They say data is the new gold. But without a data catalog, your data is just scattered around like random nuggets of gold in a desert full of rocks, pebbles and sand. Data catalogs help you keep track of the data you have but also, in the case of machine learning models, what data has affected which model. Data brings meaning to machine learning because unlike software, machine learning models are 90% data and 10% code.
Organizations are building more and more machine learning models and the models will be using different snapshots of data. Knowing what data went into which model is a problem that needs to be solved beforehand – it’s not something you can glue on top afterwards. Data changes can only be tracked when they happen, not afterwards.
One could say that data catalogs are just a nice-to-have feature outside the scope of machine learning, but building and managing machine learning models are where data catalogs really shine. There’s a hint in the title of people building machine learning models; they’re not called Data Scientists in vain.
A data catalog should fulfill at least the following requirements:
- support automatic population of data,
- be searchable,
- be auditable,
- support tracking of changes and
- provide access through an API for integration.
Below we will go through each of these five requirements and show how the Valohai ML platform solves them.
Automatic population
The essence of any tracking solution is that it should be automatic. If you’re going to require your data scientists to track their data and experiments in a spreadsheet, you might as well give up.
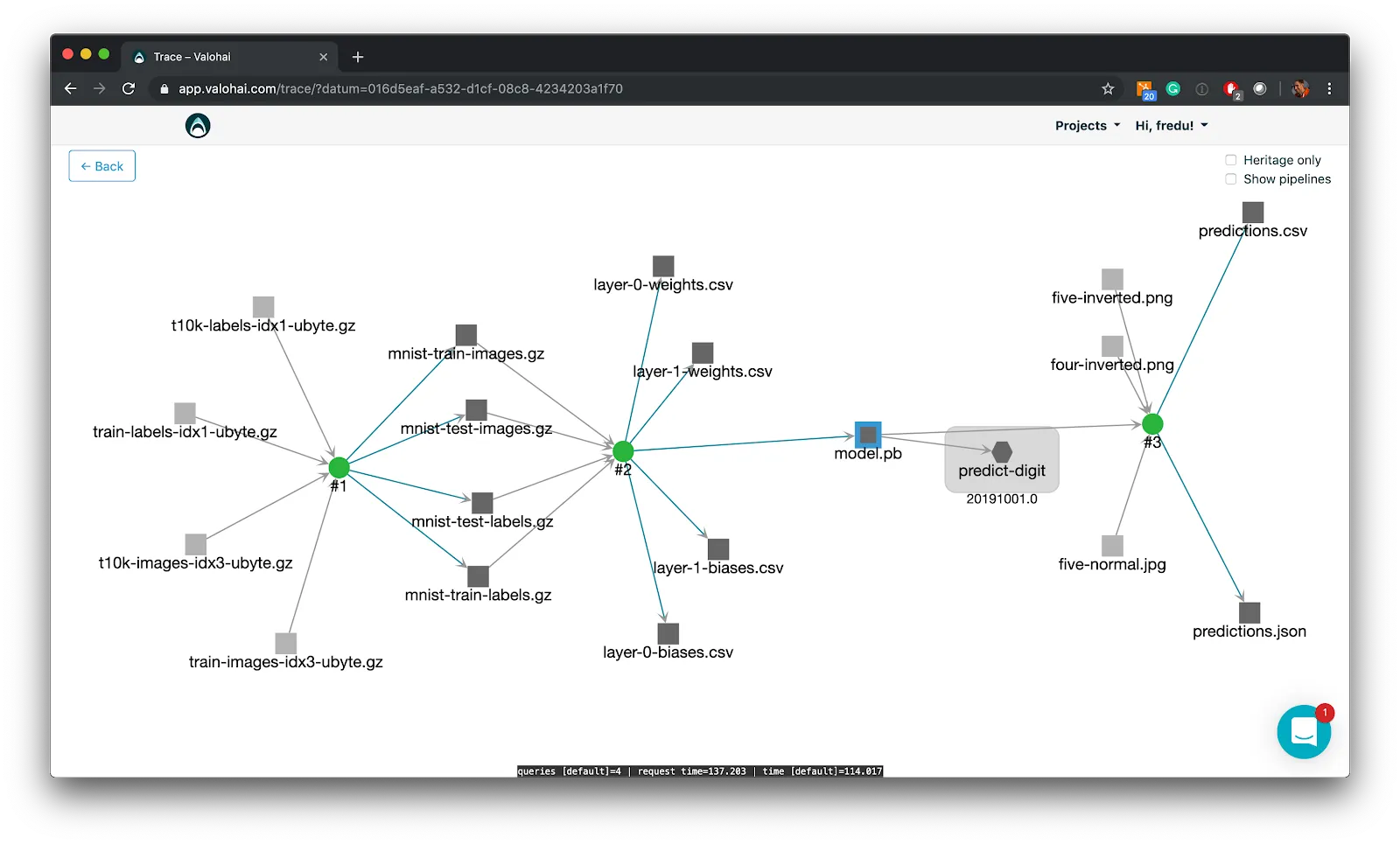
Valohai automatically tracks every data asset you use in training a model. Imagine a pipeline that takes in data from a Spark cluster, augments that with data from an S3 bucket of flat files, normalizes these, trains a hundred models, selects the best one and deploys the model. Valohai shows you a tree representation of the data from the end-result all the way through every step into the original data and you can dive into any intermediary data asset and check them out. Valohai also stores the sha and md5 hashes of the data so you’ll know if the data under the hood has changed.
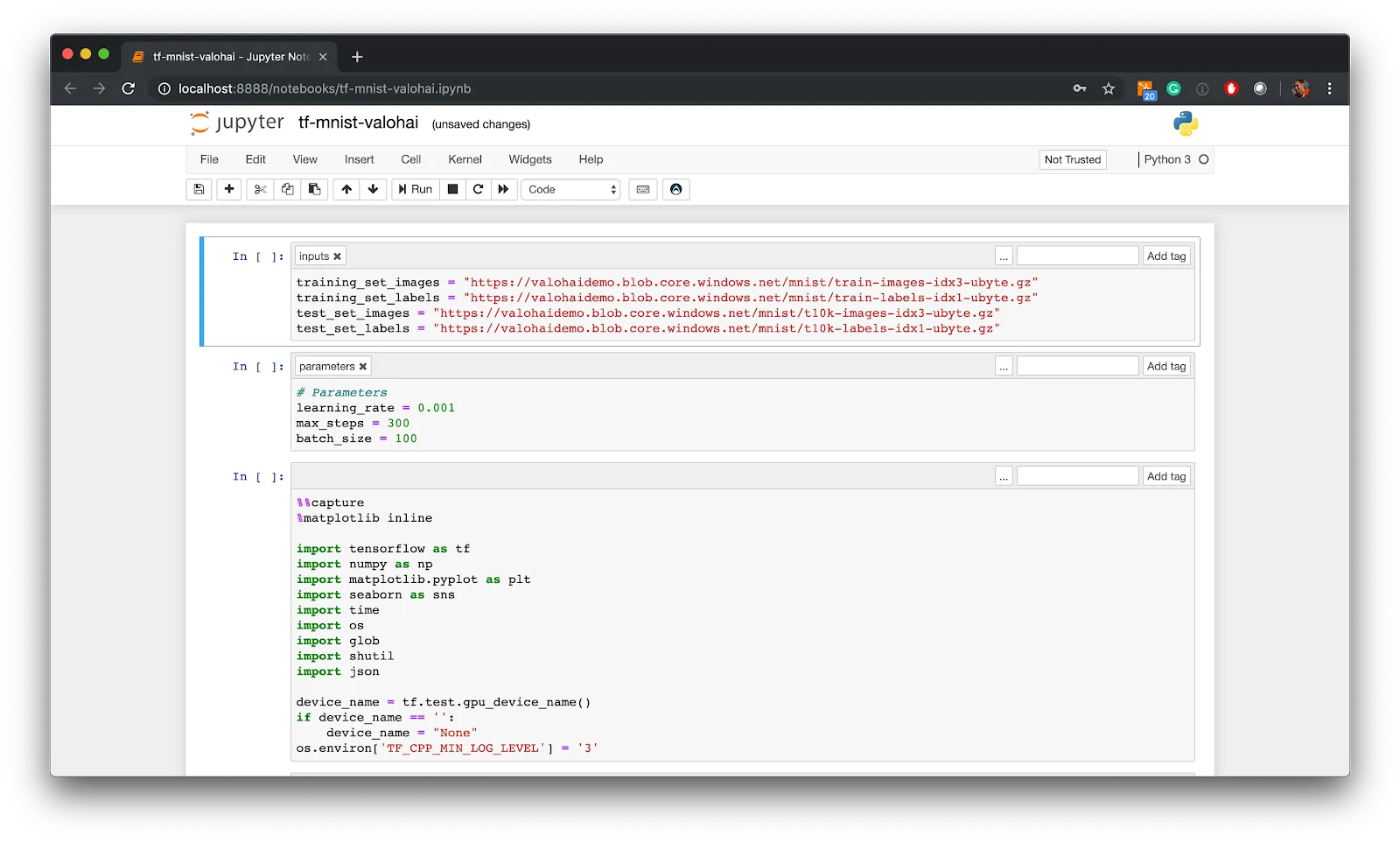
Searchable
A data catalog that isn’t searchable based on type, creation type or connection to other data or models is as worthless as a degree from Trump University.
Valohai has powerful built-in search functionality for letting you find the data asset among all your input and output data files or directly in connection to a model, an experiment or a step in the ML pipeline. Valohai search works inside the built-in access controls and allows you to search everything you can access. This can be private, team level, company-wide, or however you choose to set the limits in your company.
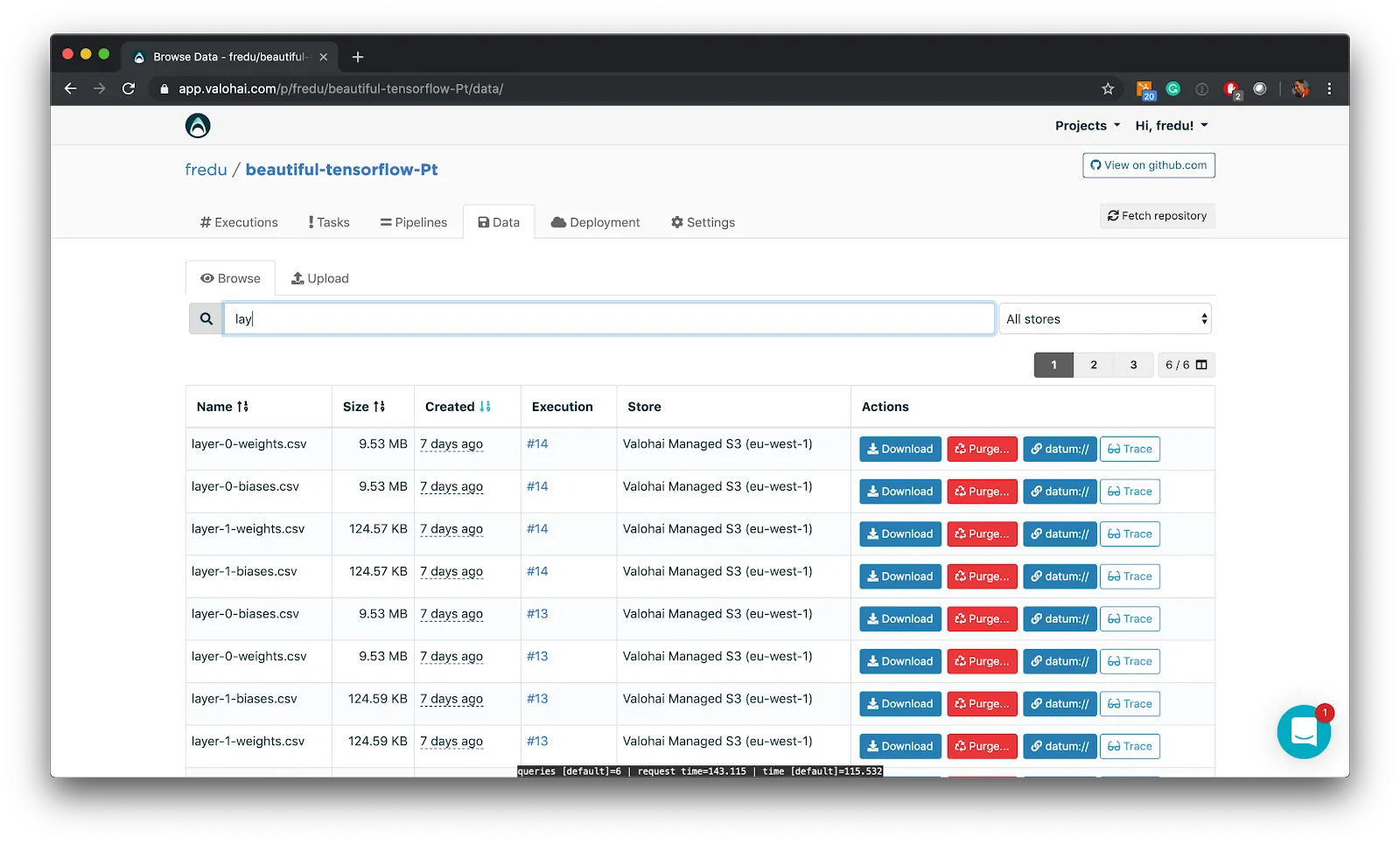
Auditable Data Lineage
Machine learning models are the result of complex sets of pipeline steps and data transformations. Your data is normalized, transformed, anonymized and checked for bias. Every intermediary step needs to be tracked in order to be able to prove lineage from the original source to the final model.
Because of Valohai’s built-in automatic data tracking, every transformation and its result is stored. But not only the input and the output are stored – you’ll also have the exact code that transformed the data so that you can check what has happened. Valohai’s data lineage functionality lets you easily plot the history of a model’s lifetime and dive into any asset or transformation at the click of a button. Never before has data auditability been this easy!
Tracking changes
Data changes. That’s just a fact. And because of that, you will be building new and better models that comply with the new data. You need to be able to track the lifetime of a model and how its data has changed. A model that was in production 12 months ago and was trained on data from 18 months ago will be completely different from the model built today on data from 3 months ago.
Valohai tracks every model. Period. We could write more about how we do this but it would just be a repetition of what we’ve already said: We track everything. Automatically. Full stop.
Access API
Data is your most valuable asset, so you shouldn’t rely on a monolith system you can’t get rid of. Backups, integrations, private cloud installations et.al. are all good starts, but an open API will let you stay calm because you can integrate the data catalog into any external system and tack backups of everything within the catalog.
Valohai is built on a 100% open API which you can use to take external backups (if the ones we do aren’t enough) or your private cloud / on-premises installation doesn’t convince your security team. Everything within the platform can be exported into your own database and you can migrate to another system at any time. But let’s face it: Why would you?
How do you get started with creating a data catalog?
Because you’re reading this you’re already 50% there. The other 50% can be achieved by contacting us for a free demo on how to build a data catalog. It’s never too early to educate yourself and even if you did choose to continue as you are today, at least you’ll know what the pros and cons of a managed data catalog is, after a private demo with us.