
Support for Spark has been one of the most requested features as Spark has become almost ubiquitous for data scientists and engineers working with structured data. We’ve heard the calls and Valohai now supports Spark natively. Read on to find out more about what this means and how you can use it.
What Does Spark as a First-Class Citizen Mean?
Meet Cluster Executions
A fundamental concept of Valohai is the Execution. Any time you run any code on Valohai, it creates an execution that is tracked and that can be reproduced in the future.
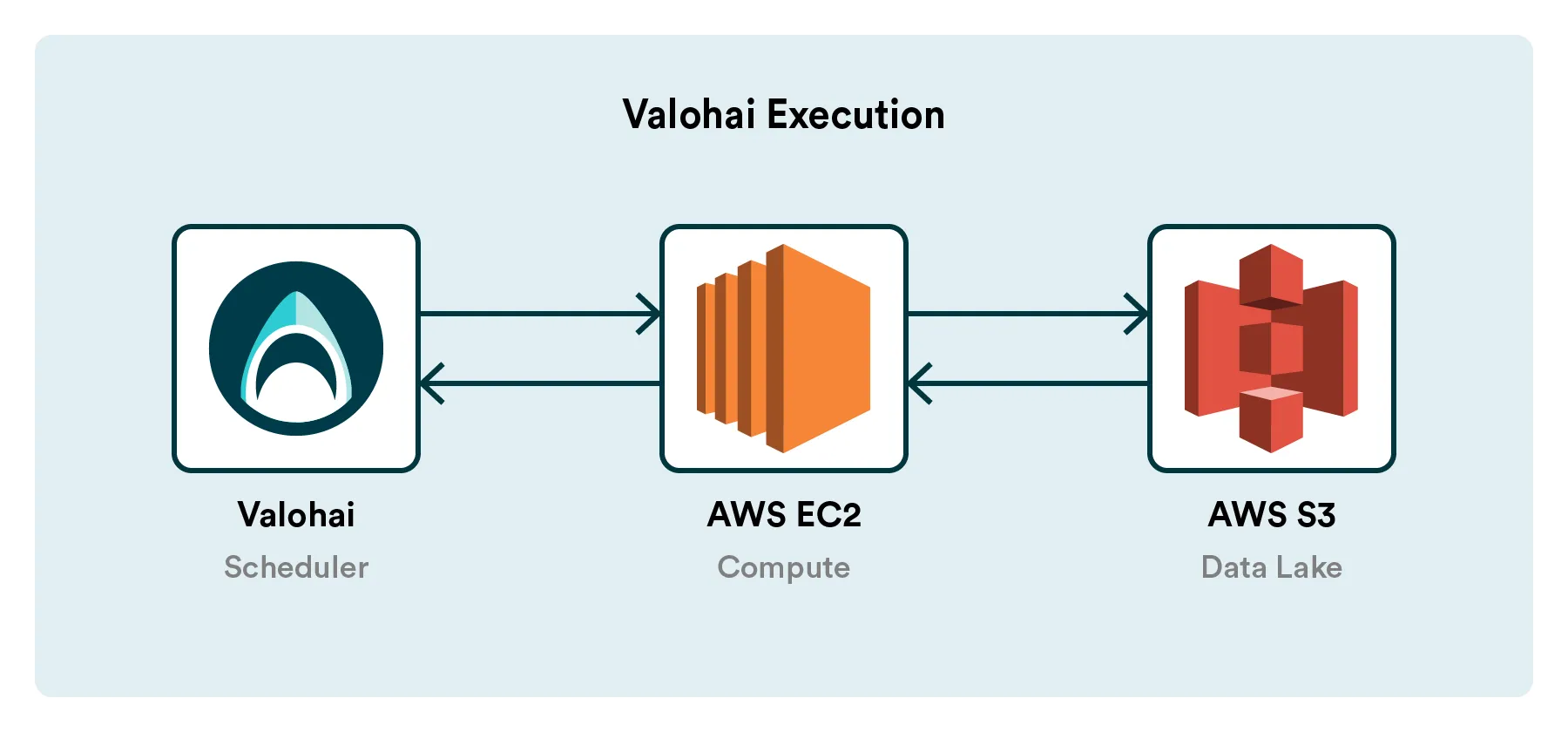
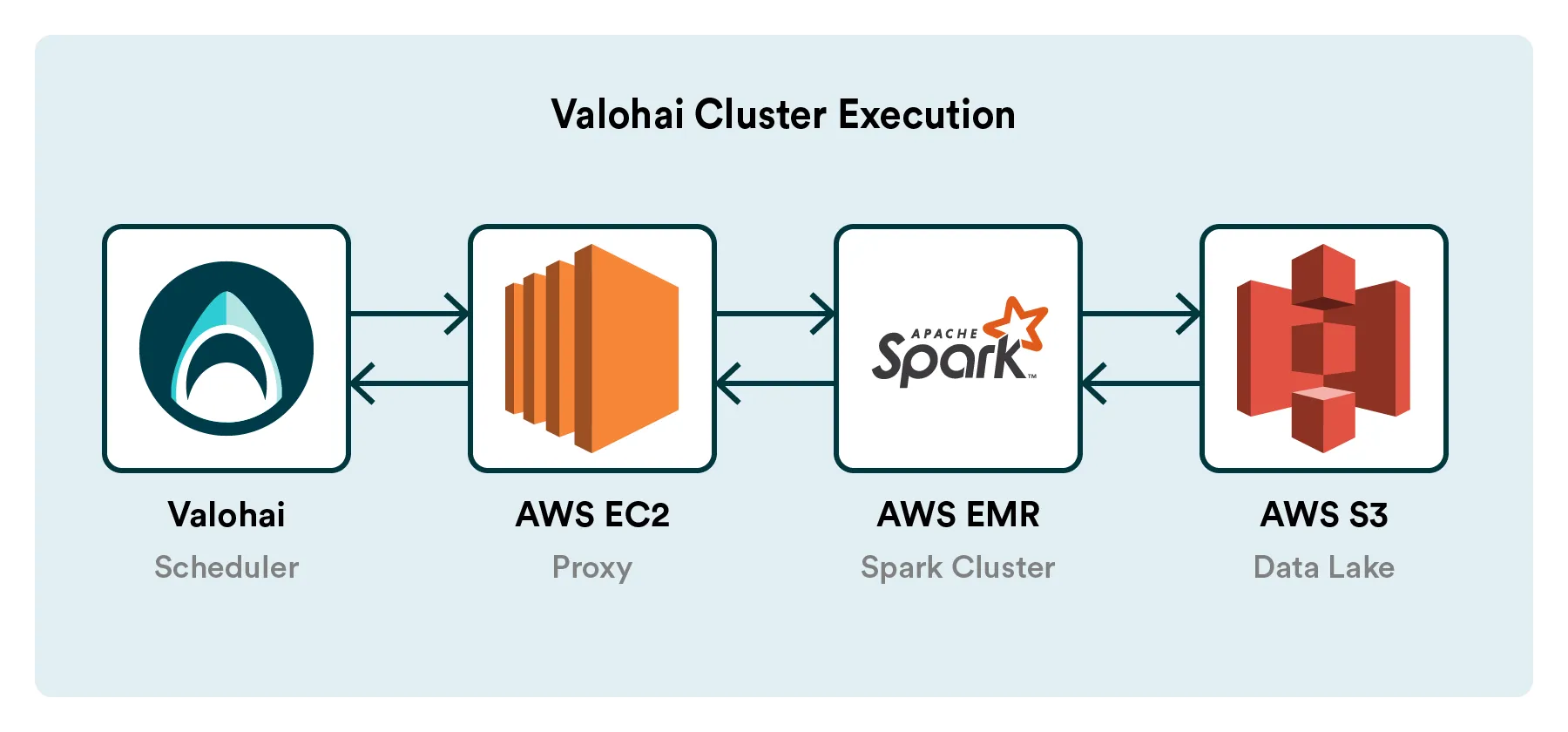
The platform will feature a new type of execution called Cluster Execution, enabling you to run code on a Spark cluster. The Valohai cluster execution will have 1:1 parity with our standard execution. Inputs, parameters, code are pushed into the execution and versioned, and logs, metadata, outputs are pulled out and versioned.
This pattern will function precisely the same for both the classic and the cluster execution. It also means you can freely mix traditional and cluster executions in your pipelines, for example, to run the big data pre-processing step on a cluster and then train with the results on a beefy EC2 GPU machine. It’s the best of both worlds!
As of today, we’ve released support for the AWS EMR transient (on-demand) cluster. The transient cluster will always be brought up and brought down automatically for every cluster execution, just like the classic workers are brought up and brought down under the hood for the classic Valohai execution today. We’ll be following up on this release with support for persistent clusters on AWS EMR. Similar to our classic executions, which now support the most popular clouds and instance types (AWS, GCP, Azure, OpenStack), we’ll continue to expand our support for different data lakes.
Using Cluster Executions in Valohai
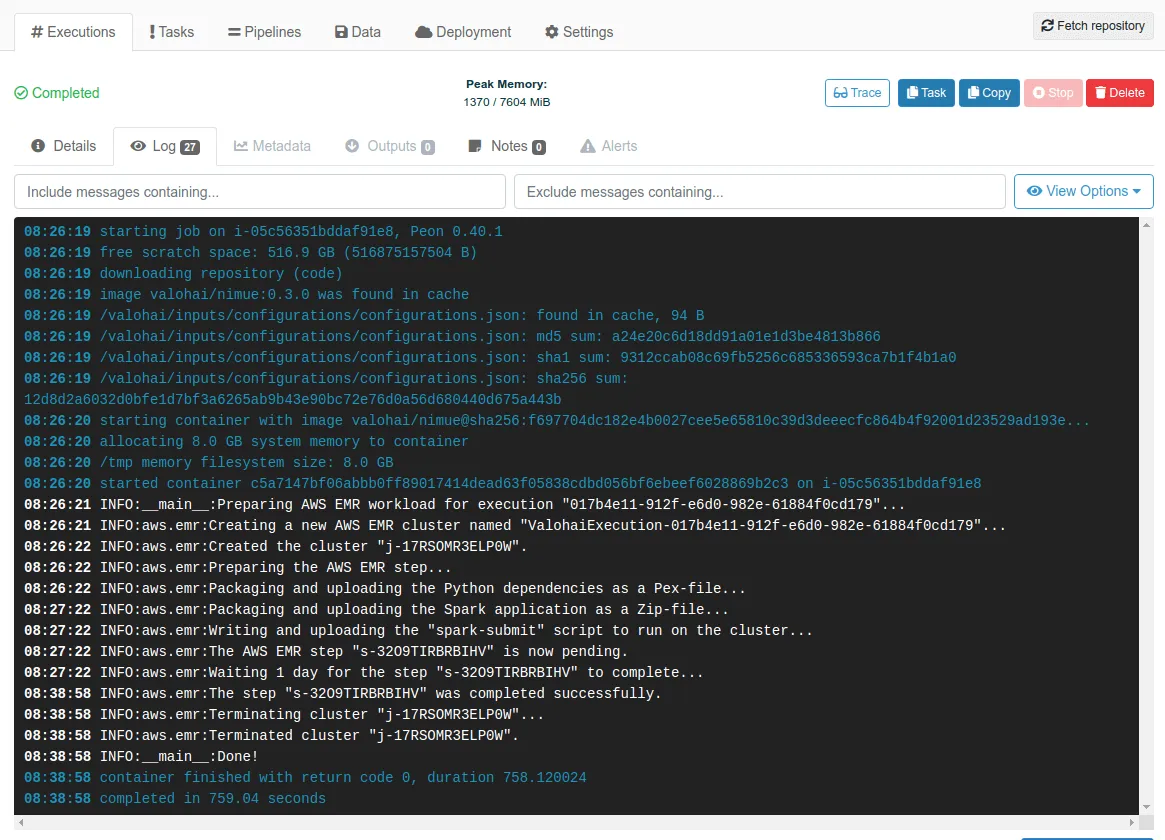
Valohai Cluster Executions are provisioned, monitored and versioned exactly like the vanilla Executions.
How Does This Connect With Our Product Vision?
Machine learning is not an isolated data science experiment but an integral part of the future of software. To develop and maintain a single production model, data scientists need to connect with a plethora of tools and platforms (from GitHub and Snowflake to AWS and Tensorboard) — all with their unique APIs and learning curves.
We see the future of Valohai as a hub to connect all your resources and command them through a single API. This will allow R&D teams to create machine learning systems without knowing and maintaining each dependent technology.
I’d love to leave you with a question: What is a technology in your machine learning stack that you are having difficulty with (and would like to be integrated with Valohai)? You can tweet at us (@valohaiai)!