Finding the right subreddit to submit your post can be tricky, especially for people new to Reddit. There are thousands of active subreddits with overlapping content. If it is no easy task for a human, I didn’t expect it to be easier for a machine. Currently, redditors can ask for suitable subreddits in a special subreddit: r/findareddit .

A Reddit user asking for subreddit suggestions.
In this article, I share how to build an end-to-end machine learning pipeline and an actual data product that suggests subreddits for a post. You get access to the data, code, model, an API endpoint and a user interface to try it yourself .
Collecting 4M Reddit posts from 4k subreddits
I used the Python Reddit API Wrapper ( PRAW ) to ask for the 5k most popular subreddits but only got back 4k of them. For each subreddit, I collected the newest 1k post’s titles and texts up to the 17th of March. I exported the data to a CSV available for download on S3.
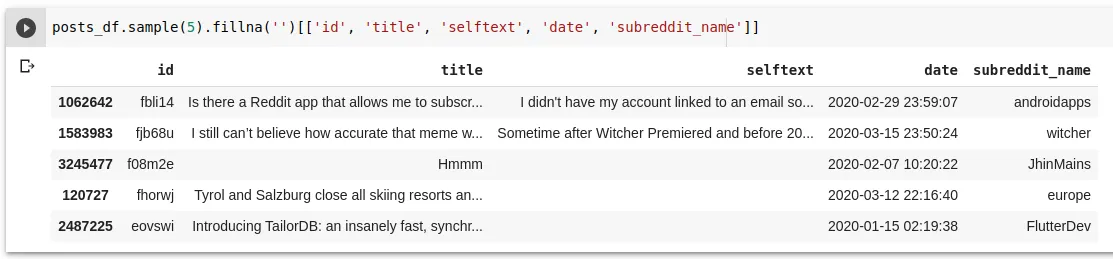
DataFrame sample from 4M Reddit posts.
This dataset is far from perfect in terms of data quality. Some subreddits are too general, others are very similar to each other and some posts don’t have enough information in the text to know where they should be posted. A previous approach selected a subset of 1k subreddits that are more coherent topic-wise . While it’s true that such data selection will make the model achieve higher scores on the test split, it won’t necessarily be more useful on real data as it will miss a lot of subreddits.
It’s known that data cleaning can have a high impact on a model’s performance and data scientists spend up to 80% of time cleaning data. Instead of spending a lot of time early on data transformations, I prefer to directly build an end-to-end baseline as fast and as simple as possible. Once I have got the first results, I can run version controlled experiments to see the impact of each transformation. Proceeding otherwise, you may end up with a more complex baseline and ignoring the impact of each transformation.
As a Data Scientist, I often overestimate the impact of a data transformation. By letting the final user interact with the model early on, you can learn and iterate faster. Also, as you start serving ML models on production you’ll experience other challenges like retraining and releasing new model versions to avoid a common problem called concept drift .
Training a text classifier with fastText
In a previous article, I built a generic ML pipeline for text classification using fastText . I reuse that code to train it on the Reddit dataset using the title and selftext as features and the subreddit_name as the label. In the training dataset each post is assigned to a single label, but it’s natural to instead think of the problem as multi-label. In multi-label text classification, each post is assigned to each subreddit by a probability.
Released by Facebook, fastText is a neural network with two layers. The first layer trains word vectors and the second layer trains a classifier. As noted in the original paper , fastText works well with a high number of labels. The collected dataset contains 300M words, enough to train word vectors from scratch with Reddit data. On top of that, fastText creates vectors for subwords controlled by two parameters, minn and maxn, to set the minimum and maximum character spans to split a word into subwords. On Reddit, typos are common and specific terms may be out of vocabulary if not using subwords.
The machine learning pipeline
The machine learning pipeline consists of 5 executions that exchange data through Valohai pipelines . Each execution is a Python CLI and you can find the code of each one on Github and more details about how to create a pipeline that runs on the cloud in the previous article .
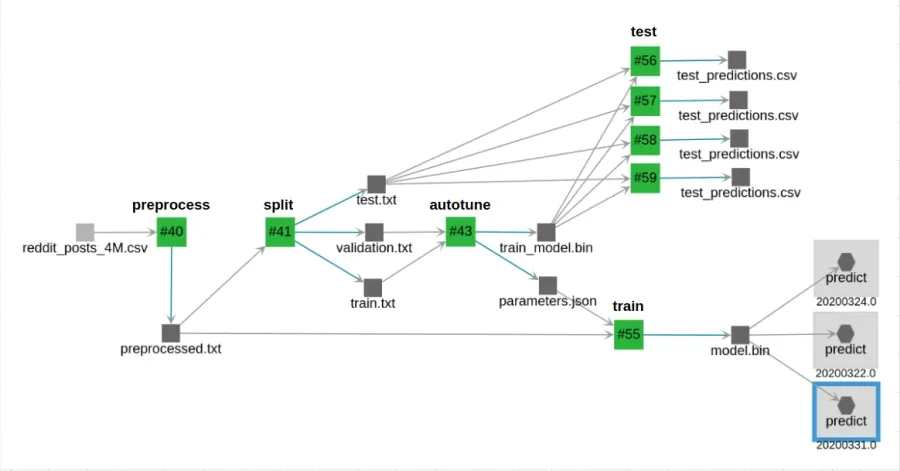
End-to-end ML pipeline generated from dependencies between data artifacts, executions and API endpoints.
The text features are concatenated, transformed to lowercase and punctuation is removed. Then the data is split into train (80%), validation (10%) and test (10%). I set the autotune command to run for 24 hours on a cloud machine with 16 cores to find the best parameters on the validation dataset. Finally, the model is retrained on all the data and the final metrics are reported on the test dataset. For each execution, Valohai takes care of launching and stopping a cloud machine with the proper environment, code, data and parameters.
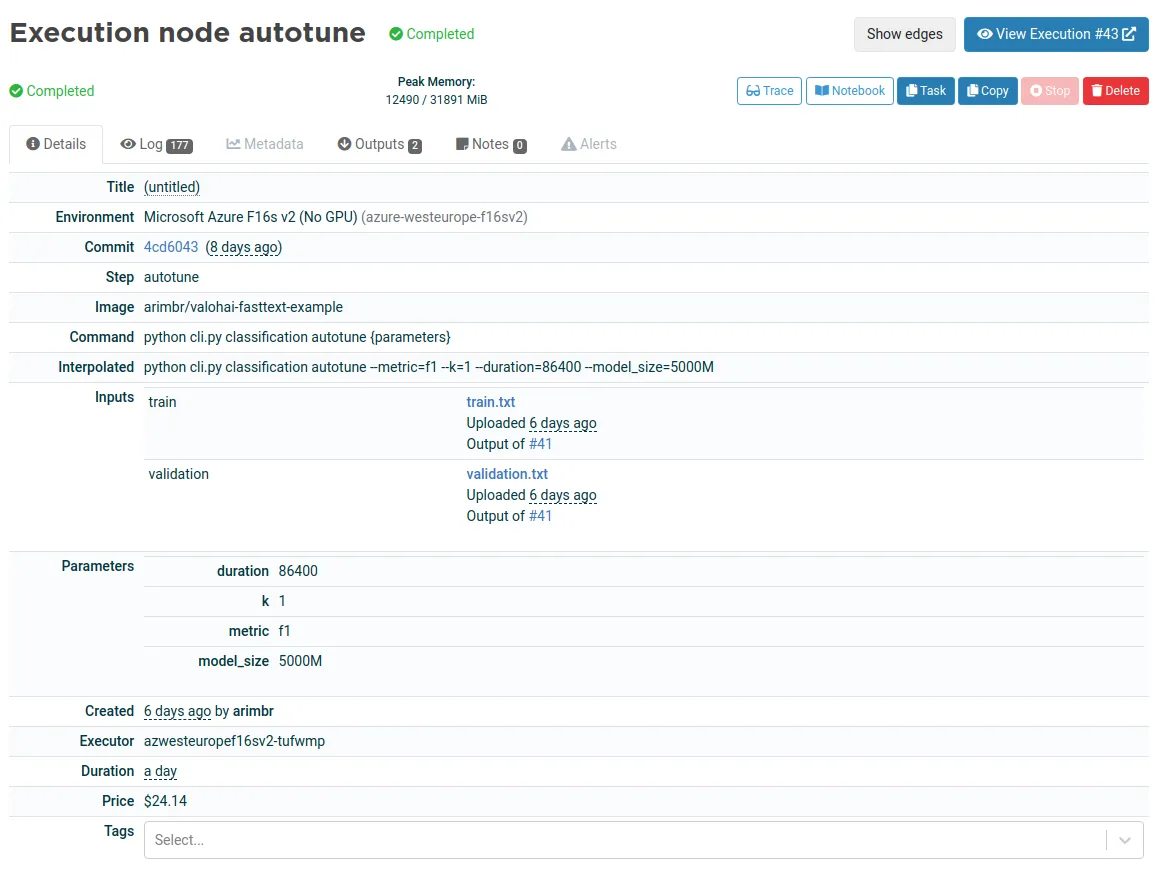
Exploring the predictions and metrics
Classification tasks can be evaluated with classic metrics such as precision, recall and f1-score. The autotune execution logs the best parameters and reports a f1-score of 0.41 in the validation dataset. The autotune execution smartly chose 9 different sets of parameters to decide on a final model that trained for 100 epochs, word vectors of 92 dimensions, n-grams of up to 3 words and subwords from 2 to 5 characters. That results on a vocabulary size of 3M words (including subwords) and a model that trains on 7 hours and weighs 2 GB.
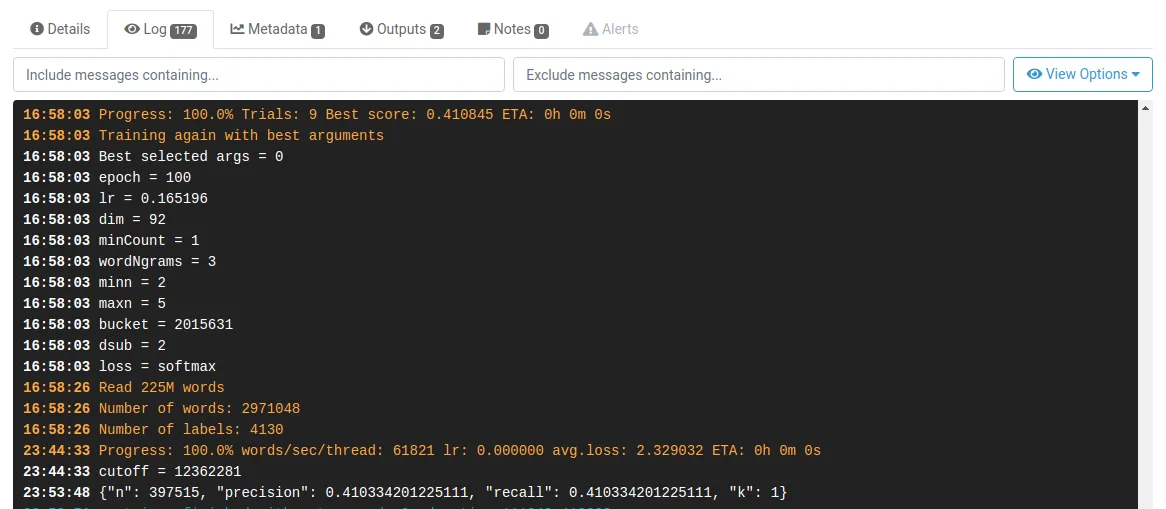
Logs from the autotune execution.
In extreme multi-label text classification tasks, it’s common to also report metrics P@k (precision when taking the first k predictions) and R@k (recall when taking the first k predictions). Below, we can see the precision and recall on the test dataset for different k values. R@k goes from 0.4 when taking one prediction (k=1) to 0.71 when taking twenty predictions (k=20).
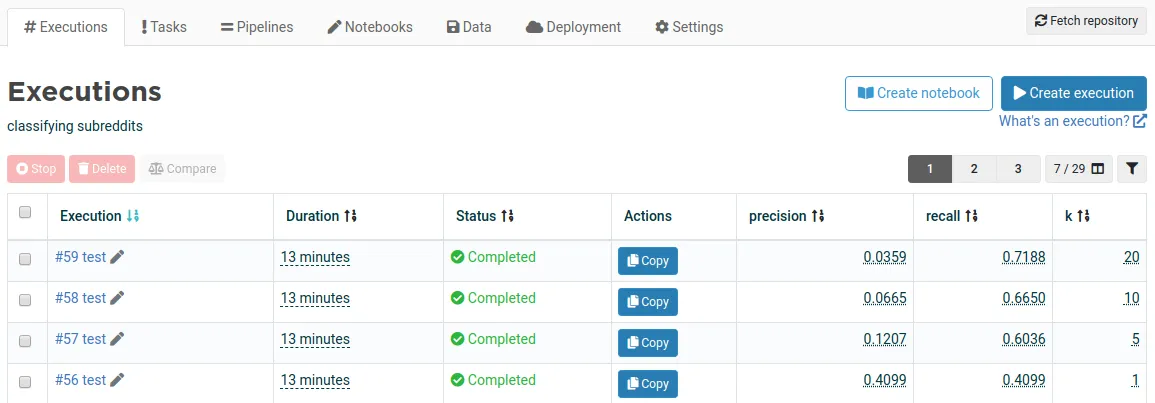
Comparing metrics for the test execution for different k values
Classification report by label
Naturally, metrics vary between subreddits. It’s interesting to explore the f1-score histogram by subreddits and the relationship between the prediction probability and the f1-score. For that, I created a Google Colab Notebook to make graphs based on test_predictions.csv, the output of the test execution with k=20.
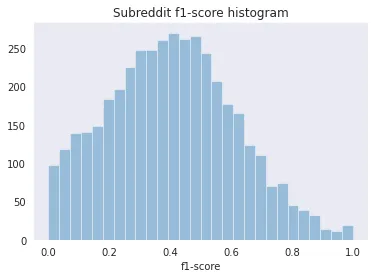
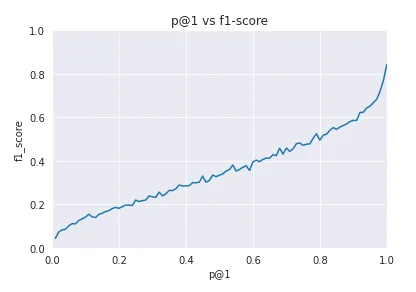 There is a positive correlation between the f1-score and P@1, the probability of the first prediction given by the model. Still, p@1 lacks behind the f1-score on the test dataset. For example, when the model says that the first suggestion has a probability of 0.8, it should be taken as 0.5. It’s possible that the model needs to be trained for more epochs to better adjust the probabilities.
There is a positive correlation between the f1-score and P@1, the probability of the first prediction given by the model. Still, p@1 lacks behind the f1-score on the test dataset. For example, when the model says that the first suggestion has a probability of 0.8, it should be taken as 0.5. It’s possible that the model needs to be trained for more epochs to better adjust the probabilities.
Metrics are important but they should not stop you from looking at the data. Metrics tell you exactly where to look. For example, if we consider the subreddits for which the f1-score is close to 1, we’ll find good examples of a feature leak.
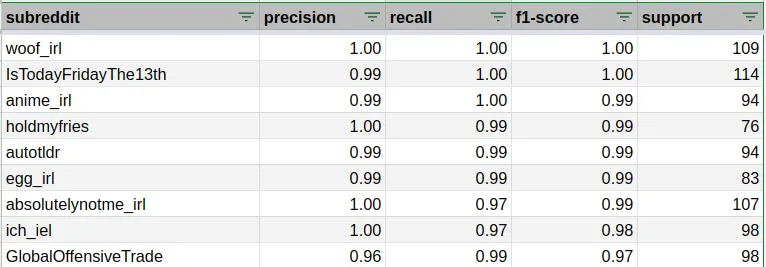
In the case of subreddits r/wood_irl and r/anime_irl most of the posts have as title the subreddit name, no text and an image. Take for example the subreddit r/holdmyfries , most posts start with HMF, a feature leak that may stop the model from learning from other text features. One last example. The subreddit r/IsTodayFridayThe13th has a daily post with the same title and a lot of excitement in the comments when the answer is yes. Fascinating!
On the other hand, looking at the worst-performing subreddits I find out that text features may not be enough in some cases and you have to look at the picture. Also, several popular subreddits (r/AskReddit) don’t necessarily have a topic coherence.
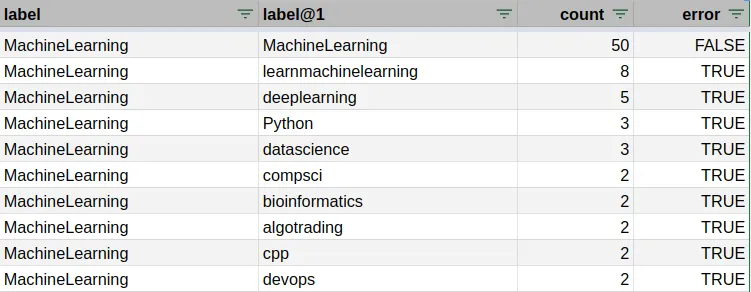
The most coherent topic-wise subreddits have average f1-scores, like for r/MachineLearning with a f1-score of 0.4. The precision is lower than the recall, meaning that there are more posts from other subreddits that are assigned to it by the model than the opposite.
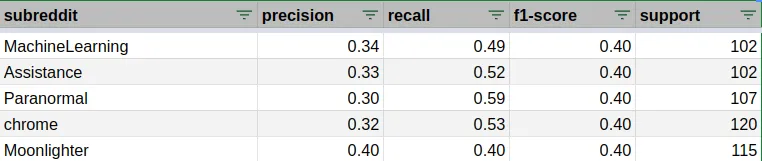
Subreddits confusion matrix
The model not only contradicts the subreddits assigned by the users, but also the label space. If you have a look at the confusion matrix between subreddits, you’ll find subreddits with similar topics.
I uploaded the confusion matrix in long format in the sheet confusion_matrix_gt2 in this Google Spreadsheet so you can use it to find similar subreddits. For example, here are 10 pairs of subreddits that are often confused by the model. The label column refers to the human choice and the label@1 column to the first model choice.
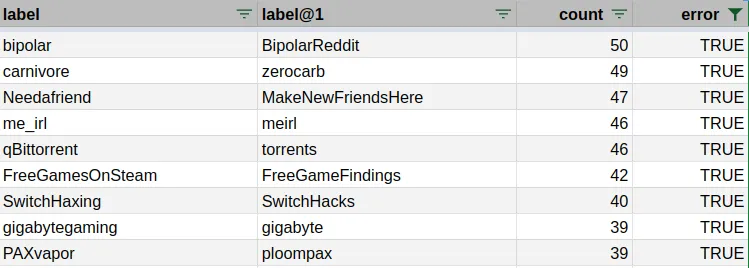 Looking at the subreddits similar to r/MachineLearning, it gives some insights into why it’s not always possible for the model to predict the human choice. There are often multiple possible choices. Hopefully, the model can still learn with some noise and even correct the human choice when it predicts a different subreddit with a high probability.
Looking at the subreddits similar to r/MachineLearning, it gives some insights into why it’s not always possible for the model to predict the human choice. There are often multiple possible choices. Hopefully, the model can still learn with some noise and even correct the human choice when it predicts a different subreddit with a high probability.
Creating a prediction API endpoint with FastAPI
Even with all those limitations in mind, the trained model with R@5 of 0.6 can be useful. That means that two-thirds of the time, the first five predictions include the subreddit chosen by the human on the test dataset. Alternative predictions can help the user discover new subreddits and decide by himself whether to post there.
In order to test the model with the latest post submissions, I created an API endpoint using FastAPI . FastAPI is a Python web framework used by the machine learning teams at Uber and Microsoft because of its compact code, data validation, automatic documentation and high-performance thanks to Starlette and Pydantic.
The code in api.py is enough to declare the features and predictions models, load the trained model in memory and create a prediction endpoint.
View code on GitHubDeploying the API endpoint to Valohai
Using Valohai’s Deployment feature for online inference,
I declare an endpoint in the valohai.yaml configuration file with a Docker image and a server command.
Complete valohai.yaml on Github.
Through the Valohai UI, I can link the endpoint to a model generated by a previous execution. It’s all version-controlled so that you can A/B test different versions, do canary releases and rollback if things go awry.
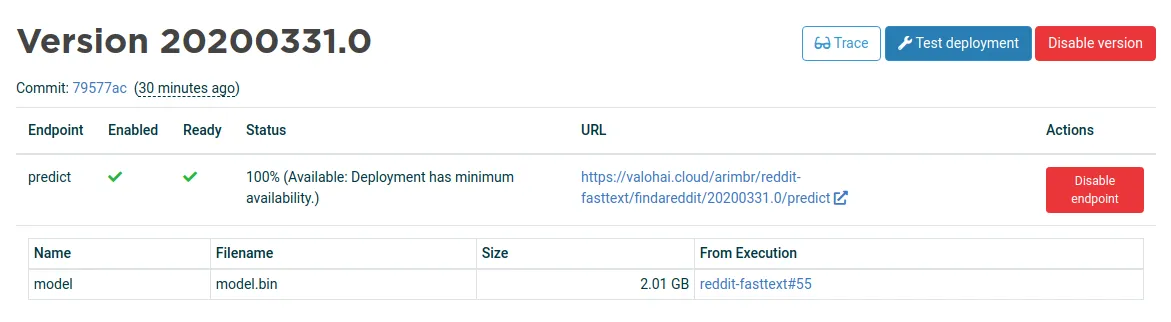
You can call the API endpoint with curl and make a POST request with the text feature on the body of the request:
curl -X POST " <https://valohai.cloud/arimbr/reddit-fasttext/findareddit/production/predict?k=5> " -d "{\\"text\\":\\"I’m wanting to learn the basics of growing food at home. All indoors as I don’t have a suitable yard. So things that can grow in a pot.\\"}"You should get a JSON response like:
{
"predictions": [
{ "label": "IndoorGarden", "probability": 0.33 },
{ "label": "gardening", "probability": 0.06 },
{ "label": "plantclinic", "probability": 0.04 },
{ "label": "IWantToLearn", "probability": 0.03 },
{ "label": "homestead", "probability": 0.03 }
]
}Those seem all like reasonable predictions to a Reddit user asking for subreddits suggestions in a recent post . Other users suggested r/hydro and r/aerogarden which the model missed. Those two subreddits were not part of the 4k most popular subreddits. That makes me think that one of the easiest ways to make the model more useful is to simply train it on more subreddits.
Conclusions and what’s next?
We’ve seen how to go from a problem definition to an API endpoint to suggest subreddits by training a text classifier. I hope you learned a bit more about multi-label text classification and common issues when working with noisy data. If you have a dataset with text and labels, you can create a similar ML product with a few clicks on Valohai by following the previous tutorial .
I already see several areas of improvement to make the model more useful. From collecting more data to trying a different NLP model sensible to the irony and different styles found in each subreddit, to improving the UI by adding more information such as the number of subreddit subscribers, to adding extra features. It’s always hard to decide what to work on next. I count on you to give it a try and report back.
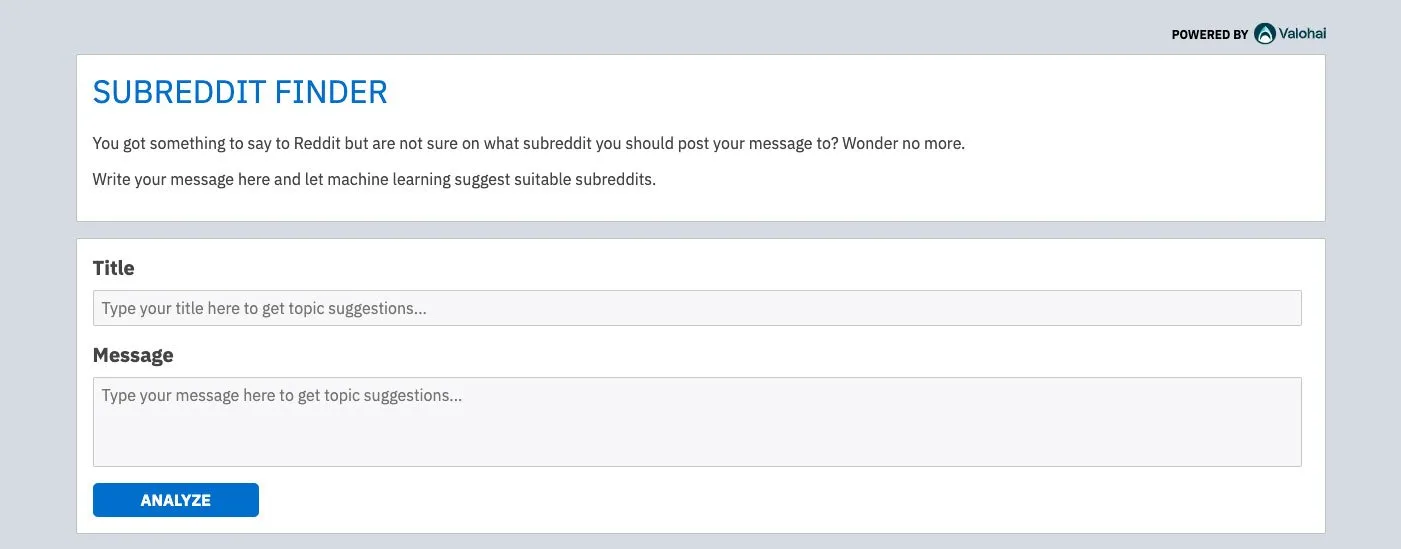
Too lazy to open a terminal and run a CURL command? We got you covered. The Valohai team crafted a UI to interact with the model in the browser .
 Personally, I can’t wait to share in the following article how the performance of the model evolves with time as there is a natural concept drift in what users post on Reddit. I will collect new data, compare the model metrics and build a CI/CD machine learning system to retrain and release a new model.
Personally, I can’t wait to share in the following article how the performance of the model evolves with time as there is a natural concept drift in what users post on Reddit. I will collect new data, compare the model metrics and build a CI/CD machine learning system to retrain and release a new model.
Useful links
- MLOps: How to Get Started with MLOps.
- More about machine learning pipelines
- S3: Download the Reddit posts dataset.
- Github: ML pipeline code and Valohai configuration.
- Google Spreadsheet: Metrics and confusion matrix by subreddit.
- Google Colab Notebook: Data exploration and reports.
- Valohai: UI to try the model.