
The bus factor is a common term in software engineering describing the risk of a key contributor disappearing unexpectedly from a project – because they get hit by a bus. While it is a well-documented problem for classical software development, machine learning magnifies the bus factor significantly.
In ML, in addition to code that is often somewhat self-documenting, there is data. A single data set can contain vast amounts of hidden information about how it’s been collected and then how features are extracted. There may be many versions of notebooks or scripts that produce a single data set.
Loss of knowledge can happen in many different ways. Most obviously by a data scientist leaving the company, and most larger teams have already faced this. But it can also occur without personnel changes. When you work on multiple projects over a more extended period, you tend to forget details about your own work too. It can be challenging to return to a six-month-old project and retrain a model without breaking things. Many readers may have existing models running that they dread getting back to for fear of breaking something.
For traditional software development, reproducibility is mostly taken care of by proven version control tools like Git. To achieve proper version control and reproducibility for ML, you will need a bit more on top of that.
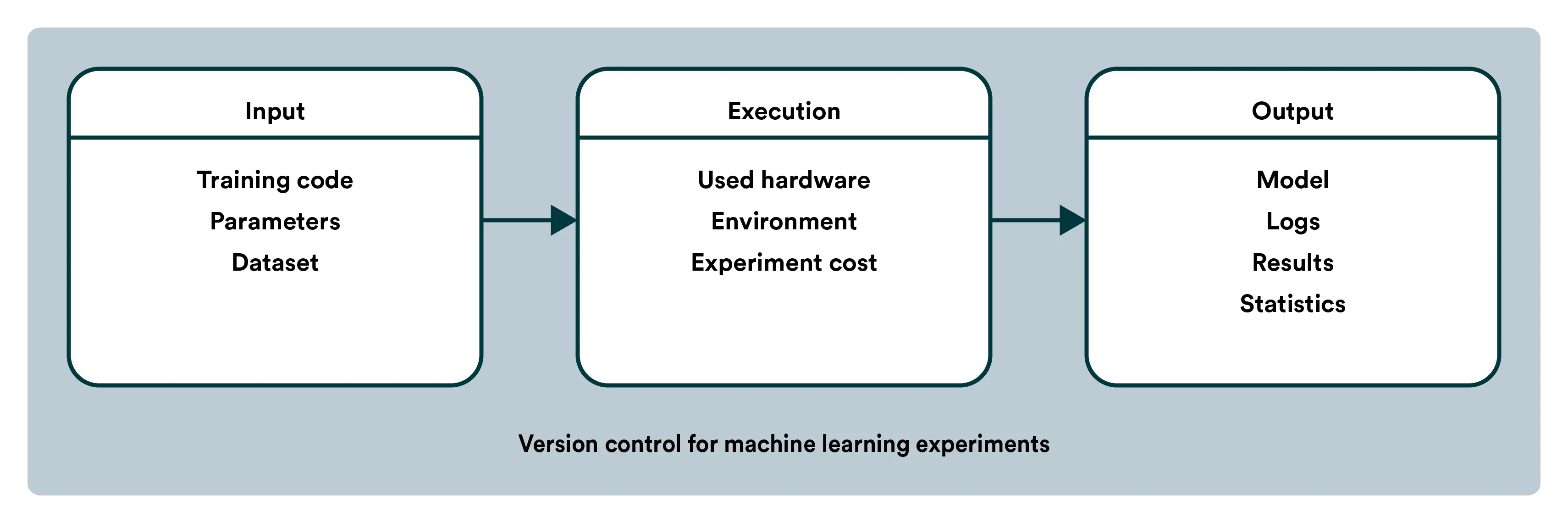
In ML, a model is a combination of code, data, parameters, and the training environment. To pick up where someone else (or yourself six months ago) left off with a model, you’ll need much more than just a Git repository.
You need to know what data the code is using and how that data came to be. There are often multiple scripts bringing together different data sources and doing feature aggregation to build the dataset you need. Putting together the puzzle of several scripts and data sources someone else made leaving behind zero documentation can often be more complicated than just starting from scratch. To tackle the bus factor, the first part should be adopting a few core principles of MLOps within your team, namely that machine learning should be continuous and reproducible. If everybody acknowledges these, then adopting the required tooling should be relatively easy. An end-to-end MLOps platform, like Valohai, can track your whole pipeline from raw data to the model, including your code, environment, configurations, and parameters.
This blog post is an excerpt from our eBook on MLOps. It’s free, just sign up below.