
It has not been that long since we announced the launch of the carbon footprint tracking feature, but here we are, bringing you even more features. This time it is distributed learning. Although it has been already announced in the patch notes, it might have flown under your radars. So we decided to put it into the spotlight.
In this article, we want to talk about what distributed learning is in brief and focus more on why having this feature is not only a nice-to-have flex for us as an MLOps platform but a valuable tool for your business.
Distributed learning in a nutshell
If there is one thing to remember from this article, it is that distributed learning is all about spreading the load of the training process. There are two ways to do it:
-
Model parallelism presumes that the different parts of your model are trained on different devices but use the same data set. This approach comes with implementation difficulties: deeper layers must wait for the initial layers to finish during forwardpass, and the first layers must wait for the deeper layers during backpropagation. It works better for branching model architectures and when training on a single machine with multiple GPUs.
-
Data parallelism, a more common practice that is a bit more straightforward in implementation, presumes that each machine uses the same model but a different data set. You can spread out the data among different workers, obtain results and combine them using, for example, average or median values. Then do it all again as many times as you need.
Whether to go with data or model parallelism depends on your use case. However, unless you have really big models that just won’t physically fit on a single device for training, model parallelism is not usually worth the effort.
Nevertheless, and we are tooting our horn here, with Valohai you can do both. Our platform is flexible in that way. Although if you want to go with model parallelism, it will require more effort to code your valohai.yaml file the right way to structure the project compared to going with data parallelism.
However, for now, let us focus on data parallelism for the rest of this article.
Why is distributed learning cool?
Basically, it ramps up the speed of training due to faster hyperparameter optimization, if we talk about data parallelism. Usually, hyperparameter tuning tasks exist in isolation within indifferent workers, and those workers are not communicating with each other. However, with distributed learning, your workers communicate and work together.
When you run the task, Valohai will wait until all workers are done processing data, and only then will these workers start communicating with each other. This feature provides a lot of flexibility to your experimentation, allows generating mappings of communication between workers, and upgrades the communication in an efficient manner. You can check out the examples that we have for different communication technology like gloo and mpi.
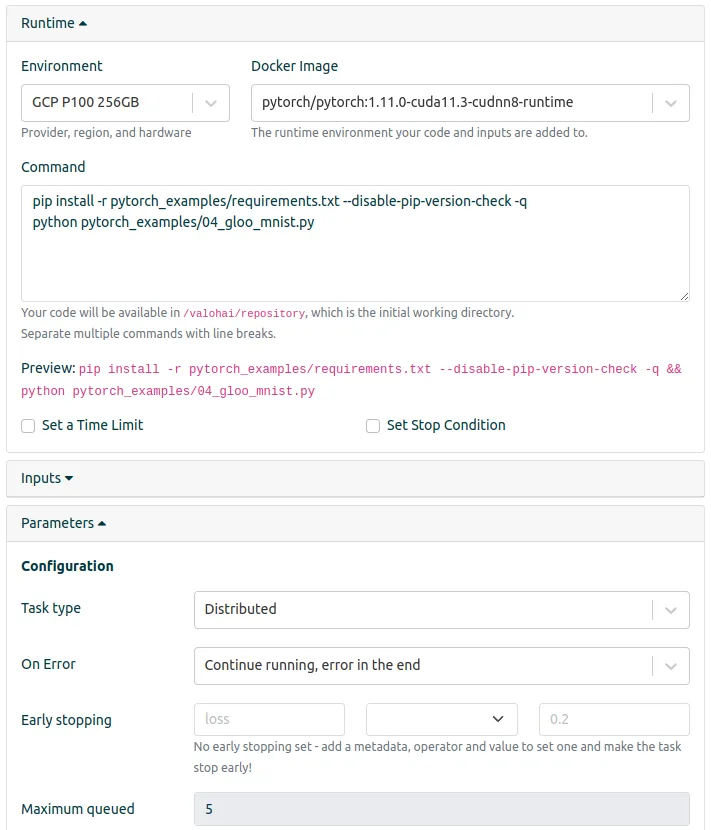
Creating a distributed task at Valohai: setting the task type in configurations to “Distributed”
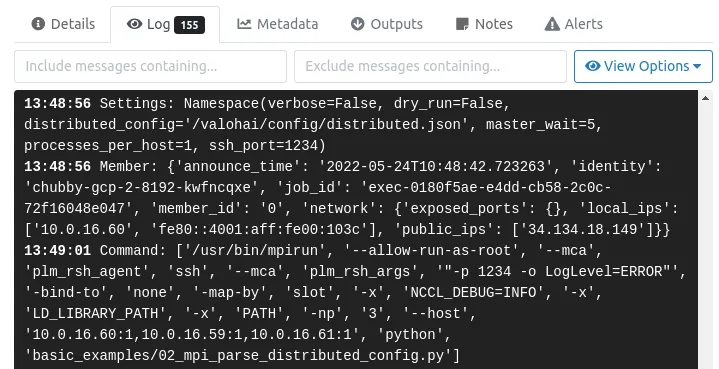
Pretty cool, huh? However, while this is a very useful solution, there are very few platforms providing scalable multi-machine distributed learning features. Oftentimes there is also a problem of being locked in with a single framework.
Here comes the best part! With Valohai, you do not need to worry about framework lock-in because you can use whichever framework you want. Valohai has all the address information stored. Most other platforms do not do that.
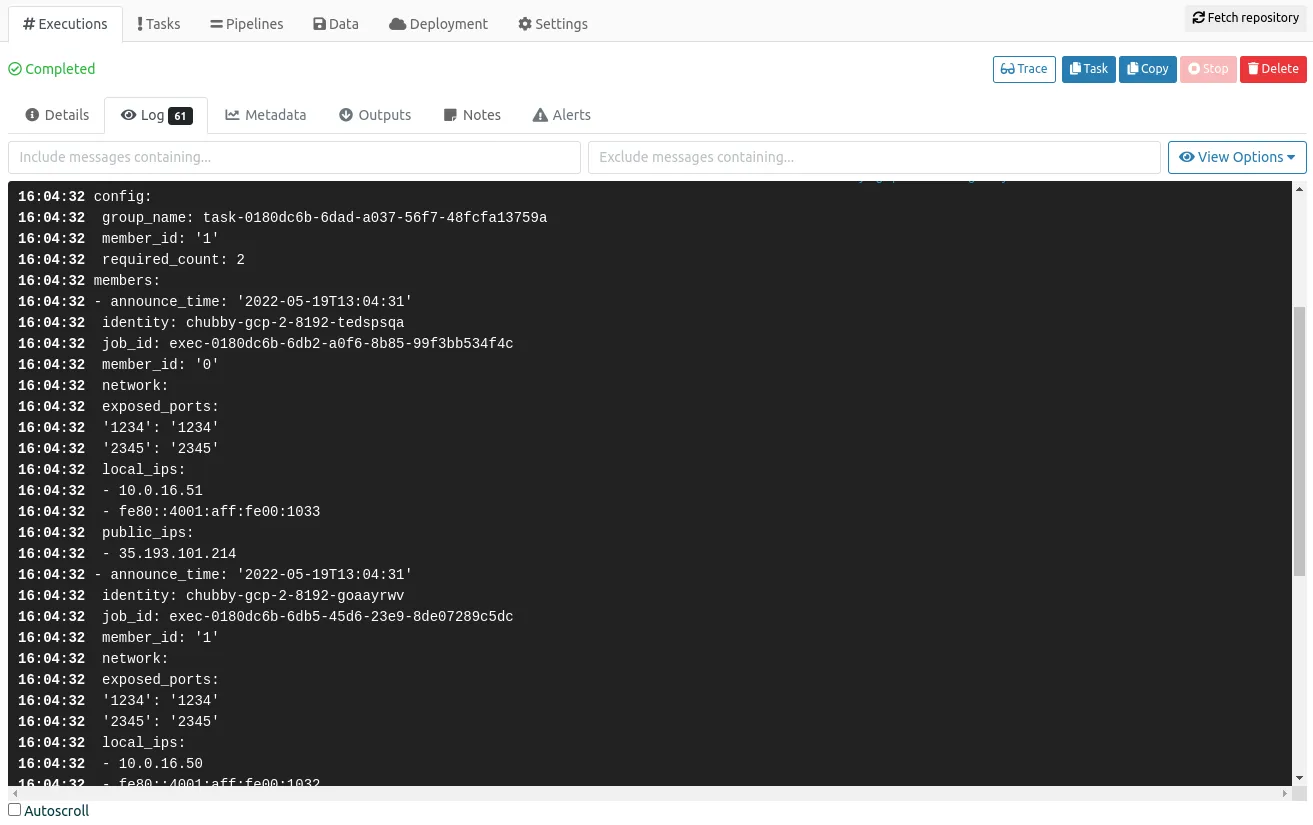
Summary
Distributed learning, mainly done as data parallelism, will save businesses months on model automatization. Doing it with Valohai and its distributed tasks makes sense because, unlike other platforms, we are not locking you up within a single framework. We respect your creative process — you do you.
Distributed tasks are definitely a thing. If you want to try them out, reach out to our support. If you are not sure yet whether this feature or Valohai as a platform suits your use case, be sure to book a call, and our experts will help you sort things out.