PocketFlow is an open-source framework from Tencent to automatically compress and optimize deep learning models. Especially edge devices such as mobile phones or IoT devices can be very limited on computing resources so sacrificing a bit of model performance for a much smaller memory footprint and lower computational requirements is a smart tradeoff.
PocketFlow offers a toolkit to improve or retain inference efficiency in a compressed model with little or no performance degradation. With the desired compression and/or acceleration ratios it will automatically choose proper hyperparameters to generate a highly efficient compressed model for deployment.
In this article we show an example of a ResNet-20 model pre-trained with the CIFAR-10 dataset and compress it with PocketFlow on the Valohai platform.
Getting Started
Start by signing up as Valohai user if you haven’t already. After signing in, create a new project and link it with example repository using the settings/repository tab.
Repository: https://github.com/valohai/pocketflow-example
All the settings and parameters are set to very light defaults for quick test run, so one can safely test the execution as is.
Inputs
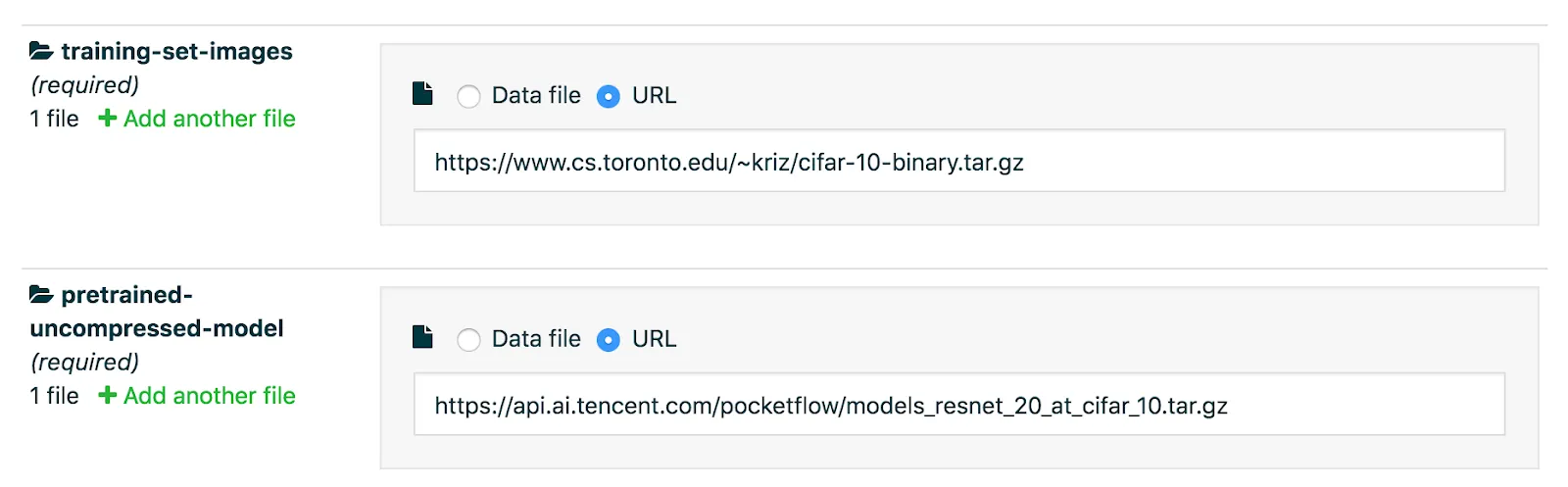
Valohai downloads the necessary input data for you based on the configuration file. In this case it is the pre-trained model and the dataset it was trained with.
For this example we are using ResNet-20 model and CIFAR-10 dataset.
Evaluating the Uncompressed Model
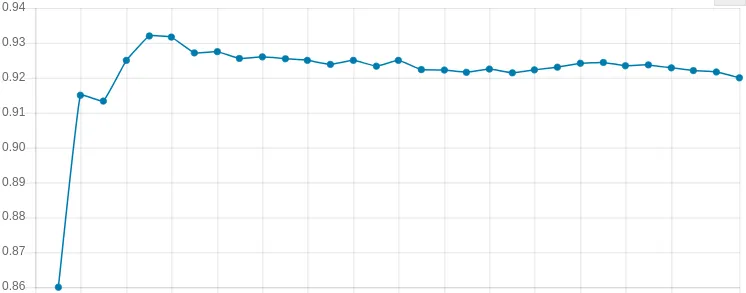
Before using PocketFlow to compress a model, we need to measure the model’s current performance so we can compare it to the compressed performance afterwards.
Our baseline uncompressed accuracy comes out as approximately 92% .
Compression
PocketFlow comes with three categories of compression algorithms.
Channel pruning is an algorithm that trims entire channels of a convolutional neural network (CNN), based on their impact for the performance of the model.
Weight sparsification is the same thing conducted at a lower level. Instead of pruning entire channels, it trims out individual weights.
Weight quantization aims to figure out which high accuracy (for example 32-bit) weights can be replaced with lower accuracy (for example 8-bit) counterparts, without sacrificing model performance.
In this example we will execute a specific channel pruning algorithm called discrimination-aware channel pruning (Zhuang et al., 2018).
More details about the algorithm:
For our execution, we will use these parameters:
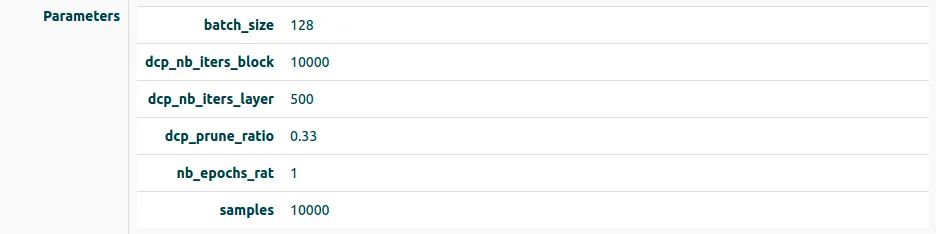
batch_size is how many images to run through per batch.
dcp_nb_iters_block and dcp_nb_iters_layer tell the algorithm how many iterations to use per block and layer when figuring out which channels to prune.
dcp_prune_ratio is how much to compress. In this case it is 0.33 , which means compressed model will be ⅓ the size of the original.
np_epochs_rat is the ratio of how much we re-train the model after the compression. Higher value simply trains longer.
samples is how many images we use for final evaluation.
Evaluating Compressed Model
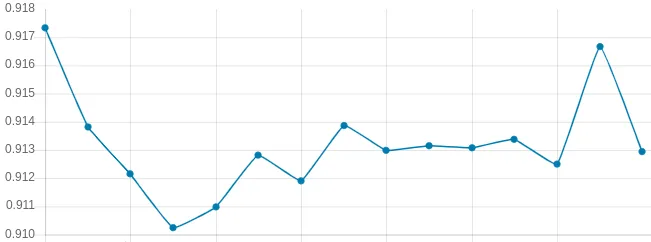
After the compression, the model still needs to be retrained and finally we can measure the actual compressed performance.
From the graph above, we see that compressing the model down to ⅓ of its original size had only a small effect on it’s performance.
Final accuracy was 91.3% , which is only a 0.7% drop from the original.