 We all understand the importance of reproducibility of machine learning experiments. And we all understand that the basis for reproducibility is tracking every experiment, either manually in a spreadsheet or automatically through a platform such as Valohai. What you can’t track what you’ve done it’s impossible to remember what you did last week, not to mention last year. This complexity is further multiplied with every new team member that joins your company.
We all understand the importance of reproducibility of machine learning experiments. And we all understand that the basis for reproducibility is tracking every experiment, either manually in a spreadsheet or automatically through a platform such as Valohai. What you can’t track what you’ve done it’s impossible to remember what you did last week, not to mention last year. This complexity is further multiplied with every new team member that joins your company.
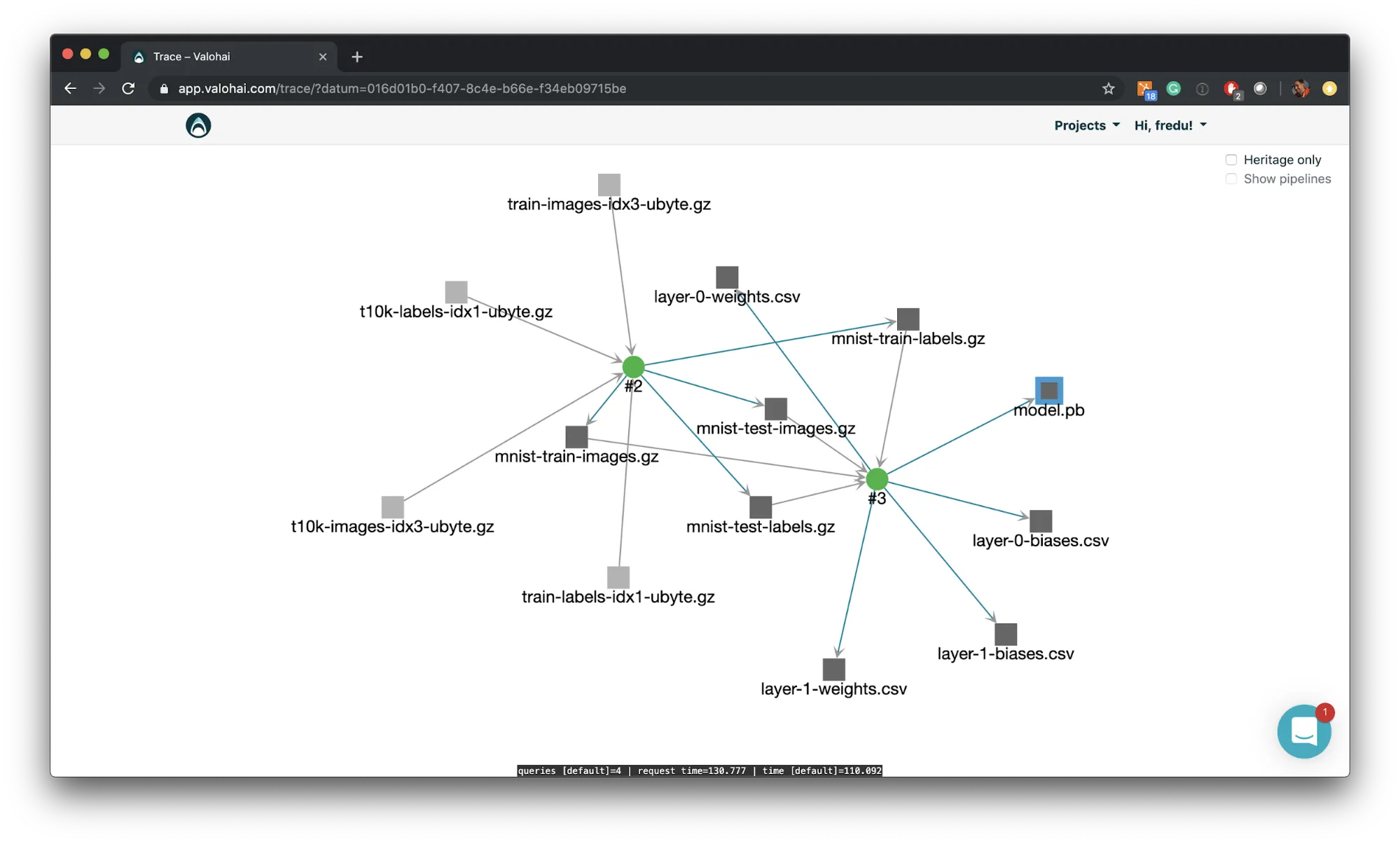
Data provenance is a related problem but done for the same governance reasons. Unlike a single atomic experiment, an end result of a pipeline can go through tens of transformations and training combinations. For example the ML pipeline below, where the end-result in Inference is the result of several scripts and data sources. To see the full data lineage you’d like to see the exact scripts and intermediary results from the inference model all the way to the original data sources.
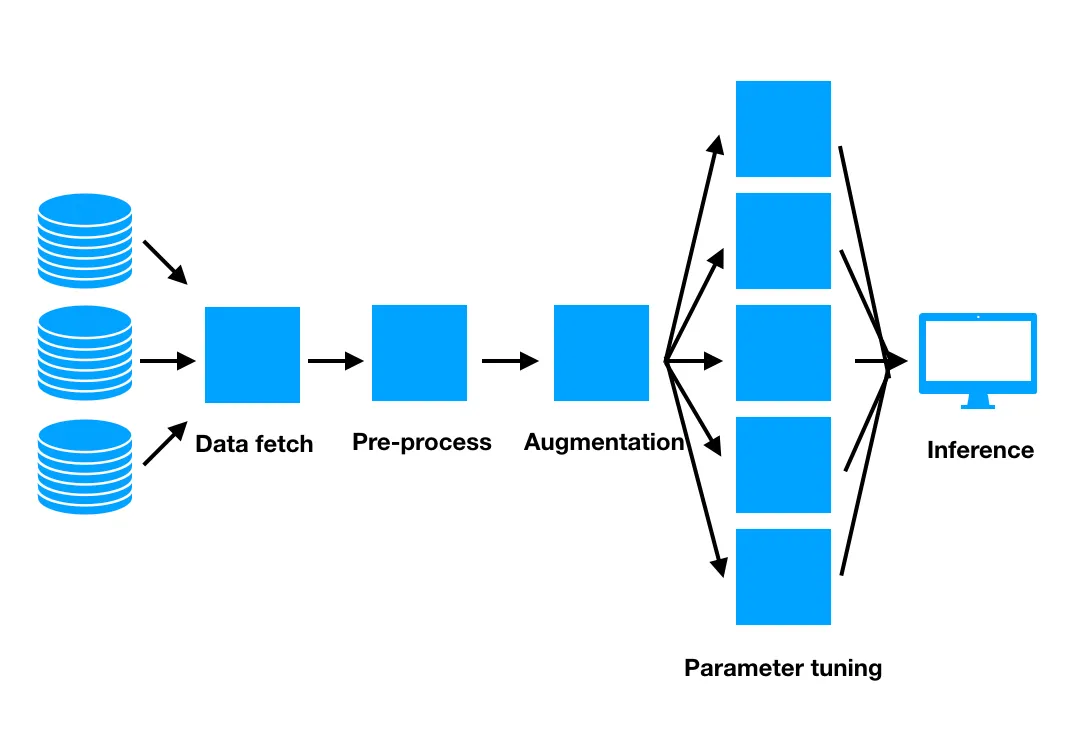 We’re happy to announce a data heritage view for Valohai today! Pick any data asset (model file, preprocessed data, statistics file, Jupyter notebooks ipynb file etc) and see what scripts, steps and data sources it originates from! This lets you backtest models on older data sets, check out team members’ datasets and pipelines and give you full control over the state of every asset in your pipeline.
We’re happy to announce a data heritage view for Valohai today! Pick any data asset (model file, preprocessed data, statistics file, Jupyter notebooks ipynb file etc) and see what scripts, steps and data sources it originates from! This lets you backtest models on older data sets, check out team members’ datasets and pipelines and give you full control over the state of every asset in your pipeline.
A data heritage view is paramount for debugging your ML projects, which is why it was asked for by many of our customers. After a closed beta period we’re now happy to make it public to everyone.
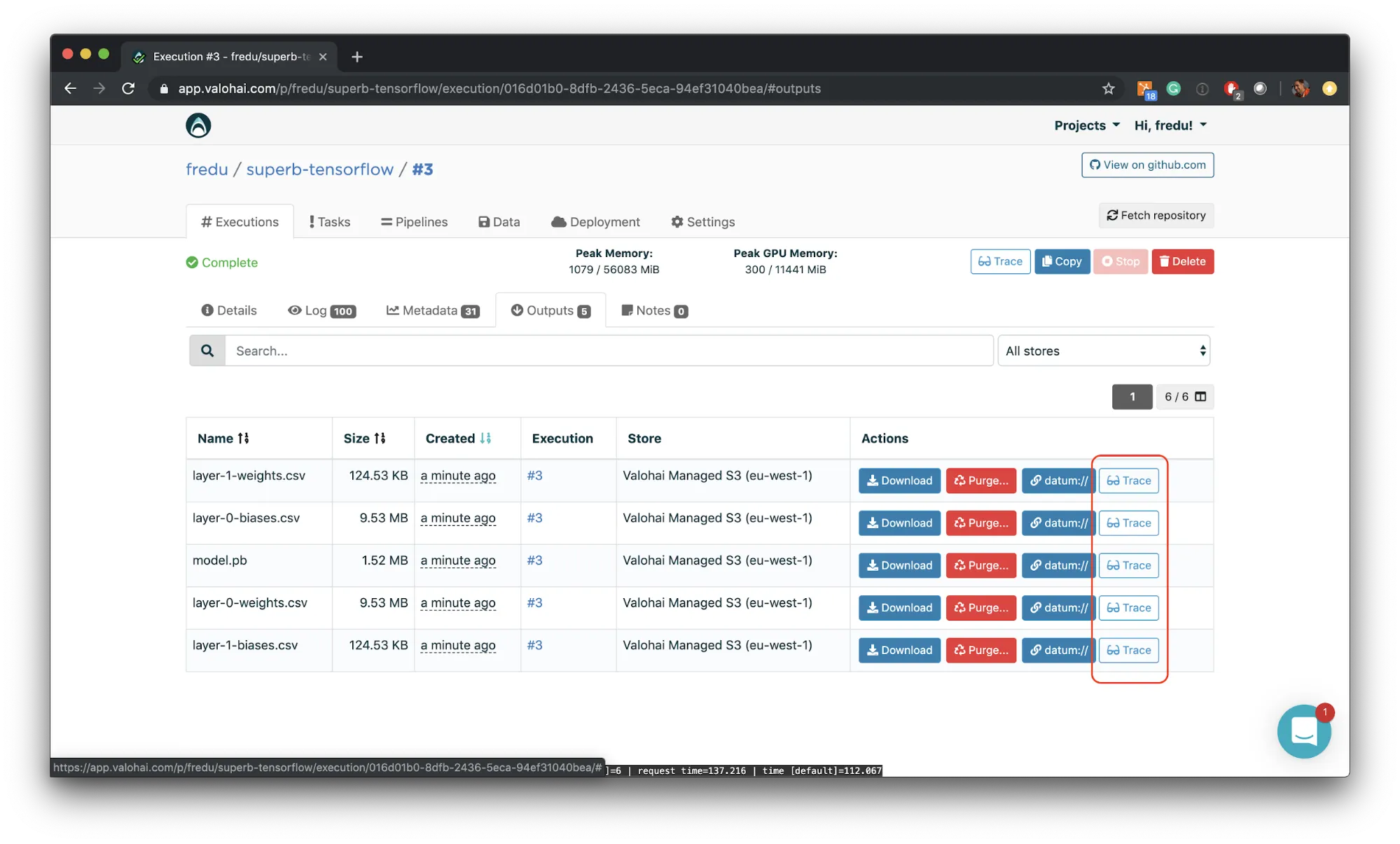
You can find this feature from underneath the “Trace” button next to your list of Data in the Valohai UI. The data tab can be found on the project level but also underneath every experiment you’ve done. The graph is dynamic and you can move it around with your mouse to quickly understand the provenance of any result you’ve derived at. Check it out by signing in to your own Valohai account now !