Building something new and asking the computer questions no one dared to ask before is not a straight, predictable path. One enters the wilderness blindfolded, running circles, tripping on tree stumps, and getting stuck in quicksand. For a pioneer, this is normal. Failing is part of the strategy. For example, during the endless search for a reliable light bulb filament, Thomas Edison famously said: “I have not failed, but discovered 10,000 ways that won’t work”.
Progress in pioneering comes through experimentation, and doubling the experimentation rate will get you there twice as fast. What is the bottleneck that prevents your team from experimenting quickly? How much friction is there between an idea and its execution? What is the upper limit for running parallel experiments? How fast, reliable, reproducible, and accessible are the results? The success of a machine-learning team is ultimately a result of its experimentation infrastructure.
An efficient machine learning team should be an experiment factory – conveyor belts and all. The faster we can create experiments, the better we are at our job.
Tapio Friberg – Senior ML Engineer, ICEYE
With Valohai, rapid experimentation, massive grid searches, complex multi-cloud pipelines, distributed learning clusters, and model deployment are all a single click (UI), a single command (CLI), or a single request (API) away and handled by the battle-hardened orchestration system. The platform is entirely vendor-agnostic, and jobs can simultaneously run on multiple cloud vendors and on-premise resources.
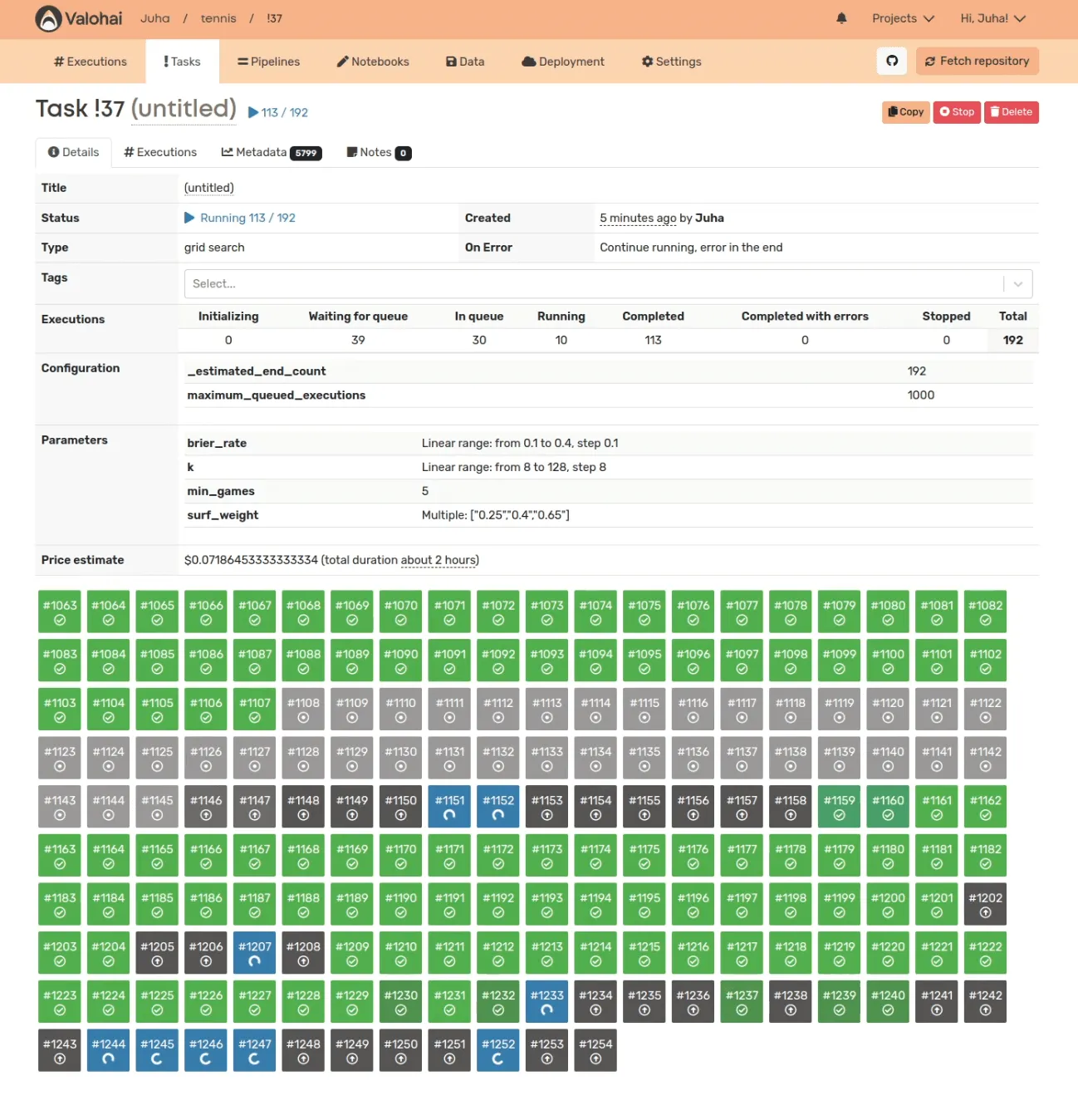
Now that’s a lot of technical terms, but let’s break it down in layman terms. Valohai’s smart orchestration gives each data scientist the power to accelerate their work – without help from DevOps and IT. And best yet, Valohai doesn’t lock your organization into AWS, Azure, GCP, or on-premise but rather enables you to use the most cost-efficient combination.
We used to have an engineer or two allocated to support deploying models. With Valohai, anyone on the team can deploy independently. The reduction in overhead is immense.
Rishabh Shukla – Lead ML engineer, Lifebit
Valohai offers the only experiment infrastructure tailor-made for the pioneers. Our auto-scaling and auto-caching systems, specifically designed to handle the demands of state-of-the-art deep learning projects, have the fastest iteration times in the industry on a massive scale.
The power to summon powerful resources comes with the responsibility to use them responsibly, too. Pioneers move fast and armed with manual orchestration, leaving behind a cloud of smoke and a trail of wasted resources. If you ever want to break the ice with a machine learning engineer, ask them about the most expensive computation they have accidentally left running.
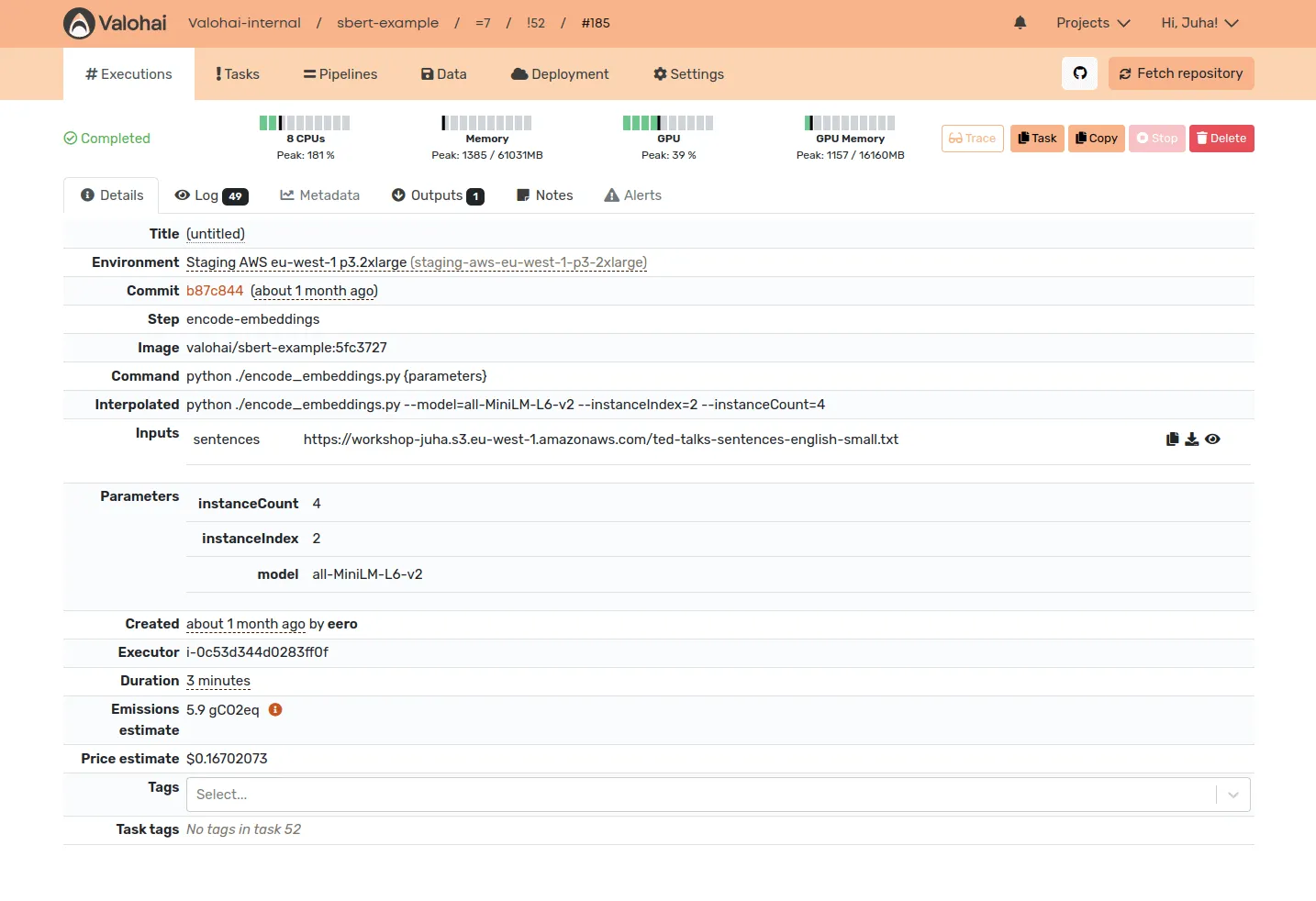
Valohai smart orchestration allows spending as hard as you need while ensuring zero leakage on idle machines and data bottlenecks. The auto-scaler safely handles spinning machines up and down in the background, and the caching system minimizes excessive data transfer. The most effective machine learning teams focus on the following experiment, not on the busywork of cleaning up the previous one.
There is no time for tweaking the cloud, restarting the zombie clusters, or hunting down the missing log files. What a pioneer needs to succeed is a fast and reliable experimentation pipeline, and occasionally a thousand GPUs to prove a point.
Kickstart your experiment factory today with Valohai smart orchestration.
To dig deeper, check out how our friends at Syngenta are running massive pipelines:
Want to know more about Valohai?
This article is part of a series of blog posts: