What Is Model Deployment?
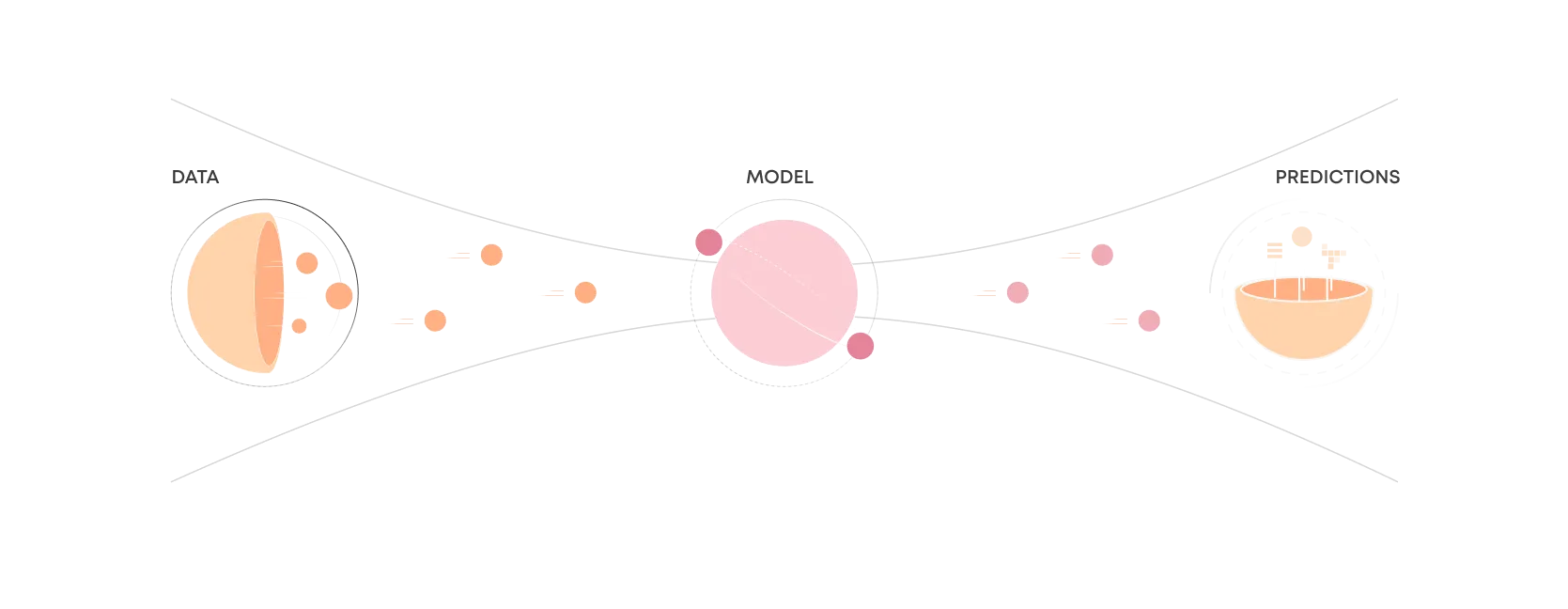
Model deployment is simply the engineering task of exposing an ML model to real use. The term is often used quite synonymously with making a model available via real-time APIs. Still, we should think about model deployment more broadly – as online inference in the cloud isn't always a necessary or even a desirable solution.
This article will walk through the key considerations in model deployment and what it means in different contexts. In the end, we'll show examples of two use cases in our MLOps platform, Valohai.
Glossary
- Deployment: The engineering task of exposing an ML model to the rest of the world.
- Inference: The model's computational task of transforming questions into answers.
- Testing: The engineering task of building automated tests to verify baseline functionality and infrastructure robustness.
- Monitoring: The supervision of the model's health and performance once deployed.
How Should I Think About Model Deployment?
The first question solving the puzzle is whether your model needs to provide answers instantly using the latest data in real-time (online) or with some accepted latency (batch). The second question is whether to internalize the computational resources (cloud) or crowdsource it to users (edge). Answers to these questions set the stage for all the other decisions that follow.
The online inference is like batch inference on steroids. The requirement for instant answers with the latest data limits your options and puts extra pressure on computational resources and monitoring. Consider the difference between filming a movie or a live TV show. You can always stop everything in a movie set (batch) and do another take without compromising the final product. In a live performance (online), you have to act fast, be alert, and have a plan B ready at all times.
Deployment
60% of models never make it out into production. One of the key hurdles is the difficulty of transforming something that works in a laboratory environment into a reliable public service.
Some companies think about deployment as a process where a proof-of-concept created by a rogue data scientist is meticulously rewritten and handcrafted into an optimized cloud serving endpoint by the hero software engineers. This is the wrong mindset.
The right mindset is to build an automated pipeline, where the problem is split into smaller components. Data scientists focus on the components, and software engineers focus on the pipeline. By default, these two parties do not speak the same lingo, so the platform they choose needs to introduce a common language in-between. Deployment in this environment is a simple click of a button or even something completely unsupervised.
Key questions:
- Is the model deployment pipeline automated?
- Is the new model better than the old ones? How to make sure?
- What are the fallback mechanisms? Are they automatic?
- Does the development environment match the production environment?
Inference
The inference is the act of transforming questions (input) into answers (output). It is not enough to have a model that can do that. The model needs an infrastructure around it.
The input needs to come from somewhere. The model requires computational resources and its logs and metadata need to be captured and stored. Finally, the output needs a channel back to the customer. Especially for online inference, all these various components need to scale along the unpredictable live traffic automatically. Usually, this means building your endpoint on top of a scalable framework like Kubernetes.
Edge inference is when the model lives on the customer's hardware (think mobile phone). The upside of edge inference is that computation is free. There is near-zero latency; the downside is that the environment is out of your control, and problem-solving can sometimes be outright impossible.
Key questions:
- Online inference or batch inference?
- Cloud deployment or edge deployment?
- What happens with sudden 10x demand? What about 1000x?
- What is the maximum acceptable latency?
Testing
Testing is an engineering task of building automated tests to verify baseline functionality and infrastructure robustness. The purpose of the tests is to act as a smoke test for any modifications and to ensure that the infrastructure will keep working as expected. Tests will also have a documentation purpose. They reveal the expectations and assumptions of the original author.
Testing is very similar to its software engineering counterpart, but some differences exist for building a testing suite in the ML context. Models themselves are often untestable black boxes. Testing needs to focus heavily on validating expectations about data and the infrastructure's reproducibility. For online inference, put extra effort into testing the fallback mechanisms.
Key questions:
- Is the training pipeline reproducibility tested?
- Are the fallback mechanisms tested?
- Is the model's inference performance tested?
Monitoring
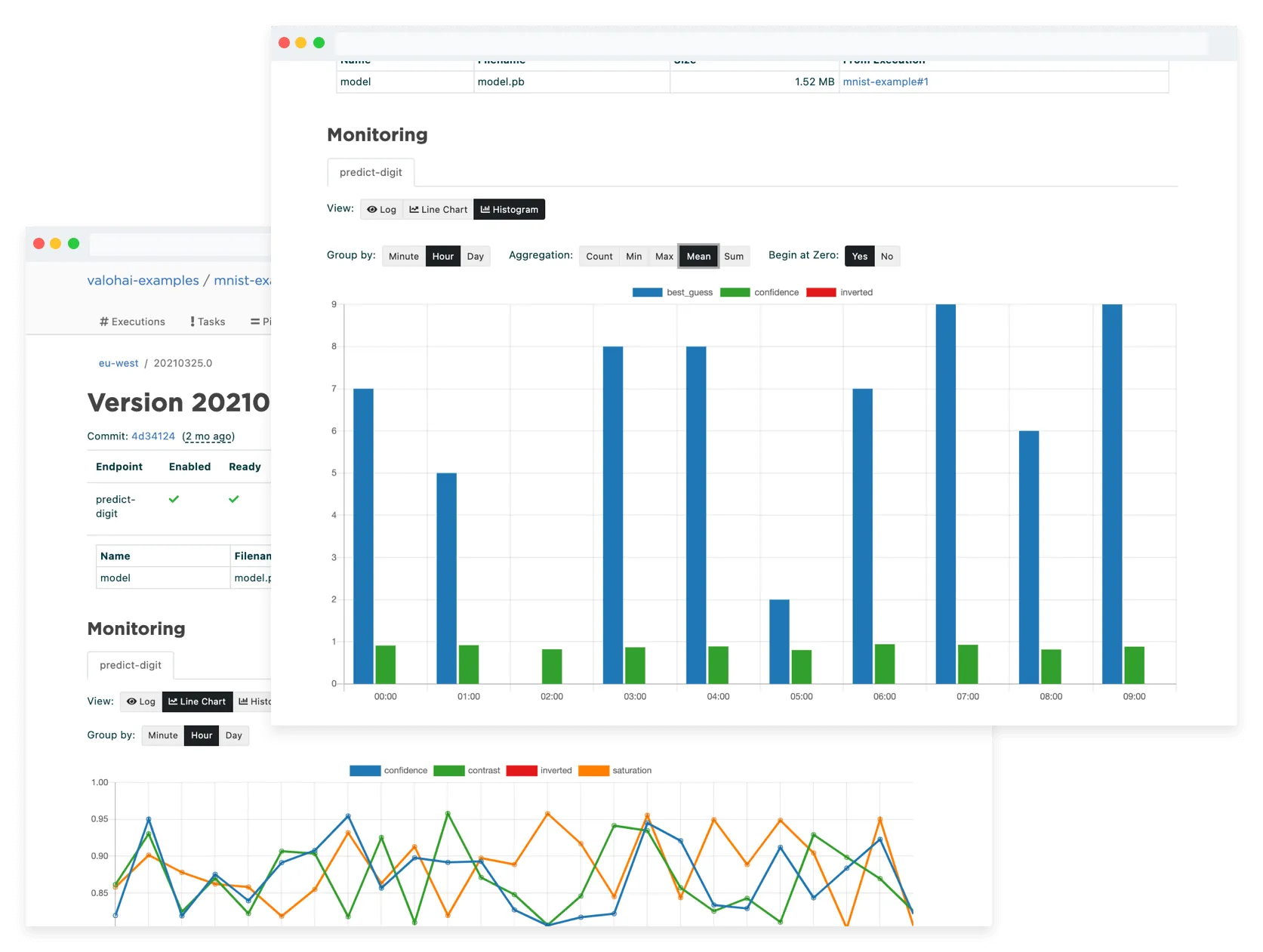
Monitoring the health of the model is as vital as it is to test it beforehand. Again, the black-box nature of the model introduces challenges for monitoring its health.
The most time-pressing need is to monitor the health of the infrastructure. Enough computing resources? Enough bandwidth to move data around? What is the total latency? When things go wrong here, they go wrong fast. The day your product goes viral might account for 99% of your yearly traffic.
The less time-pressing need is to monitor the health of the model itself. Models are trained with data, and the predictive power is bound to the quality of data. As time goes by and the world changes around the model, its accuracy starts to plummet eventually. This phenomenon is called "drift," and it can be monitored and even used as a trigger to retrain the model. Data should also be monitored and compared to the data of yesterday. Have the statistical properties of the data changed? Are there more or different outliers than before?
Key questions:
- When the model eventually starts to drift, is it detected?
- When the data changes unexpectedly or has outliers, is it detected?
How to Deploy a Model for Batch Inference with Valohai?
A use case for batch inference would be for example customer scoring which doesn't have to be run all the time but it can be done once a day. In this type of setup, it would make sense to have a model training pipeline and a batch inference pipeline. The actual model deployment is done simply by the fact that the batch inference pipeline uses the latest (or best performing) model the training pipeline has produced.
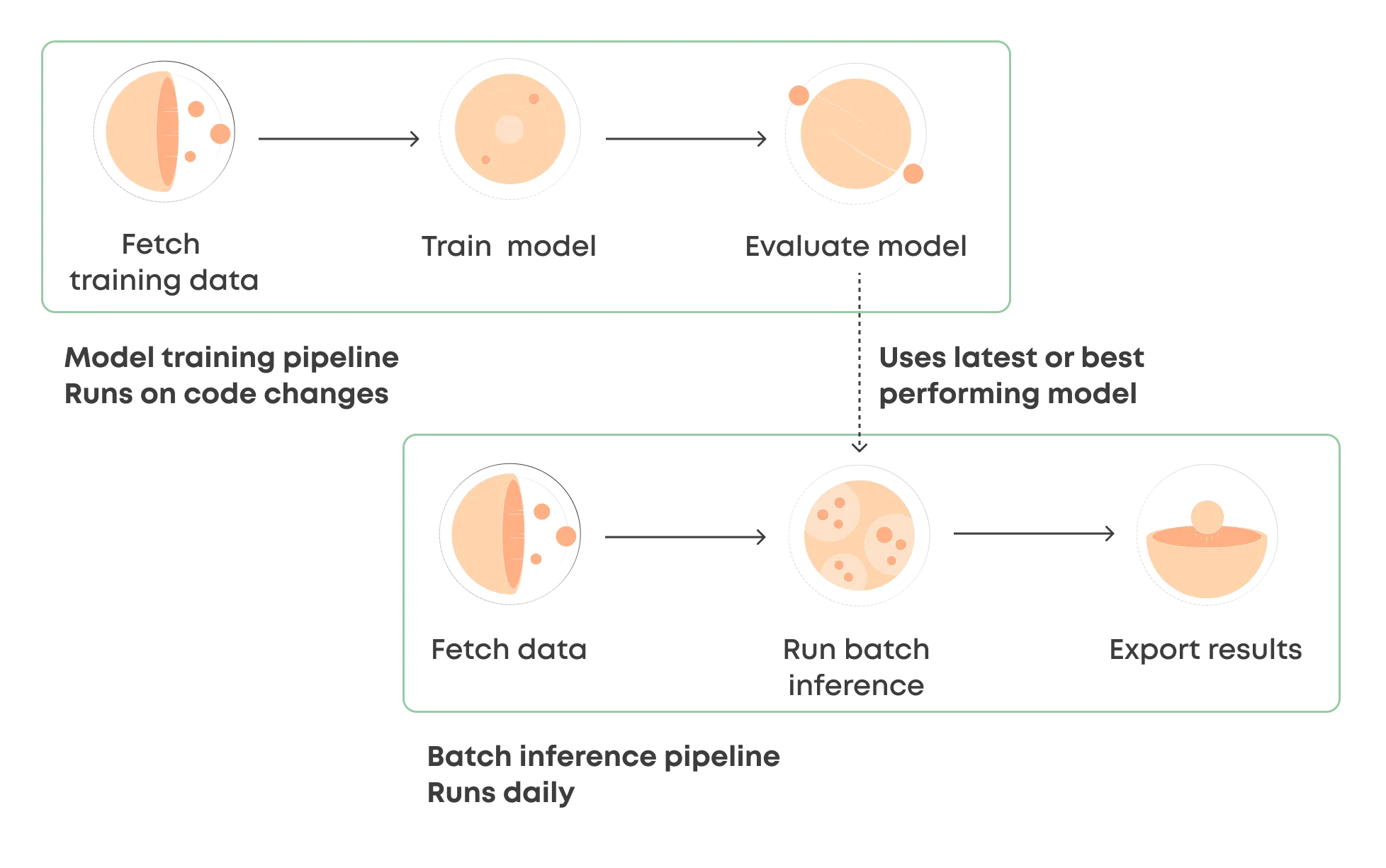
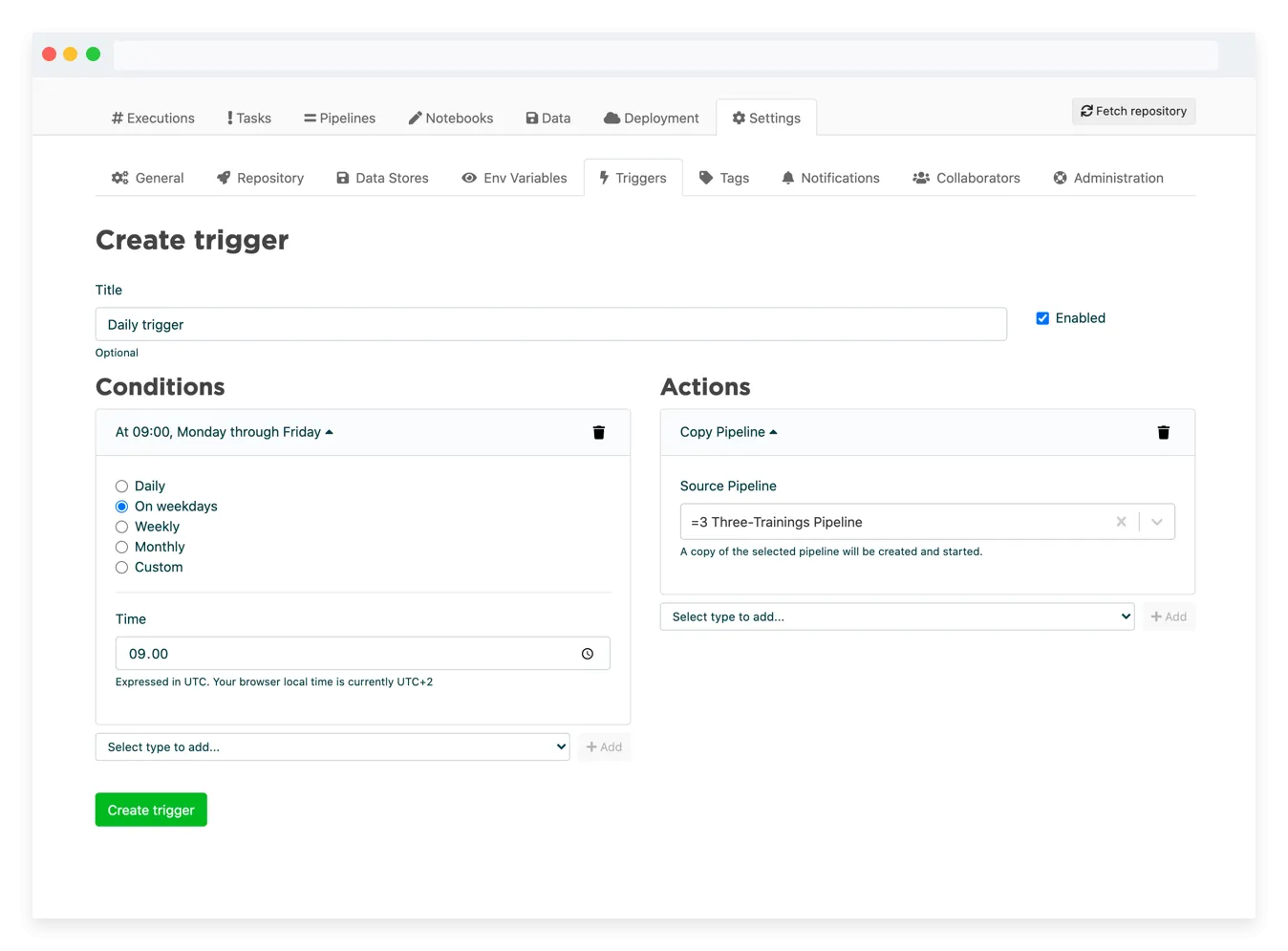
In Valohai you can define two pipelines into the same project and these pipelines can be triggered differently. For example, the model training pipeline can be triggered whenever there's a new version of the model code in Git (via GitHub Actions) and the batch inference pipeline can be triggered automatically every midnight (via the Valohai scheduler).
Valohai Scheduler
Example pipeline definition in Valohai
- pipeline:
name: Three-Trainings Pipeline with deployment
nodes:
- name: preprocess
type: execution
step: Preprocess dataset
- name: train
type: execution
step: Train model
override:
inputs:
- name: training-set-images
- name: training-set-labels
- name: test-set-images
- name: test-set-labels
- name: evaluate
type: execution
step: Batch inference
edges:
- [preprocess.output.*train-images*, train.input.training-set-images]
- [preprocess.output.*train-labels*, train.input.training-set-labels]
- [preprocess.output.*test-images*, train.input.test-set-images]
- [preprocess.output.*test-labels*, train.input.test-set-labels]
- [train.output.model*, evaluate.input.model]
- [evaluate.output.*.json, find-best-model.input.predictions]
- [evaluate.output.model*, find-best-model.input.models]
- [find-best-model.output.model.pb, deploy.file.predict-digit.model]
Also see the comparison between batch and realtime inference on our docs site.
How to Deploy a Model for Online Inference with Valohai?
A use case for online inference would be for example a recommendation engine where the user inputs need to receive corresponding predictions. The model needs to be available via an API endpoint 24/7. In this type of scenario, you would define a Valohai pipeline that trains, evaluates and deploys a model automatically. Valohai deploys your model to an autoscaling Kubernetes cluster and allows you to output any metrics you need.
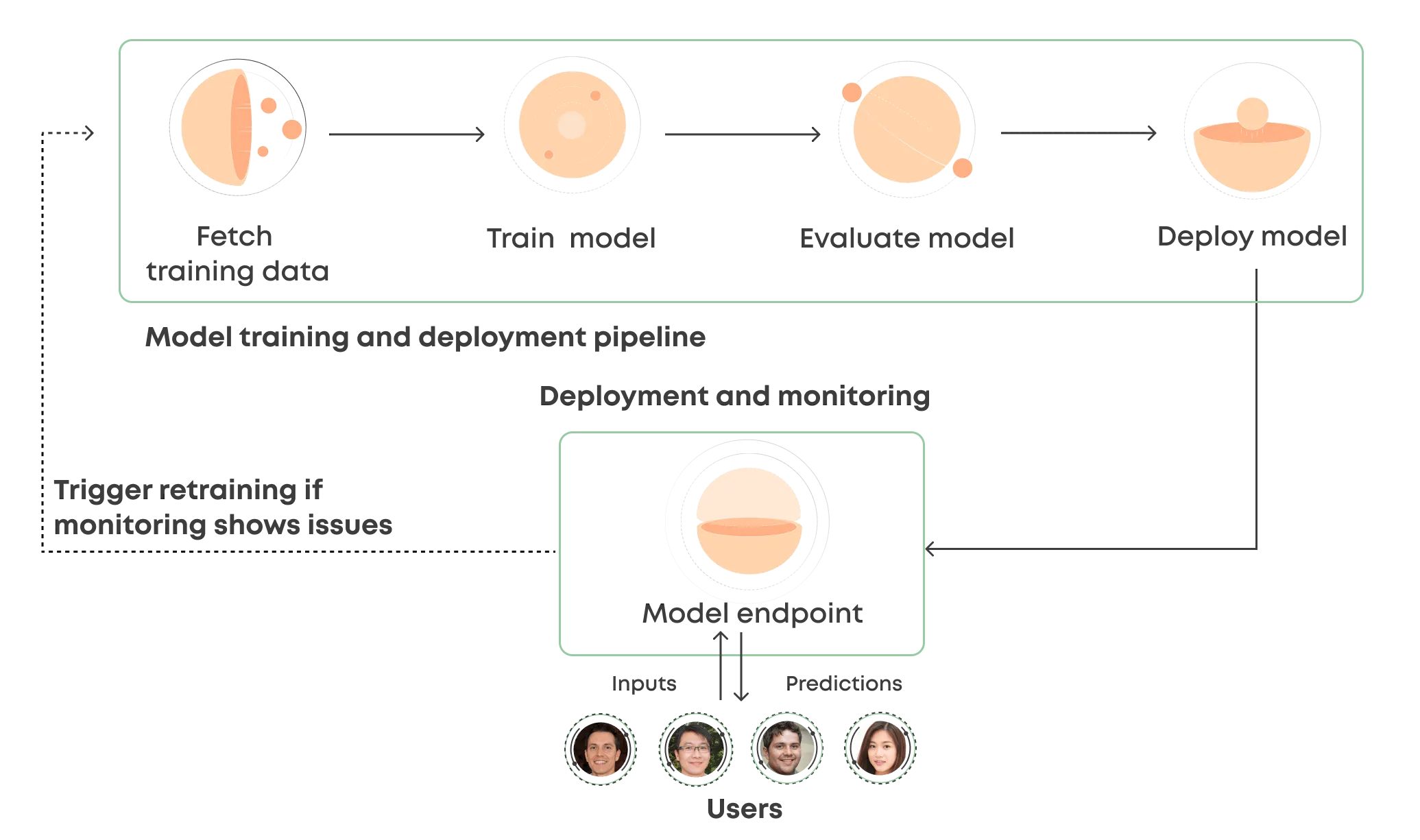
The monitoring in model deployments allows you to trigger the model training pipeline if your metrics show a degrading performance of the deployed model ensuring that you can always serve the best possible predictions to your users.
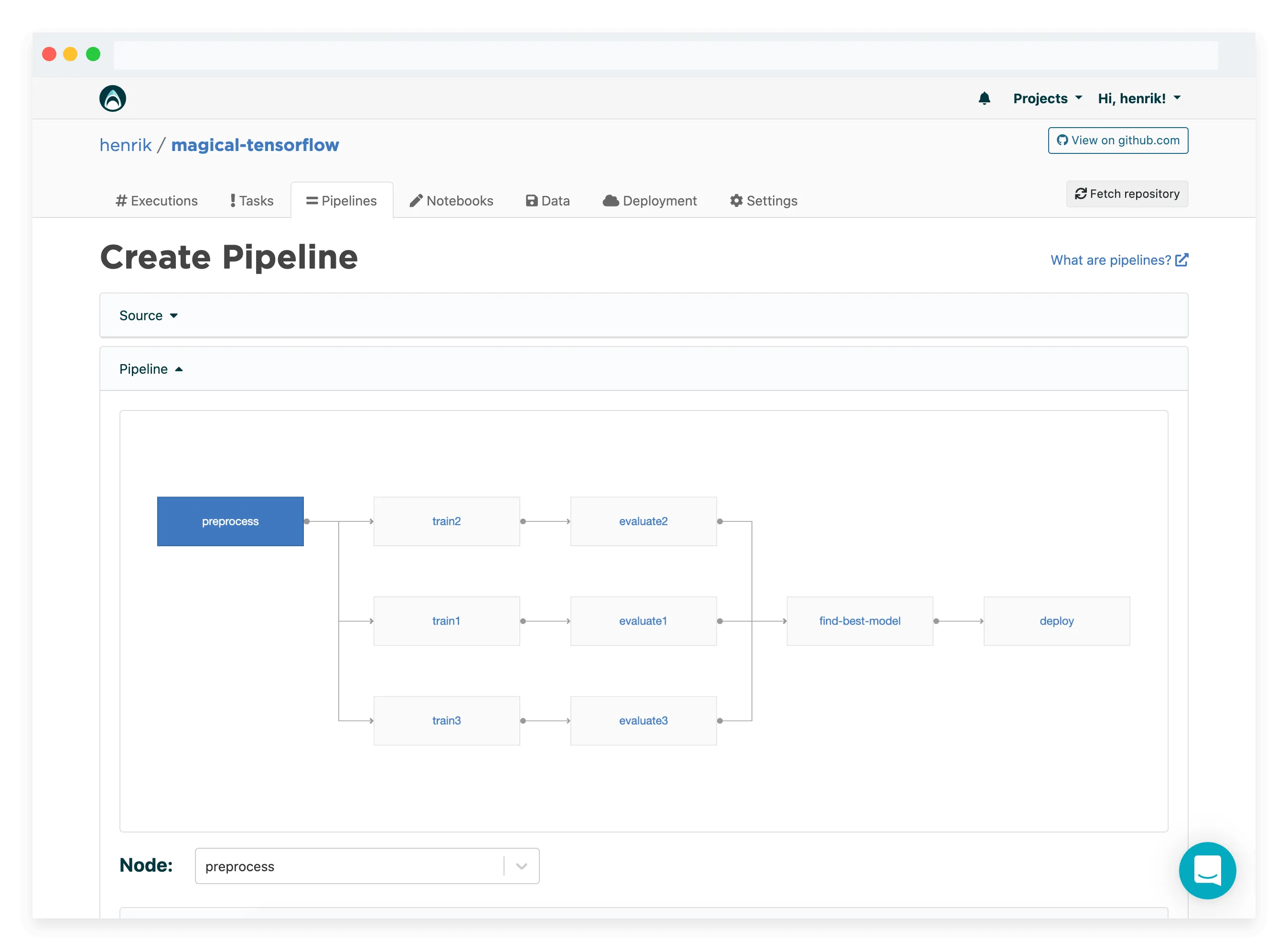
Valohai Pipeline
Valohai Monitoring
Example pipeline definition in Valohai
- pipeline:
name: Three-Trainings Pipeline with deployment
nodes:
- name: preprocess
type: execution
step: Preprocess dataset
- name: train1
type: execution
step: Train model
override:
inputs:
- name: training-set-images
- name: training-set-labels
- name: test-set-images
- name: test-set-labels
- name: train2
type: execution
step: Train model
override:
inputs:
- name: training-set-images
- name: training-set-labels
- name: test-set-images
- name: test-set-labels
- name: train3
type: execution
step: Train model
override:
inputs:
- name: training-set-images
- name: training-set-labels
- name: test-set-images
- name: test-set-labels
- name: evaluate1
type: execution
step: Batch inference
- name: evaluate2
type: execution
step: Batch inference
- name: evaluate3
type: execution
step: Batch inference
- name: find-best-model
type: execution
step: Compare predictions
- name: deploy
type: deployment
deployment: deployment-test
endpoints:
- predict-digit
edges:
- [preprocess.output.*train-images*, train1.input.training-set-images]
- [preprocess.output.*train-labels*, train1.input.training-set-labels]
- [preprocess.output.*test-images*, train1.input.test-set-images]
- [preprocess.output.*test-labels*, train1.input.test-set-labels]
- [preprocess.output.*train-images*, train2.input.training-set-images]
- [preprocess.output.*train-labels*, train2.input.training-set-labels]
- [preprocess.output.*test-images*, train2.input.test-set-images]
- [preprocess.output.*test-labels*, train2.input.test-set-labels]
- [preprocess.output.*train-images*, train3.input.training-set-images]
- [preprocess.output.*train-labels*, train3.input.training-set-labels]
- [preprocess.output.*test-images*, train3.input.test-set-images]
- [preprocess.output.*test-labels*, train3.input.test-set-labels]
- [train1.output.model*, evaluate1.input.model]
- [train2.output.model*, evaluate2.input.model]
- [train3.output.model*, evaluate3.input.model]
- [evaluate1.output.*.json, find-best-model.input.predictions]
- [evaluate2.output.*.json, find-best-model.input.predictions]
- [evaluate3.output.*.json, find-best-model.input.predictions]
- [evaluate1.output.model*, find-best-model.input.models]
- [evaluate2.output.model*, find-best-model.input.models]
- [evaluate3.output.model*, find-best-model.input.models]
- [find-best-model.output.model.pb, deploy.file.predict-digit.model]
The best of the best

MLOps in the Wild
A collection of MLOps case studiesSkimmable. Inspirational.
The MLOps space is still in its infancy and how solutions are applied varies case by case. We felt that we could help by providing examples of how companies are working with tooling to propel their machine learning capabilities.
Think of this as a lookbook for machine learning systems. You might find something that clicks and opens up exciting new avenues to organize your work – or even build entirely new types of products.
Download