State of MLOps 2021
What is MLOps?
Last year we conducted the State of ML 2020 survey. This year we repositioned the survey as the State of MLOps to reflect the domain covered and expand the questionnaire more towards tooling.
2020 was a clear breakthrough year for MLOps (machine learning operations) regarding the term's popularization. Consequently, a significant community of practitioners has evolved around the MLOps term ( mlops.community), and many vendors have positioned their offerings in the MLOps space. This space includes both vendors with end-to-end MLOps offerings (such as Valohai and SageMaker) and point solutions (such as Fiddler for observability or Tecton for feature store).
The Ops term is thrown around plenty in different contexts (DesignOps, PeopleOps etc.), and even in machine learning, several other Ops terms are used (AIOps, ModelOps, DataOps). Still, MLOps has emerged as a helpful category to describe topics about workflow and tooling for developing machine learning.
Demographics
For the State of MLOps 2021 survey, we collected 100 responses from the Valohai community. While the Valohai product offering is MLOps-related, we post content that is more broadly data science-related.
Geographically, the respondents are primarily from Europe, the United States, India, and China. 27% of respondents work within the technology sector, followed by financial services (14%), consulting (12%), and healthcare (12%). While the technology sector is categorically too broad to be insightful, our anecdotal evidence corresponds with the financial and healthcare industries being heavily involved in the MLOps scene and having mature machine learning initiatives. However, both sectors also have unique challenges that require MLOps to solve, namely regulation around transparency, privacy, and security.
Roles
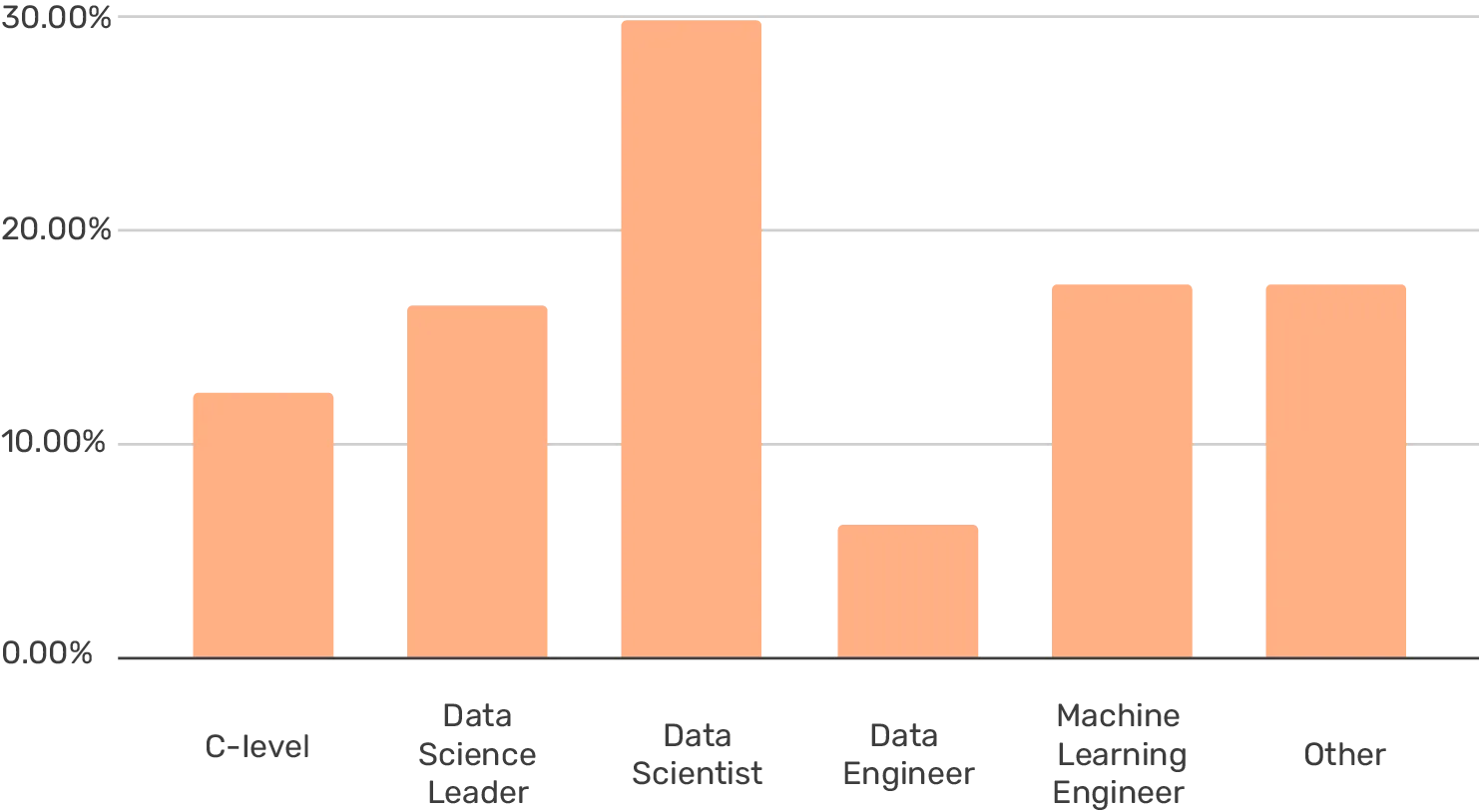
The largest group of respondents was unsurprisingly data scientists at 30%. Followed by 18% ML engineers, 18% other, and 16% data science leaders. Quite surprisingly, data engineers were rather underrepresented at 6%.
What is your title?
One of our findings from previous research and online discourse has been that titles and roles within data science are far from fixed at this point. Therefore, we asked a related question about what best describes the respondent's role, and 35% of respondents replied with their focus being building both models and infrastructure. In comparison, a smaller group can focus on one or the other (15% build models only and 14% build infrastructure only).
Which describes your role the best?
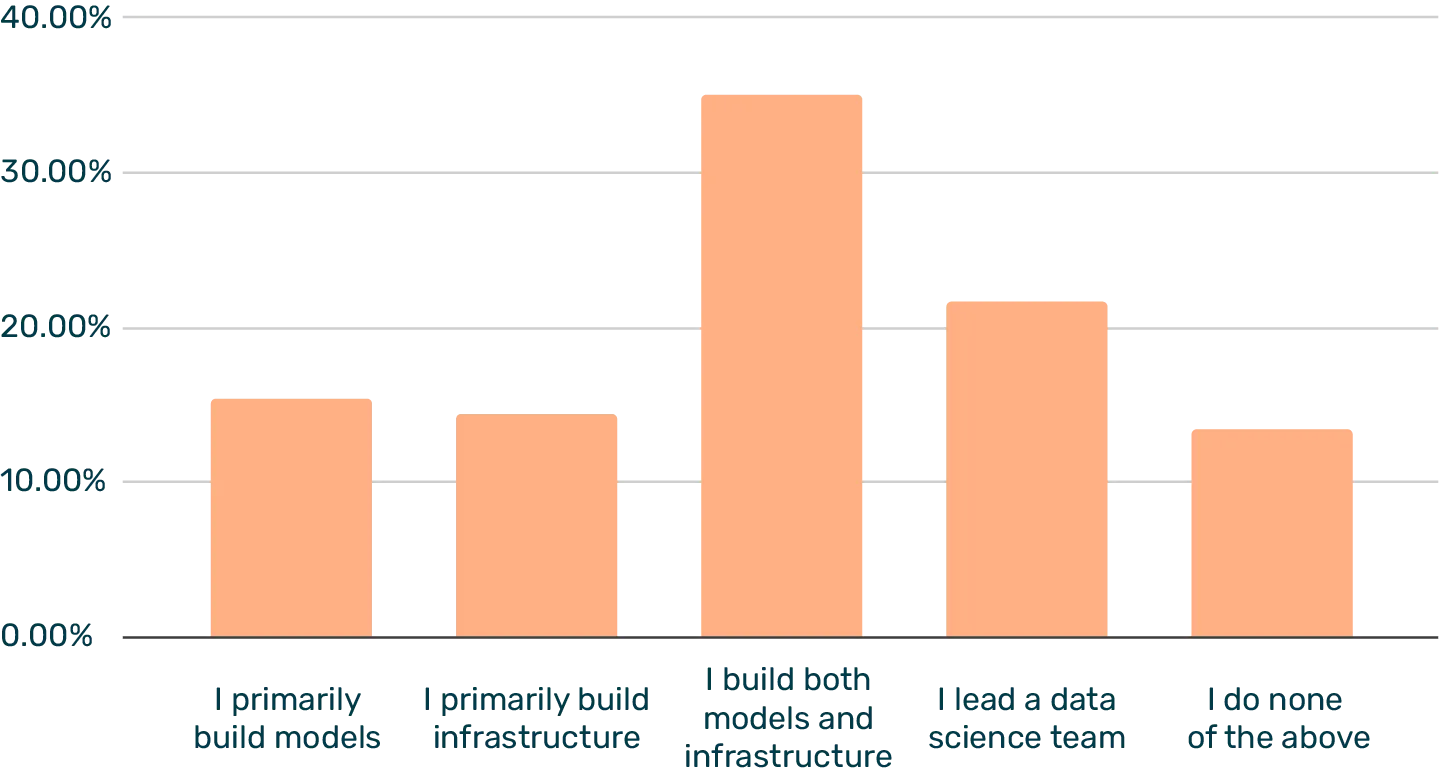
We've noticed that the content we publish around role definitions (i.e. data scientist vs. machine learning engineer) seems to spark plenty of debate, and these results seem to confirm that the roles are in no way clear cut. For example, a data scientist in one company may be critical to building infrastructure and setting up tooling, while in another company, that task is for a more specialized engineer role.
Which describes your role the best (IC-roles only)?
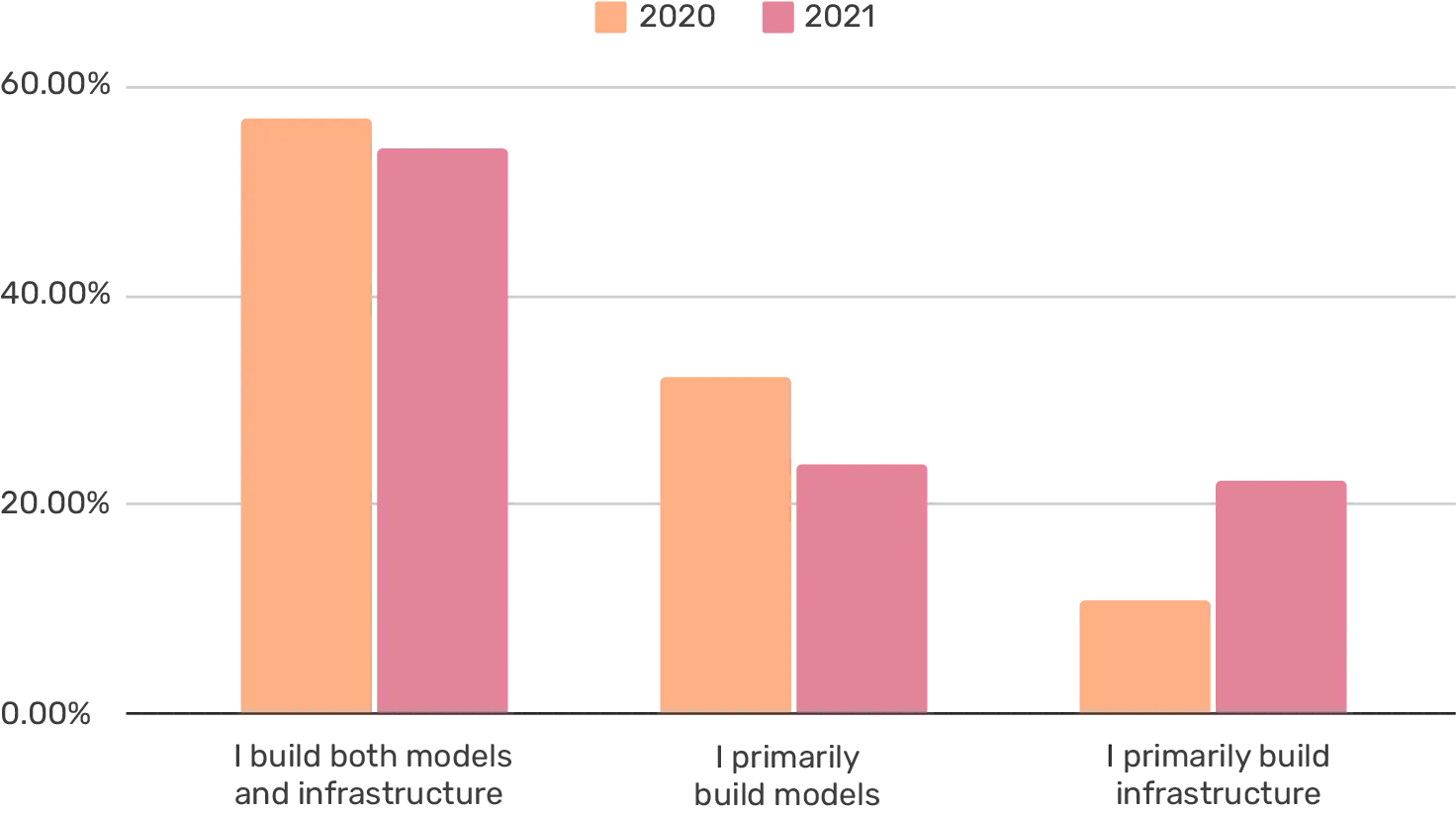
However, if we focus on just the three answers (excl. leading a team and none of the above) and compare the results from 2020, we can see growth in the group that focuses on building infrastructure. While at most a weak signal, there may be some specialization happening in aggregate.
Teams
The reason why machine learning-related roles remain broad may lie in the fact that most teams involved with machine learning are relatively small, and there isn't room for specialization (at least yet). We asked how many employees in your organization work with machine learning or data science, and the overwhelmingly most popular answer was 2-10 (56%). Even among the companies with 1000+ employees, 11-30 employees working on ML was the most common answer.
How many employees are in your company?

How many employees are working with data science or machine learning in your company?

An exciting area of future research could be the relationship between how significant the data science team is (in the context of the company size), machine learning maturity, and financial success. A nascent group of companies is building their value proposition around machine learning. It would be interesting to see if these organizations are better structured from the ground up to empower building AI capabilities.
How are you expecting your team to change in the next 3 months?
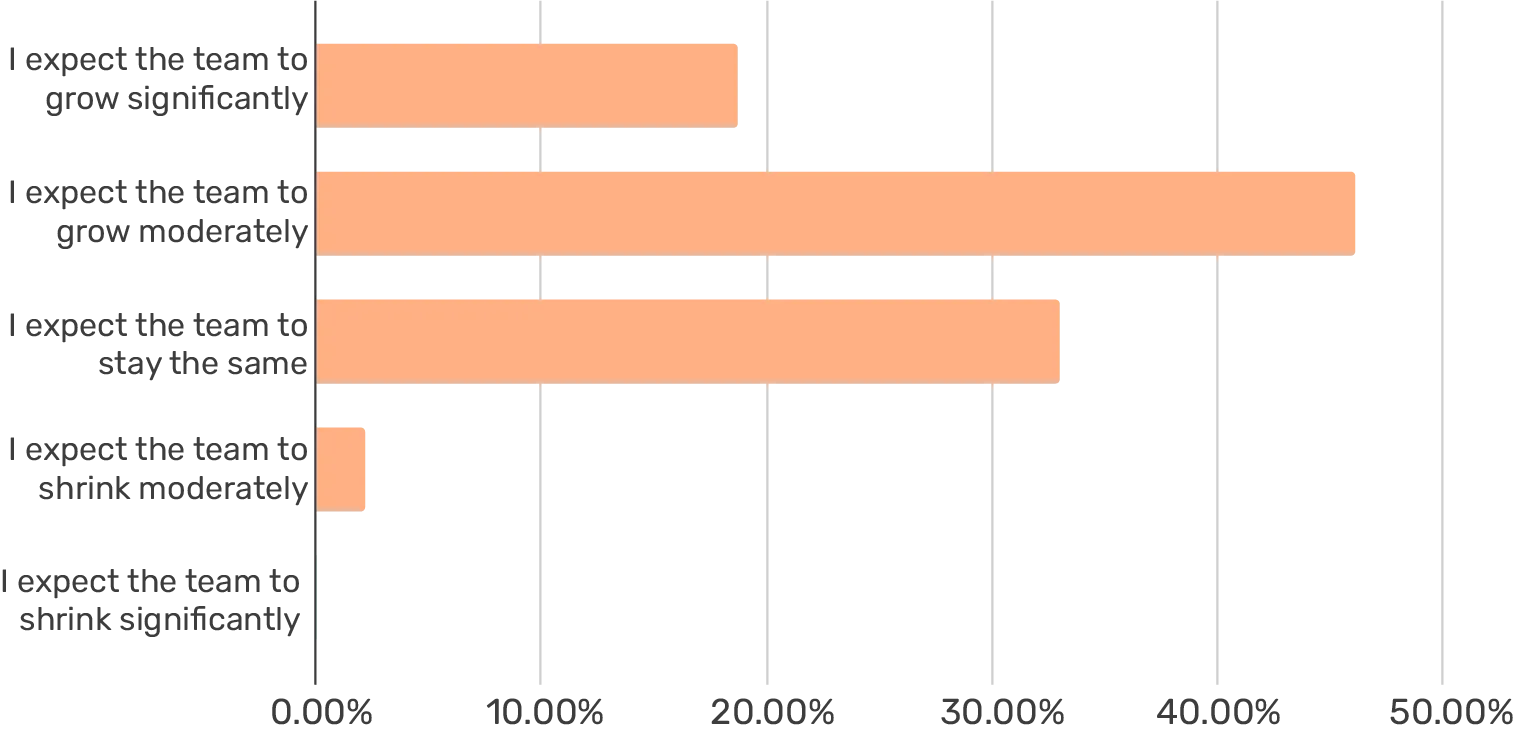
What's more straightforward, though, is that the machine learning space is in a massive hiring boom. In fact, 65% of the respondents expect their ML team to grow in the next three months, while only 2% expect the team to shrink.
Focus Area
Like last year, we asked what the respondent would focus on for the next three months (up to 3 choices). Again, the results show significant progress towards the productization of machine learning models.
What are you focusing on for the next three months (up to 3 choices)?
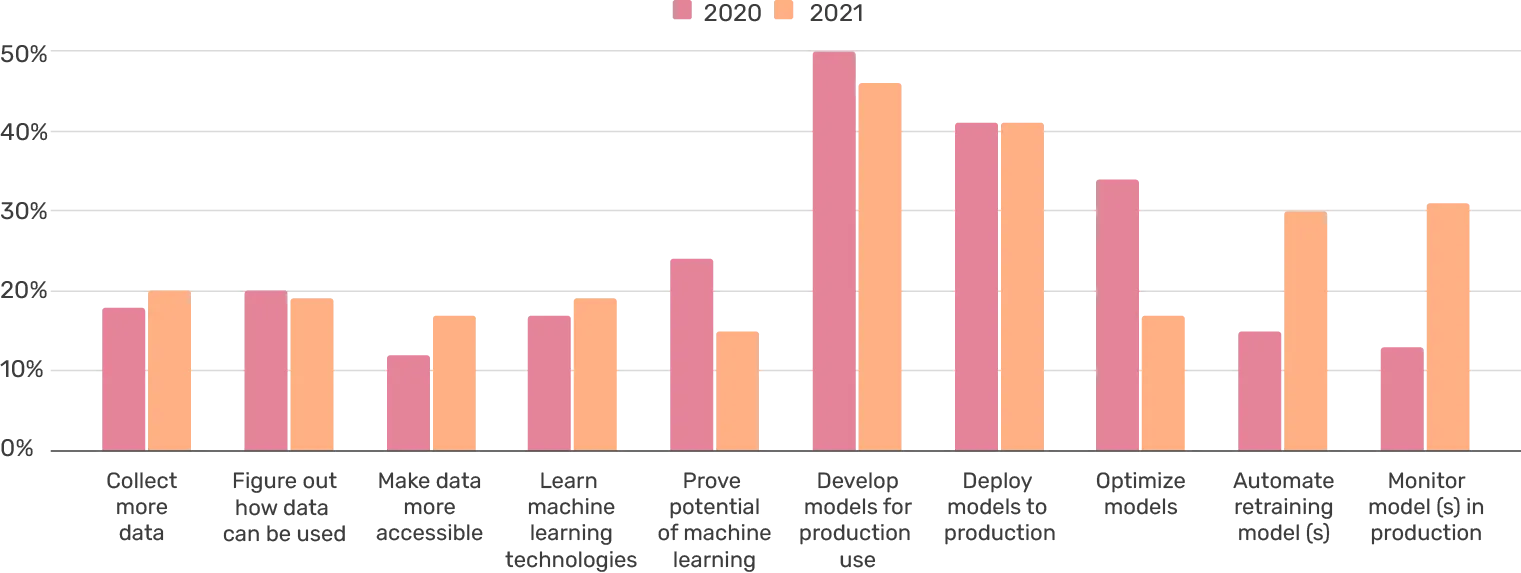
Monitoring models in production had the most significant growth from last year (13% to 31%). Supporting this enthusiasm are plenty of tools within the monitoring space that rose to prominence (including Arize, Fiddler, superwise.ai etc.).
Automating retraining of models had similar gains in popularity (doubling from 2020), with 30% of respondents focusing on building machine learning pipelines for the purpose. While being by no means exhaustive, the results support that teams have made strides towards MLOps in the past year, and implementing machine learning systems (as opposed to projects) is top of mind.
This is also supported by the decrease of "Prove potential of machine learning," as it is usually indicative of building out the first machine learning proofs-of-concept. Optimizing models also seemed to take a significant step back in priority within the past year.
Tooling
Tooling is a big part of implementing MLOps in practice. In the survey, we asked respondents what tooling they had in place, what they were looking to implement (in the next three months), and what was irrelevant at the moment. There's plenty of ways to splice MLOps tooling, and none of them tend to align with existing tools. As previously mentioned, there are broad and narrow solutions on the market, and they fit different purposes.
As the basis of the survey, we used our MLOps stack blueprint, which contains the following components: data analysis, experimentation, feature store (or training data management), code repository, machine learning pipeline, metadata store, model serving, and model monitoring.
For which areas do you have established tooling today?
 Totals are below 100% as certain participants chose not to answer.
Totals are below 100% as certain participants chose not to answer.
Looking at the areas that have established tooling code repository stands out. It is somewhat unsurprising considering Git has been a standard in software development for over a decade, and data scientists have adopted it too. In addition, data analysis (68%) and experimentation (56%) are also quite established.
On the productization side, 50% of respondents feel like they have adequate tooling for machine learning pipelines, with 33% are looking for a solution in the upcoming months. Model serving is split 39% and 39%.
The areas in which respondents are most interested in new solutions are model monitoring (52%), model registry (43%), and feature store/training data management (41%). There is double the number of respondents looking for monitoring solutions compared to those who already have such a solution.
Overall, on the experimentation side, tooling is much more established while productization is less so. However, there doesn't seem to be hesitancy in adopting tooling considering "Not relevant at the moment" is a relatively small slice of almost every component.
Conclusion
Where the data science scene as a whole is with MLOps and productizing machine learning models is a question without a good answer. However, the State of MLOps 2021 survey provides us with encouraging evidence that machine learning in production is picking up steam — and not just in headlines but in action.
The survey results represent a small slice of our community, so they are naturally skewed, but for decision-makers looking to invest in MLOps tooling or individual contributors looking to dig deeper into MLOps, the trend looks encouraging.
The best of the best

MLOps in the Wild
A collection of MLOps case studiesSkimmable. Inspirational.
The MLOps space is still in its infancy and how solutions are applied varies case by case. We felt that we could help by providing examples of how companies are working with tooling to propel their machine learning capabilities.
Think of this as a lookbook for machine learning systems. You might find something that clicks and opens up exciting new avenues to organize your work – or even build entirely new types of products.
Download