
With over 50,000 stars on GitHub, Hugging Face transformers is undoubtedly one of the most exciting and ambitious NLP projects. In addition to transformers, Hugging Face builds many other open-source projects and offers them as managed services.
Now focusing on transformers, they are simply a great way to get started with NLP and wield the collective brain of the whole Hugging Face community. There’s one ‘but’ though. The data you want to use will have to match the quality of the neat examples, and in the real world, you’re unlikely to have a clean and nicely formatted dataset from the get-go.
The reality is that Data Scientists spend quite a bit of their time, at least at the beginning of the project, on getting the data right. Along the way, there can be mysterious things in the dataset messing up with your model wholly. So creating a dataset for your use-case isn’t a one-time thing; you should think more about building a machine that can produce that dataset again and again.
With Valohai (obviously, this was gonna go here), you can run your preprocessing in a neat pipeline, train your Hugging Face model in the same process, see how it performs over time, and deploy your model for inference. Now I’m going to show you how!
Sharks are coming!
Let’s take a look at the Kaggle competition dataset Global Shark Attacks. The original dataset can be found at https://www.sharkattackfile.net/incidentlog.htm. Why sharks? Take a look at the Valohai logo ;)
We want to predict the Species based on the injury and since injury description is text-based, we want to use some NLP model that maps the similarities and dissimilarities across these injuries paired with the species causing them.
If you want to follow along, you can find everything in the repository here.
Building the steps
First, we want to import the data of course. Next up is the all-time favorite of all the Data Scientists: data cleaning and preprocessing.
This dataset is relatively messy, as usually human-made data is, including some missing values as well as various ways of reporting the species and injury from all over the world. In addition to the “normal” cleaning, we need to tokenize the text in order to use it in the model training.
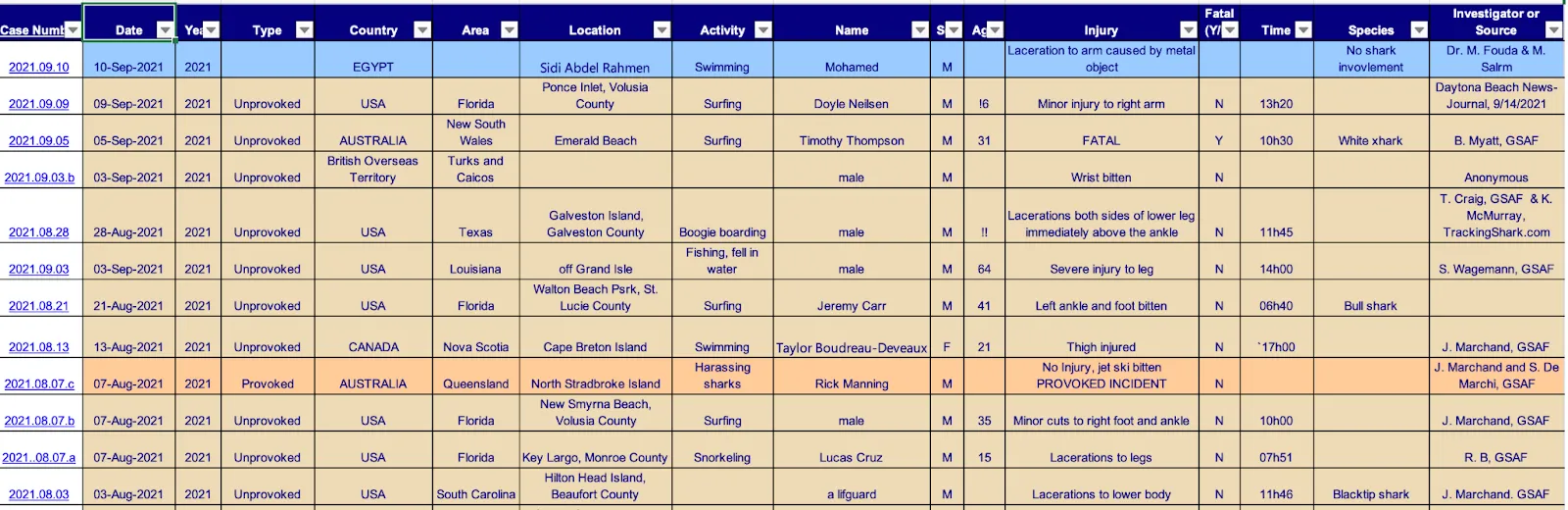
So the first step is to fetch the data and make some small adjustments to it [fetch_data.py]. Then we preprocess the text by eg. filtering out injuries with no confirmed shark involvement [pre_process.py].

We need some further processing, making the species names match integers in order for the model to understand them. We also split the dataset to train, validate and test sets.
Finally, we are ready to use the wonderful hugging face transformers library. Let’s select a lightweight model DistilBERT, which is a small, fast, cheap and light Transformer model trained by distilling BERT base. According to Hugging Face’s website, it has 40% fewer parameters than bert-base-uncased, runs 60% faster while preserving over 95% of BERT’s performances.
We use first the DistilBertTokenizerFast in order to tokenize the injury descriptions and then prepare the dataset for the fine-tuning of the basis model distilbert-base-uncased.
View code on GitHubYou can find the full source code at github.com/eikku/shark-attacks
We have four python scripts in total, for each step its own, which is strongly recommended in a real-life Data Science project. In order for Valohai to understand your inputs and outputs, parameters, we need the valohai.yaml file. The yaml file defines the data variables, the parameters and the runtime for Valohai (all of which can then be edited in the UI). You can read more about it here.
Now we have four steps defined in Valohai.

-
Data fetching
-
Preprocessing
-
Preparing the text
-
Tokenizing and model fine-tuning
Tying the Hugging Face pipeline together
You can of course run these steps in the Valohai UI by hand, but who really wants to? Especially if you are going to run this over and over again?
You can create a process, which in Valohai is called pipelines, by telling your valohai yaml file which step should be after another. These pipelines can be run from the UI, through the API or scheduled.

PRO tip: you can now use valohai-utils to create the pipeline yaml file for you.
View code on GitHubYou can find the full source code at github.com/eikku/shark-attacks
Validating model performance and managing trained models
In addition to the processing and model training, we obviously want to see how the model performance looks over time and can introduce some metrics to be printed and shown at Valohai UI.
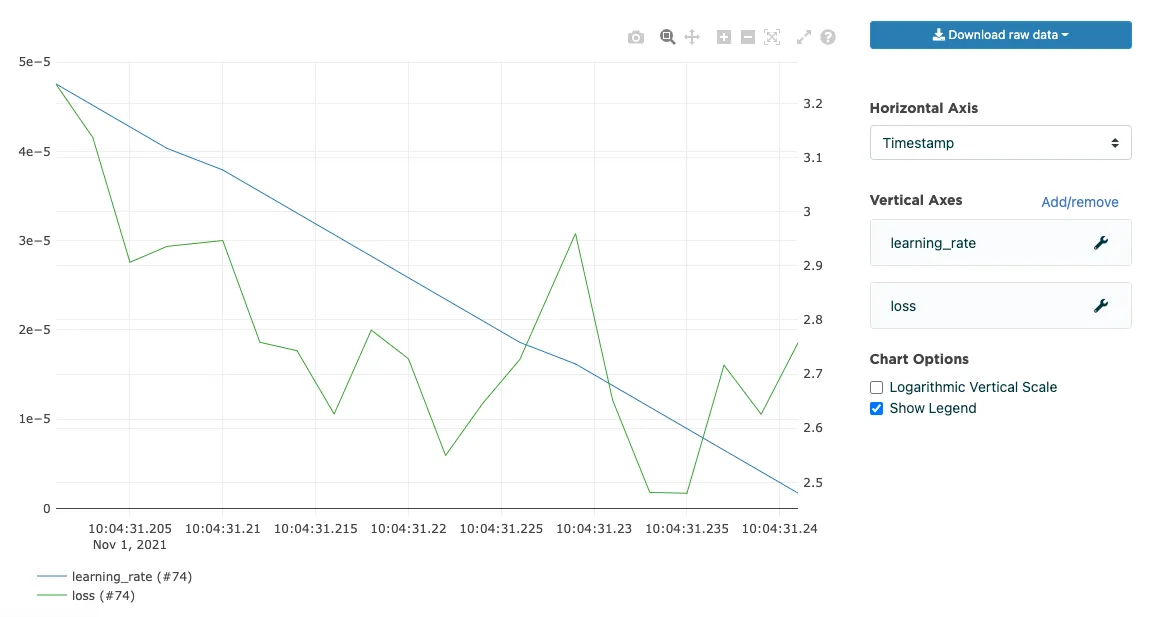
Valohai can visualize any metrics you choose to log for easy model evaluation
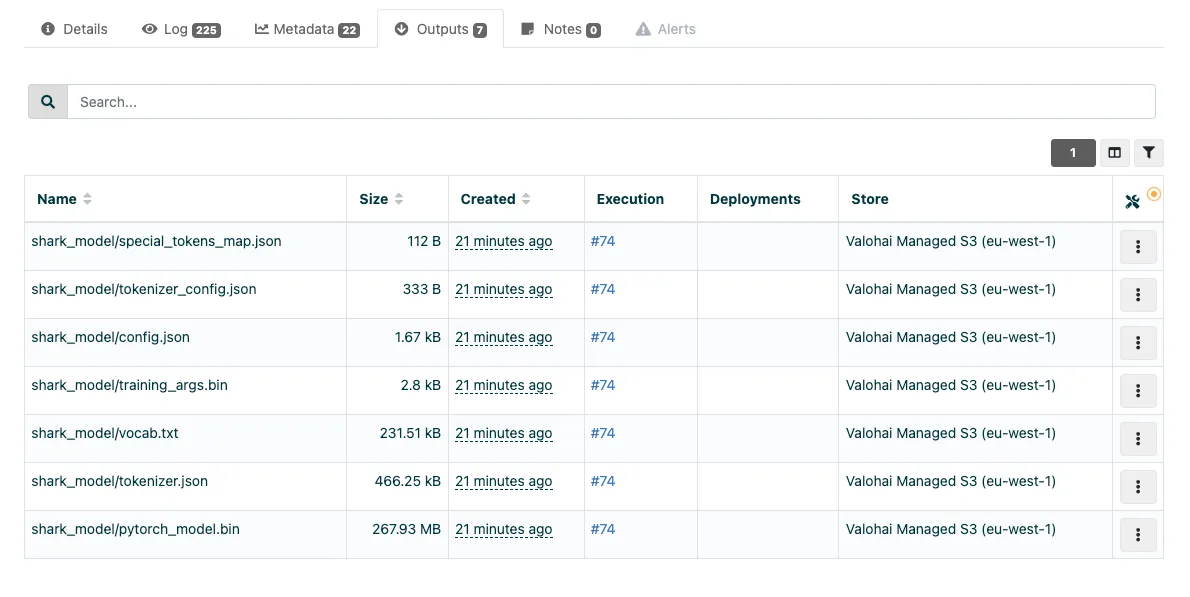
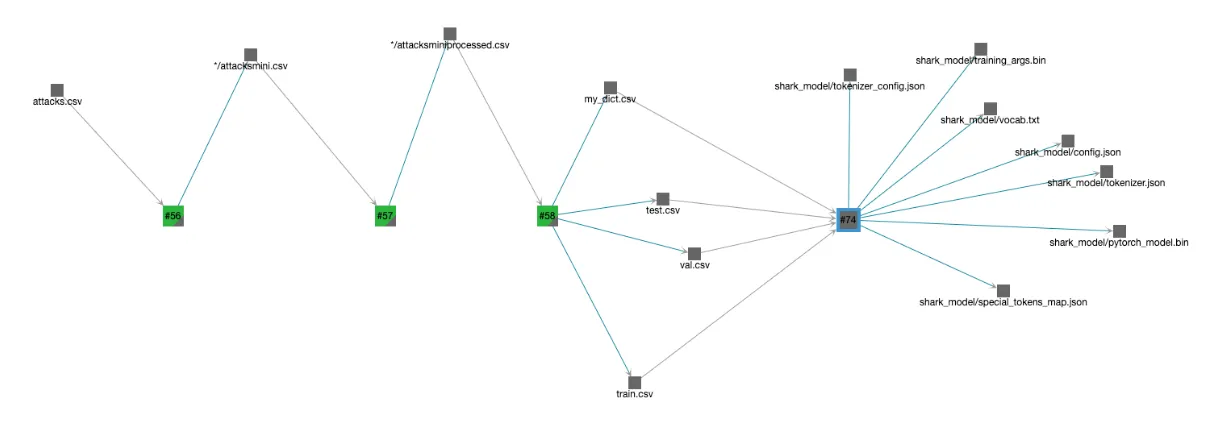
Finally, Valohai stores the lineage of each stored output to ensure reproducibility
Last but not least, we want to use the model for new injuries we might face and deploy it for use. You can deploy a trained model for online inference using Valohai deployments. So we create yet another python file called predict.py, which will get the new injury which you give as an input, fetch the trained model and return the prediction as output. With a simple API call, you can check which shark it was in case you end up with an injury in those scary waters and wonder what it was that bit me?
Want to know how this is done in practice? Stay tuned for the follow-up piece covering Valohai deployments in detail!
Results?
So we have successfully created a complete Data Science end-to-end process from data retrieval and preprocessing to serving the model, using cool NLP tools with a couple of lines of code in a neat pipeline.
Get your own NLP pipelines going
NLP libraries like Hugging Face are great. They allow you to move quickly and utilize the research done by the sharpest minds out there. However, as emphasized in this article, the model is only part of the solution and figuring out a system to wrangle data, fine-tune and use the model again and again is key. You can see the whole project in the git repo, you are very welcome!
Valohai and Hugging Face are a great fit for teams building production NLP systems. If this describes your team and you’re still looking for something to take care of orchestration, you should book a demo.
If you’re still unconvinced about machine learning pipelines and MLOps, you should download our Practical MLOps eBook which tackles tech debt in machine learning systems.