This is the first part of a tutorial series about reinforcement learning. We will start with some theory and then move on to more practical things in the next part. During this series, you will not only learn how to train your model, but also what is the best workflow for training it in the cloud with full version control using the Valohai deep learning management platform.
When to use reinforcement learning?
 Reinforcement learning is useful when you have no training data or specific enough expertise about the problem.
Reinforcement learning is useful when you have no training data or specific enough expertise about the problem.
On a high level, you know WHAT you want, but not really HOW to get there. After all, not even Lee Sedol knows how to beat himself in Go.
Luckily, all you need is a reward mechanism, and the reinforcement learning model will figure out how to maximize the reward, if you just let it “play” long enough. This is analogous to teaching a dog to sit down using treats. At first the dog is clueless and tries random things on your command. At some point, it accidentally lands on its butt and gets a sudden reward. As time goes by, and given enough iterations, it’ll figure out the expert strategy of sitting down on cue.
Accountant in a dungeon example

This is kind of a bureaucratic version of reinforcement learning. An accountant finds himself in a dark dungeon and all he can come up with is walking around filling a spreadsheet.

What the accountant knows:
- The dungeon is 5 tiles long
- The possible actions are FORWARD and BACKWARD
- FORWARD is always 1 step, except on last tile it bumps into a wall
- BACKWARD always takes you back to the start
- Sometimes there is a wind that flips your action to the opposite direction
- You will be rewarded on some tiles
What the accountant doesn’t know:
- Entering the last tile gives you +10 reward
- Entering the first tile gives you +2 reward
- Other tiles have no reward
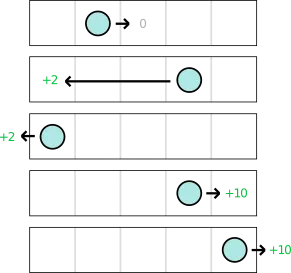
The accountant, being an accountant, is going to follow a safe (but naive) strategy:
- Always choosing the most lucrative action based on your accounting
- If the accounting shows zero for all options, choose a random action
Let’s see what would happen:
The accountant seems to always prefer going BACKWARD even though we know that the optimal strategy is probably always going FORWARD. The best rewards (+10) are at the end of the dungeon after all. Because there is a random element that sometimes flips our action to the opposite, the accountant actually sometimes reaches the other end unwillingly, but based on the spreadsheet is still hesitant to choose FORWARD. Why is this?
Well it is simply because he has chosen a very greedy strategy. During the very short initial randomness, the accountant might willingly choose to go FORWARD once or twice, but as soon as he chooses BACKWARD once, he is doomed to choose that forever. Playing this dungeon requires long term planning and declining smaller immediate awards to reap the bigger ones later on.
What is Q-learning?
Q-learning is at the heart of all reinforcement learning. AlphaGO winning against Lee Sedol or DeepMind crushing old Atari games are both fundamentally Q-learning with sugar on top.
At the heart of Q-learning are things like the Markov decision process (MDP) and the Bellman equation . While it might be beneficial to understand them in detail, let’s bastardize them into a simpler form for now:
Value of an action = Immediate value + sum of all optimal future actions

It is like estimating the financial value of a college degree versus dropping out. You need to consider, not just the immediate value from your first paycheck, but the sum of all future paychecks of your lifetime. One action always leads to more actions and the path you take will always be shaped by your first action.
That said, focusing solely on the action is not enough. You need to consider the state you are in when performing it. It is quite different to enroll to college when you are 17 vs. being 72. The first might be a financially positive bet, while the latter probably isn’t.
So how do you know which future actions are optimal? Well – you don’t. What you do is take the optimal choice based on the information you have available at the time.
Imagine you could replay your life not just once, but 10,000 times. At first you would go about pretty randomly, but after a few thousand tries, you’d have more and more information on the choices that yield the best rewards. In Q-learning the “information you have” is the information gathered from your previous games, encoded into a table.
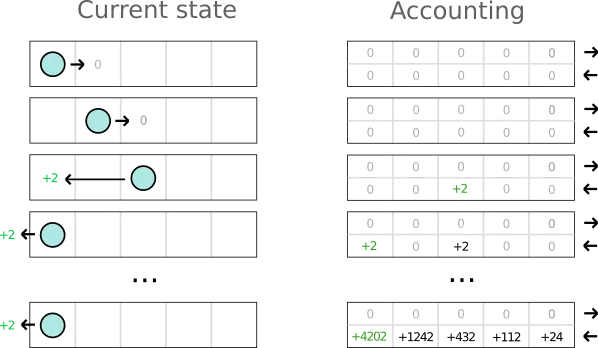
So in a sense you are like the accountant in the previous example, always carrying a spreadsheet around. You will update and read your spreadsheet in a more nuanced way, though. And you will also call it a Q-table instead of a spreadsheet, because it sounds way cooler, right?
The Q-learning algorithm
This is how the Q-learning algorithm formally looks like:

It looks a bit intimidating, but what it does is quite simple. We can summarize it as:
Update the value estimation of an action based on the reward we got and the reward we expect next.
This is the fundamental thing we are doing. The learning rate and discount , while required, are just there to tweak the behavior. The discount will define how much we weigh future expected action values over the one we just experienced. The learning rate is sort of an overall gas pedal. Go too fast and you’ll drive past the optimal, go too slow and you’ll never get there.
But this algorithm is not enough – it just tells us how to update our spreadsheet, but nothing about how to use the spreadsheet to behave in the dungeon!
Gambler in a dungeon example

Let’s see how we will act in a dungeon with our fancy Q-table and a bit of gambling. Instead of the by-the-book strategy used by our accountant, we will choose something more nuanced
Our strategy:
- Choose the most lucrative action from our spreadsheet by default
- Sometimes gamble and choose a random action
- If the accounting shows zero for all options, choose a random action
- Start with 100% gambling (exploration), move slowly toward 0%
- Use discount = 0.95
- Use learning_rate = 0.1
Why do we need to gamble and take random actions? For the same reason that the accountant got stuck. Since our default strategy is still greedy, that is we take the most lucrative option by default, we need to introduce some stochasticity to ensure all possible <state, action> pairs are explored.
Why do we need to stop gambling towards the end and lower our exploration rate? It is because the best way to reach an optimal strategy is to first explore aggressively and then slowly move to more and more conservatism. This mechanism is at the heart of all machine learning.
Enough talk. Our gambler is entering the dungeon!

Phew! That was a lot of stuff.
Notice that for the sake of example, we did a lot of gambling just to prove a point. And not just gambling, but we biased the coin flips to go right, so this would normally be a very unusual first dozen steps!
When compared to the strategy of the accountant, we can see a clear difference. This strategy is slower to converge, but we can see that the top row (going FORWARD) is getting a higher valuation than the bottom one (BACKWARD).
Notice also how after the initial +10 reward, the valuations start to “leak” from right to left on the top row. This is the fundamental mechanism that allows the Q table to “see into the future”. News about the well rewarded things that happened on the last tile are slowly flowing left and eventually reach the left-most part of our spreadsheet in a way that allows our agent to predict good things many steps ahead.

If you got confused by the information overload of the step-by-step run above, just meditate on this one image, as it is the most important one in this article. If you understand why the information “leaks” and why it is beneficial then you will understand how and why the whole algorithm works.
That’s it! In the next part we be a tutorial on how to actually do this in code and run it in the cloud using the Valohai deep learning management platform!