This article is the story of us at Selko.io, productionizing our machine learning workflows. We’ll describe Selko’s route from starting the company to developing our first ML models. We’ll also walk through how we built a fully working machine learning solution combining our UI, backend, and orchestration layer for machine learning tasks. And of course, how we went from a homegrown ML orchestration platform to Valohai. To give you some context, let’s first dive into the history of the company.
Selko, a Finnish word for clarity, was founded by a group of researchers from Aalto University in Finland, in the year 2017. The idea was simple: there is a lot of technical text that works as a guideline for any engineering project that we could distill and summarize to save time.
What is Selko.io?
Selko is a SaaS product for complex text analysis, where we help users train their own custom models, using a minimal amount of training data, to analyze massive technical documents (currently PDF and Excel files).
 Selko is highly useful in projects where there are multiple stakeholders from different fields of expertise. For example, a project manager who receives customer requirements and regulation documents from different stakeholders in a large project. Their task is to a) identify relevant requirements for given disciplines or given modules of a product, b) add attributes automatically to technical requirements or c) analyze and improve the quality of requirements and specifications. Another example is the legal department of a technology company where they need to analyze the risks in project contracts.
Selko is highly useful in projects where there are multiple stakeholders from different fields of expertise. For example, a project manager who receives customer requirements and regulation documents from different stakeholders in a large project. Their task is to a) identify relevant requirements for given disciplines or given modules of a product, b) add attributes automatically to technical requirements or c) analyze and improve the quality of requirements and specifications. Another example is the legal department of a technology company where they need to analyze the risks in project contracts.
How Selko use machine learning?
We have built many deep and not-so-deep models, mostly for text-classification and summarization. We also have linguistic pipelines that analyze the engineering text. If you have worked with deep learning, you understand when we say “it’s data-hungry”. By mid-2018, something exciting happened, and the NLP community started stating things like that the ImageNet moment for text had arrived.
At the same time, keywords like ELMo, ULMFiT, Transformers, and BERT started popping up. What they all had in common, they’re all built on transfer learning, where the knowledge from pre-trained models is fine-tuned to another domain. We decided to explore Sesame street models and started building pipelines around them.
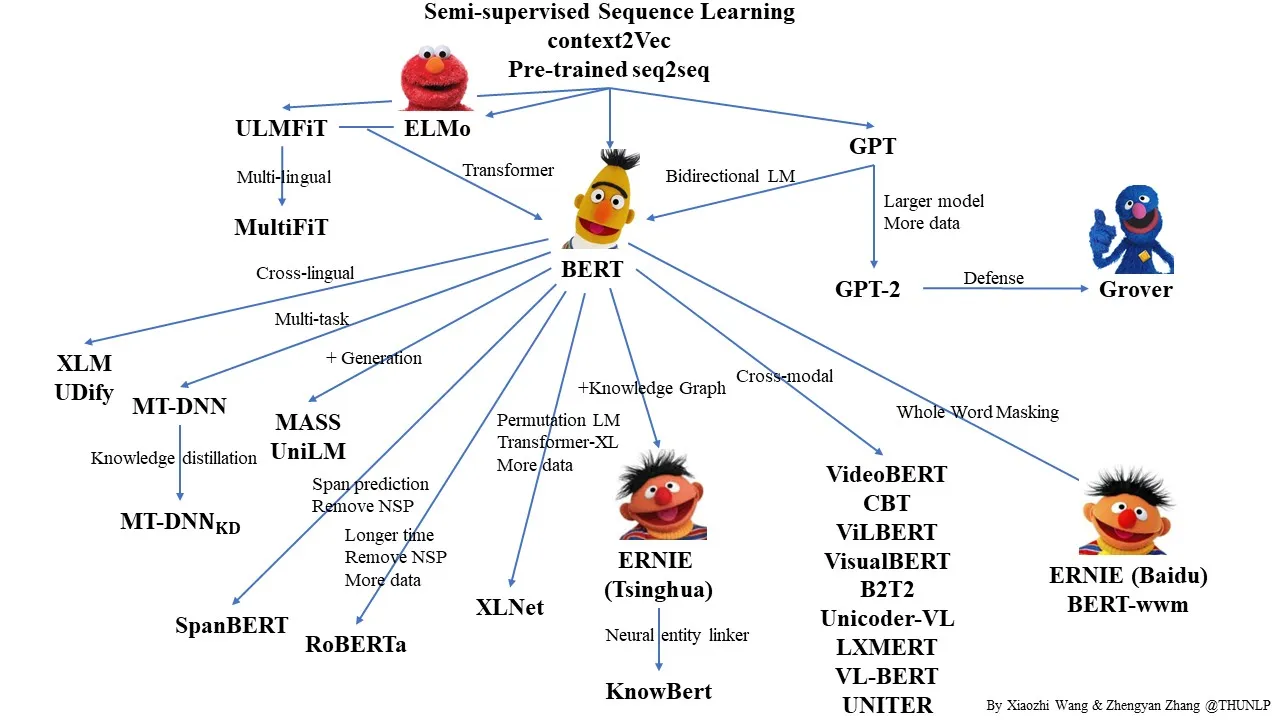
Our Initial pilots and what we achieved
With the newly acquired optimism from transfer learning, we have done pilot projects with Fortum and RUAG to explore the models (hierarchical multi-label classifiers). We were able to achieve awesome F1-scores with our data science pipelines, and, with that confidence, we decided to productionize the entire pipeline ourselves.
”b–but it works on my computer..”
After the pilot projects, we had our transfer learning pipelines working on our local machines. But we ran into a problem: how could we get our local data-science notebooks into a scalable environment that could be replicated automatically by any new member of our team? We also wanted our customers to be able to re-train their own models without us manually doing it for them.
First steps in building machine learning pipelines
We ended up building internal product that includes machine learning orchestration for re-training models. But at the very beginning, we faced challenges in setting up a working machine learning pipeline that integrates well with our UI, backend, our cloud services (initially Google Cloud Platform (GCP)).
We named our machine learning orchestration MLMAN (Machine Learning Management). It was supposed to be a tool that helps us productionize machine learning methods and scale up with our customer base. We initially decided to build it using Python and Celery. The tasks in MLMAN were as follows:
- Serve API endpoints for train/predict calls (“master-instance”)
- Depending on the type of the task, spin-up a new CPU/GPU instance in GCP if there was no worker-instance running
- On the new instance (“worker-instance”), contact the master-instance to get the task, pull a specific docker-image relevant for the task, and run the commands specified in task-template, sending metadata to the master-instance as the task progresses
- When the task is finished, send the results back
- The tasks were queued using Celery library with Redis
- Once the tasks in the queue were finished, the worker-instance kills itself if no new task given to it in 5 minutes
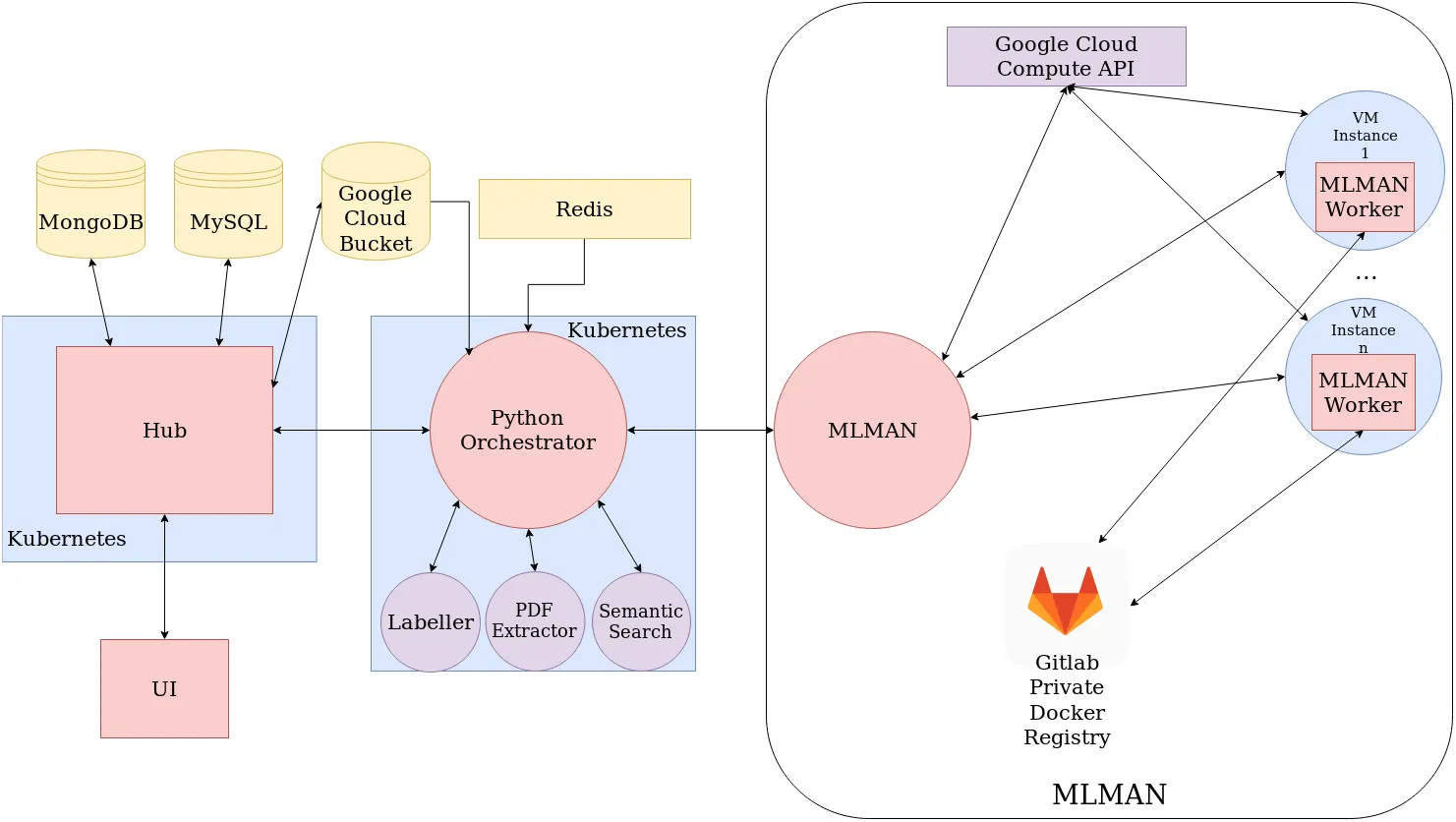
After a couple of weeks, we noticed that our Python and Celery program was not working as expected, because of numerous bugs and the complexity of the task. We decided to switch to a more simple solution with Kotlin, Docker Java API, and Google Compute Engine API library, basically a small Kotlin-program that had a limited number of instances in use and could distribute tasks across them. We barely got our version running in a month, and after another failed solution, that we were quite a piece of engineering art, we couldn’t trust it enough.
There were many roadblocks during the development:
- The instances shutdown even before finishing the task, which we called the “annoying Celery-bug”
- We had much trouble running GPU-instances with CUDA
- Scaling issues
- Cloud-vendor-specific solution problems
- Difficulty in debugging the problems
- Lack of monitoring and resilient error handling
- Shortage of development resources needed to develop the system further into a solution we could trust
With limited resources to improve MLMAN, we decided to prioritize our efforts for our core business – solving our customers’ problems with huge project documents. Instead of continuing with MLMAN, we searched and found Valohai. It took us a week or two weeks to get everything up and running on Valohai, with a much more stable and reliable solution, with a staggering amount of features and with great support from the Valohai team.
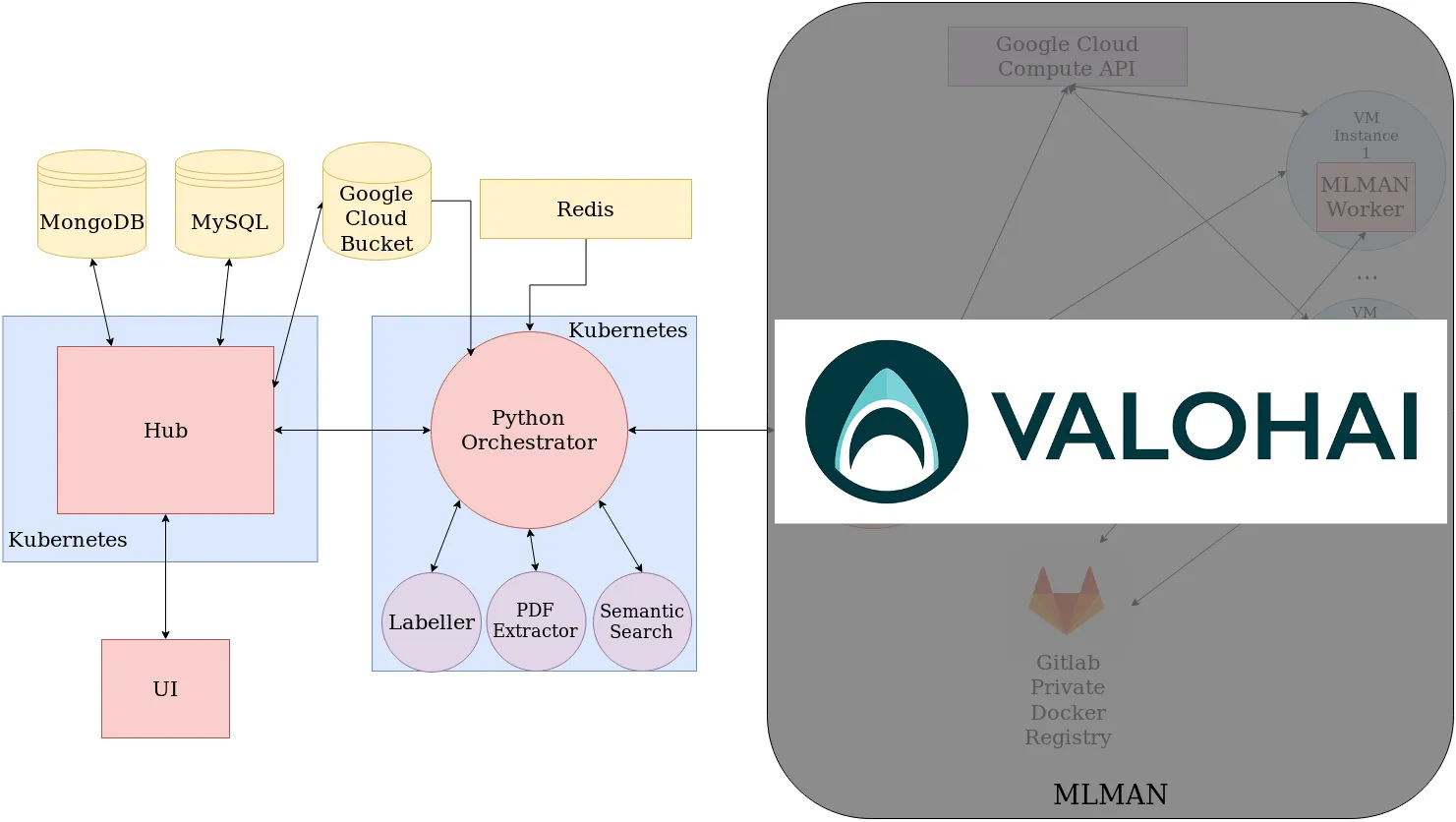
We learned a lot about ML infrastructure and the specific needs in MLOps during our project, but at the end of the day, it wasn’t what our business was about. We should have had our eye on the ball instead of the infrastructure.
Check out Selko website !
Authors:
Aditya Jitta

Senior data scientist at Selko.io , where I build and deploy machine learning models into production.
I am finishing my PhD from University of Helsinki and did Masters in Machine learning at the University College London .
Jarkko Lehtiranta
 Product manager by day, developer by night. Living the lean, agile dream. Addicted to everything start-up.
Product manager by day, developer by night. Living the lean, agile dream. Addicted to everything start-up.