset, the model will create a world where you have abnormalities 30% of the time, i.e. it will detect any item with lights on it. If you just leave the noise out, though, you might end up with an overfitted model that has too narrow a scope to work in real life, i.e. only the specific shape and style of tree and lights. The best solution would be to have more “normal” examples for the model to learn.
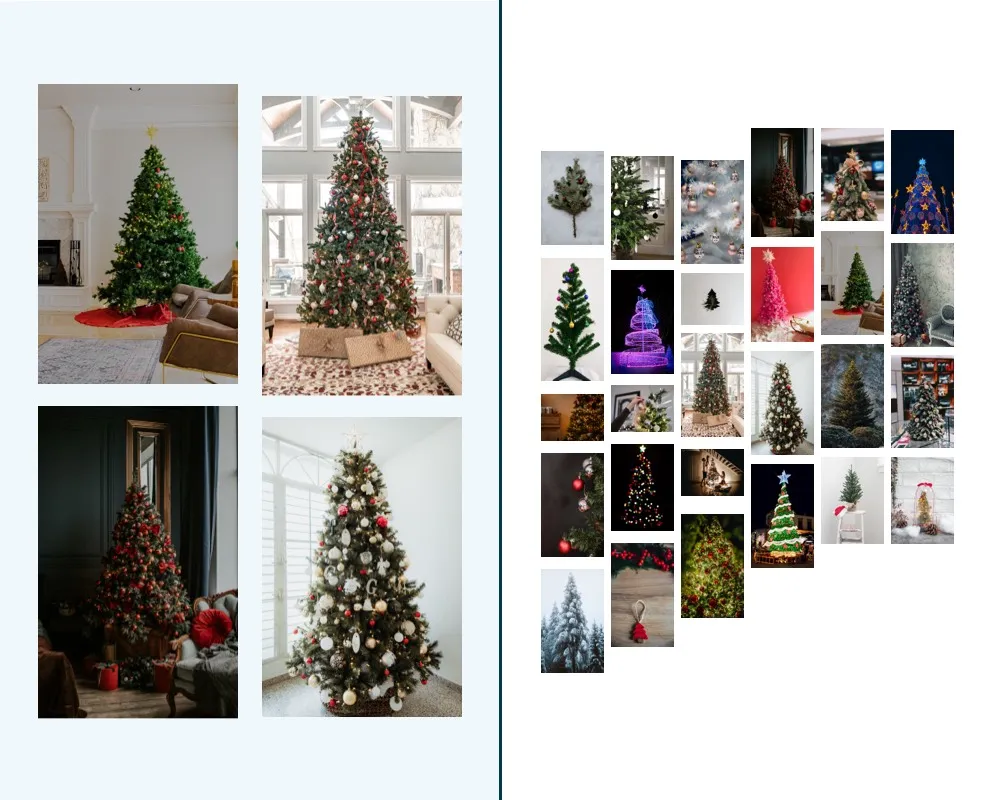
What is a sufficient dataset depends entirely on the acceptance criteria for your model.
We cannot say much based on a couple of observations, but how many is then enough? Here comes the definition of good enough for business and the statistical significance. If your model predicts Christmas trees from images 50/50 chance, that isn’t better than just randomly selecting images. But is 60/40, 70/30, or 99/1 enough? Well, that depends on the problem you are trying to solve. Defining that is again a joint exercise with the domain expert.
You can also use the idea from a sample size calculator to define how much is enough for calculating statistical differences between groups. Or think of doing A/B tests, which let you see whether there’s actual evidence that these are different and there’s a point in trying to predict something.
Your dataset should be representative
So you figured out the perfect dataset representing the problem to tackle with the domain expert. OK, now it’s time to check whether it is representative of the real world as well i.e. compare your data to the real world.
Good old tools like descriptive statistics get you a long way with numerical data, but you can also leverage some of it for the images. Nowadays, you don’t have to inspect the data manually because there are tools visualizing your data and calculating KPIs for possible drift.
For example, you can use libraries such as pandas profiling. Or, if you’re down to MLOps world, you can automatically track your datasets with observability tools such as WhyLabs, which offers a data tracking tool that automatically describes your dataset. You may want to check out our article on Whylabs.
For our Christmas tree example, maybe you want to detect resolution, orientation, or brightness following this example.

Your dataset will look drastically different if you expect your subject to always be unobstructed, well-lit, and in focus. Remember, these criteria may change when your model is in real-world use.
A dataset that represents the real world on day 0 may not convey it in the future, which is why checking drift is a continuous process. A change in the underlying data should prompt you to create a new version of your training dataset and retrain your models. This means you need to be observing solutions that are already in production. You can read more about observability practices in another [blog post I wrote] (/blog/monitoring-data-drift/) a while ago.
Also, if you think about retraining your model, take a look at this infographic and do some exploring.
You should acknowledge the bias in your dataset
This is heavily related to the representative dataset, but I wanted to give this extra attention. Your dataset is biased. Always. Because the problem you defined is human-made, your data will likely be curated and labeled by a human too. It is just a thing you need to embrace and aim for a less biased dataset.

Your dataset will look different based on who assembled and labeled it. Be aware of your own biases.
The first thing is to check your prejudice. As you are probably quite blind to it, a good way to make your dataset less biased is to use two independent labelers to label your dataset, preferably even with different backgrounds. For example, maybe your domain expert likes only the classic white lights Christmas trees and ignores the ones with blue lights, or gives labels as ‘ugly’, ‘small’, or ‘pretty’.
A biased dataset leads to biased predictions, and the impact of bias can be highly harmful depending on the use case. Especially in finance and healthcare, regulators are waking up to the threat of algorithmic bias (which often is directly derived from biased datasets), and which often affects negatively the already disadvantaged people.
Aligning business expertise, representativeness and bias knowledge with high volume of data
Jean-Emmanuel Wattier from Ingedata explains:
Preparing large training sets implies extra challenges to access domain experts, understand dataset bias and ensure representativeness. While managing a few hundred data points is okay, how can you make sure that the training data was correctly prepared when there are thousands of them? Domain experts are key but they are also scarce resources. So attracting, federating and retaining them requires team management skills that are not as crucial in the other stages of the machine learning pipeline.
Let’s take an example: one of Ingedata’s clients develops an AI model to detect tumors in liver imagery. One of the most scarce resources in the world is needed to build the training set: Radiologists.
-
First of all, a strong CSR (corporate social responsibility) approach that ensures their well-being and professional development is crucial to attracting them.
-
Secondly, managing people who are busy at the hospital requires skills that differ from what you recruit a Data Scientist or a Machine Learning engineer for.
This is the reason why they needed Ingedata to deploy a team of Radiologists in a short timeframe, with an agile approach to adapt the solution according to their evolving needs while maintaining a maximum level of security.
And since Radiologists are expensive, workflow decisions are validated by a prototype to make sure every minute of their time is worth the cost. The prototype confirms that quality control, data representativeness, and reporting methods are aligned with the volume of data to be prepared and the availability of the domain experts.
This situation occurs not only in the Health sector but also in Earth Observation, Industry, Fashion and Smart Cities. The more insights you want to extract from the data, the more specific domain expertise is, the greater these challenges are.
Summary
Embracing the data-centric AI doesn’t take more than focusing as much on perfecting the data-related processes and steps as you already do with your machine learning model. Data is 80% of the AI system and thus a strategic asset for any domain or organization. Setting up your data workflows with well-deserved attention by adding some observability, MLOps practices, and including that domain expert in the loop makes a huge difference.
This article was written with the contribution of Ingedata. Ingedata, a partner company of Capgemini France, provides access to over 500 specialized employees for complex data annotation. Since 2019, they have been involved in over 100 data preparation projects in Computer Vision, NLP and Structured data.