The young Thomas Edison was a pioneer and a great inventor. As he got older, he became a great facilitator, too, hiring the best and the brightest minds. After losing many patent wars as the typical absent-minded genius, the old and wise Edison understood the importance of documentation. He realized the best pioneers had no patience for the paperwork and hired special bookkeepers to gather and organize the mad scientists’ trail of crumbs instead.
The same scenario arises in the modern data science factories of today. The best ML pioneers are busy exploring the possibilities of tomorrow, and no energy is left to keep track of the progress. The problem grows over time as the projects mature into production, team sizes grow, and data scientists come and go. While bookkeeping is beneficial even for a lone pioneer, it is the lifeblood of teamwork and collaboration of the entire organization.
Valohai knowledge repository offers a scalable solution to fix the issue at its core. Like the Edison bookkeepers in the lab, Valohai keeps track of every experiment, result, and cost silently and efficiently, without getting in the way of the pioneer’s journey.
What goes into an experiment?
At the core of the machine learning project lies a single experiment:
experiment = inputs + compute + outputs
Sounds simple, right? Actually no.
In addition to the raw code and data, the modern machine learning experiment depends on libraries, hardware, and operating systems. And the output is complex too. There are logs, metrics, models, and technical metadata. All this must be saved, organized, searched, and reproduced later.
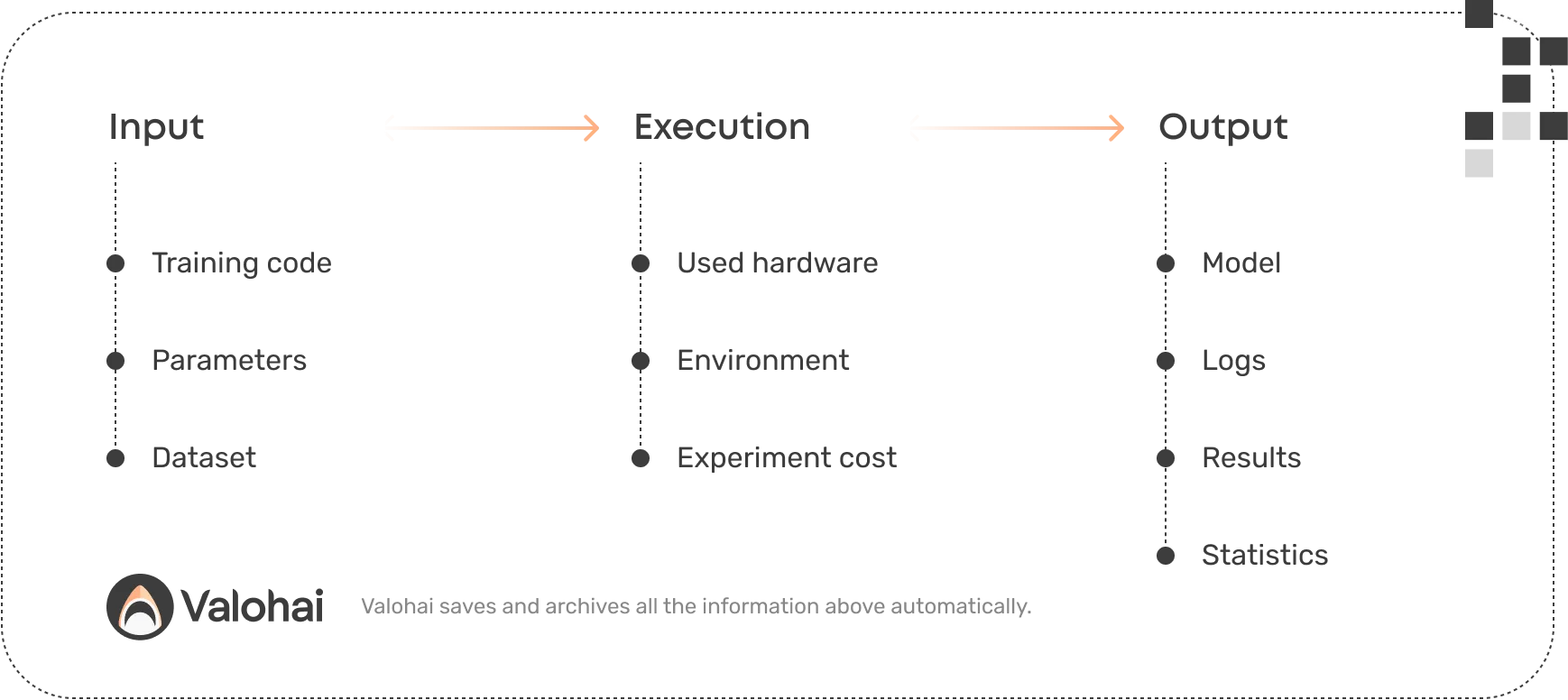
How does Valohai solve this?
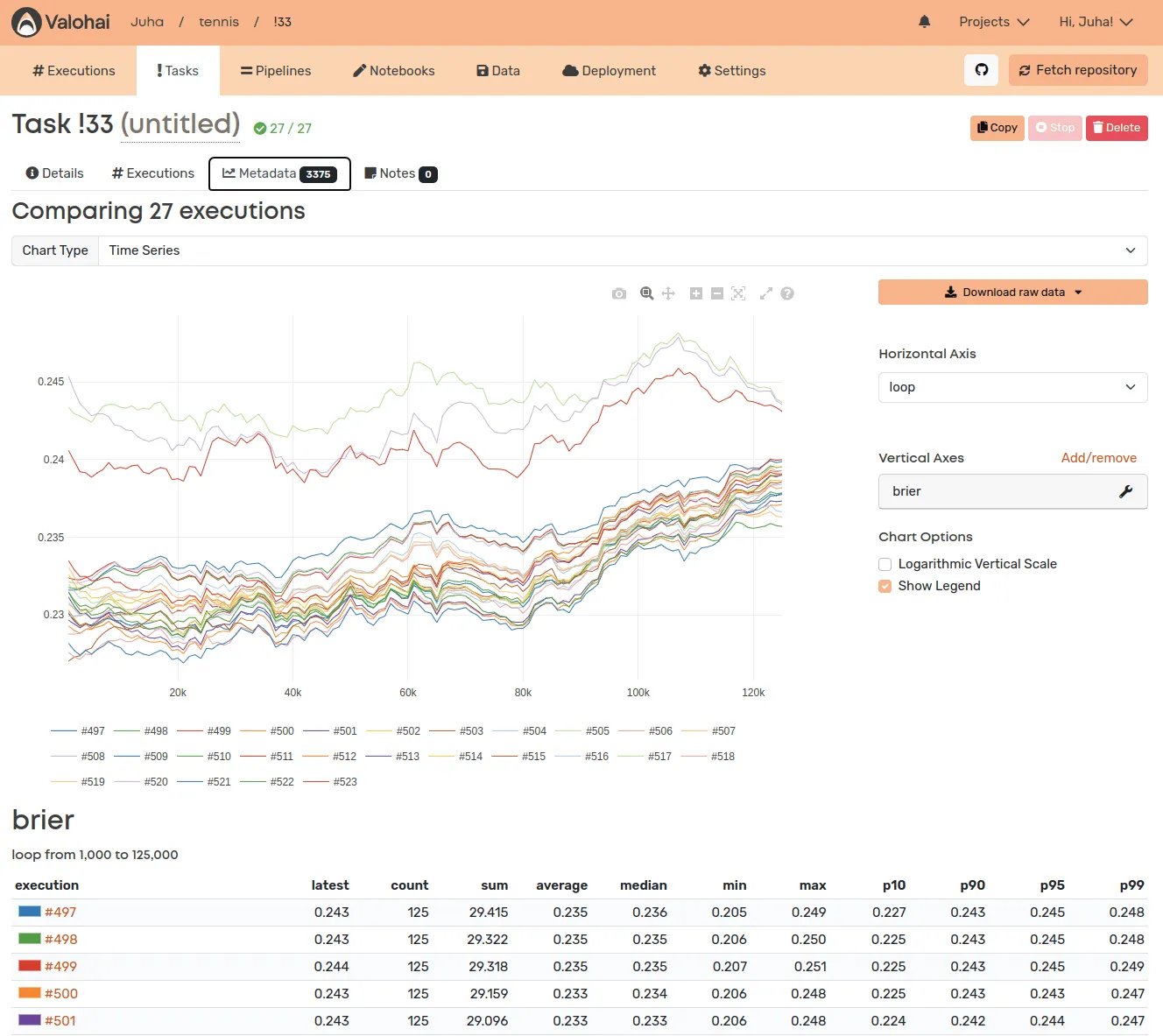
Valohai integrates into your code repository, container repository, data storage, and compute resources - in the cloud and on-premise - orchestrating and recording their complex interplay. This way, the bookkeeping is fully ingrained into the machine learning workflow and something the pioneers don’t even need to think about conscientiously.
Every asset, from code and data to logs and hyperparameters, is tracked, offering a full lineage of how the datasets were generated and models were trained. The platform can also tell you who did what, when, and how much it cost. We even estimate the co2 emissions!
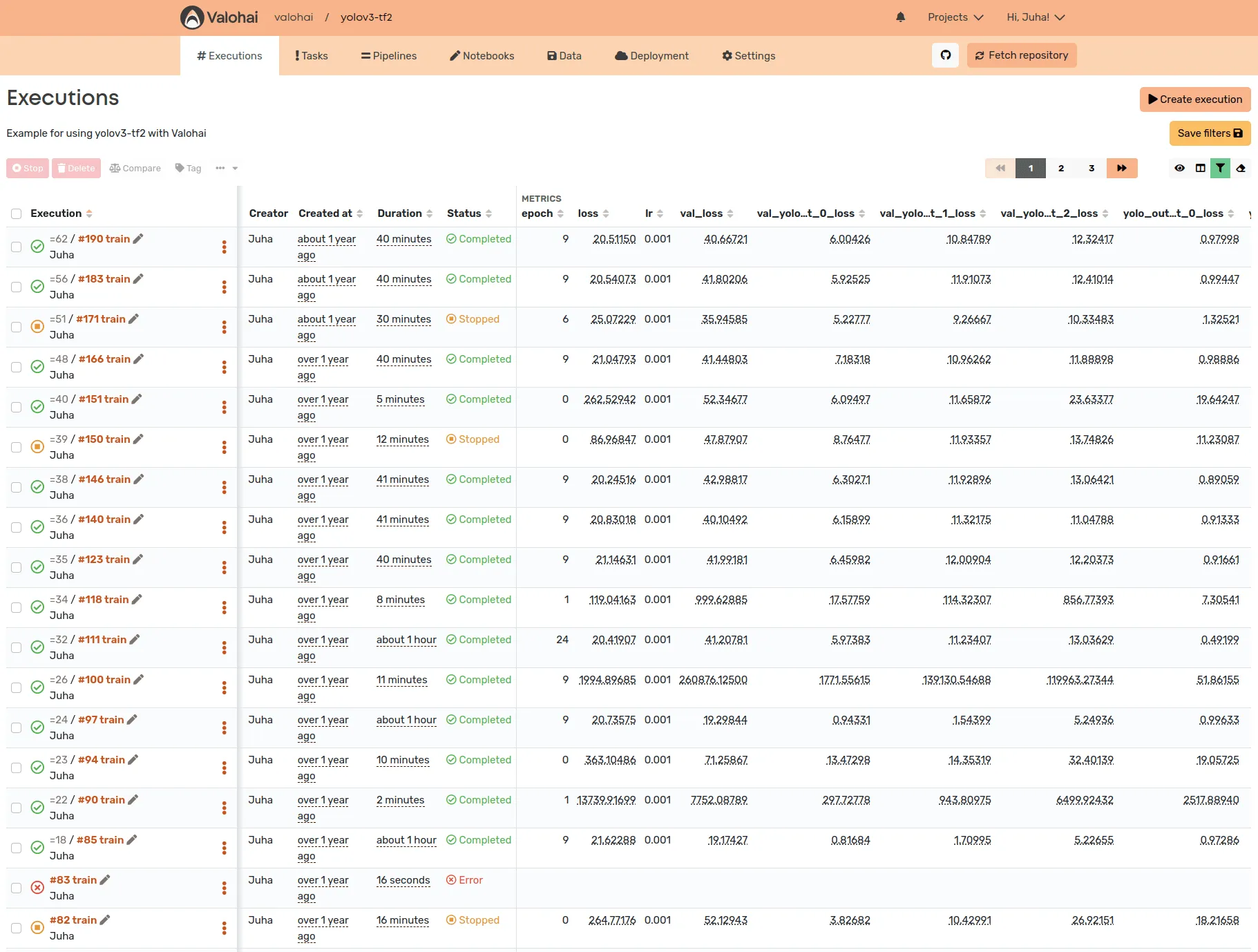
In Valohai, all the past runs are also reproducible by design. The same code, data, container, operating system, and hardware are summoned and guaranteed to produce the same predictable result as last time. Everything can also be shared with your team, and there is no need for separate model registries or metadata stores.
What is the ultimate benefit?
Your team is on a journey to explore something the world has never seen, asking computer questions no one dared to ask before. While they need to move fast - faster than anyone - they must also keep track of things so that everyone in the organization stays in sync. Velocity and bureaucracy have always been at odds with each other.
The only way to be successful is to remove the manual responsibility for bookkeeping and make it automatic and ubiquitous, like breathing. It stays in the background, integrated into all sub-systems, silently documenting everything. This unleashes the pioneers to work on their magic at maximum, and supercharges teamwork, collaboration, and knowledge sharing within the organization. This is the Valohai knowledge repository.
For a deeper dive into how it all works, check out these articles:
- Introduction to Valohai metadata, metrics, and visualizations
- Introduction to Valohai datasets
- Introduction to Valohai executions
Want to know more about Valohai?
This article is part of a series of blog posts: