Apache Airflow is a popular platform to create, schedule and monitor workflows in Python. It has more than 15k stars on Github and it’s used by data engineers at companies like Twitter, Airbnb and Spotify.
If you’re using Apache Airflow, your architecture has probably evolved based on the number of tasks and their requirements. While working at Skillup.co, we first had a few hundred DAGs to execute all our data engineering tasks. Then we started doing machine learning.
We wanted to keep on using Airflow to orchestrate machine learning pipelines but we soon realized that we needed a solution to execute machine learning tasks remotely .
In this article, we’ll see:
- The different strategies for scaling the worker nodes in Airflow.
- How machine learning tasks differ from traditional ETL pipelines.
- How to easily execute Airflow tasks on the cloud.
- How to get automatic version control for each machine learning task.
Scaling Apache Airflow with Executors
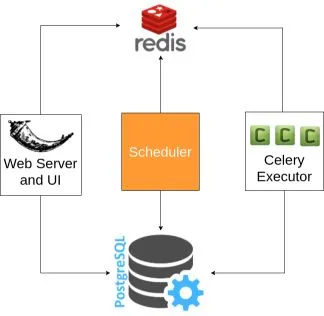
Apache Airflow has a multi-node architecture based on a scheduler, worker nodes, a metadata database, a web server and a queue service.
One of the first choices when using Airflow is the type of executor. The executor communicates with the scheduler to allocate resources for each task as they’re queued. The difference between executors comes down to the resources they’ve available.
Sequential Executor
The default executor makes it easy to test Airflow locally. It runs tasks sequentially in one machine and uses SQLite to store the task’s metadata.
Local Executor
The local executor can run tasks in parallel and requires a database that supports parallelism like PostgreSQL. While you can run the local executor in production, it’s common to migrate to the Celery executor to improve availability and scalability.
Celery Executor
The Celery executor requires to set up Redis or RabbitMQ to distribute messages to workers. Airflow then distributes tasks to Celery workers that can run in one or multiple machines. This is the executor that we’re using at Skillup.co to be able to run up to 256 concurrent data engineering tasks.
Kubernetes Executor
The Kubernetes executor creates a new pod for every task instance. It allows you to dynamically scale up and down based on the task requirements.
Scaling Apache Airflow with operators
Another way to scale Airflow is by using operators to execute some tasks remotely. In 2018, Jessica Laughlin argued that we’re all using Airflow wrong and that the correct way is to only use the Kubernetes operator. Instead of a growing list of functionality-specific operators, she argued that there should be a single bug-free operator to execute any arbitrary task.
Kubernetes Operator
The Kubernetes operator will launch a task in a new pod. When you have a set of tasks that need to run periodically, I find it a better idea to use the Kubernetes operator only for tasks with specific requirements.
The main problem I see with the Kubernetes operator is that you still need to understand the Kubernetes configuration system and set up a cluster. For example, Dailymotion deployed Airflow in a cluster on Google Kubernetes Engine and decided to also scale Airflow for machine learning tasks with the KubernetesPodOperator.
In our case, we were a small data team with little resources to set up a Kubernetes cluster. We wanted to focus on building machine learning models and not managing infrastructure.
How Machine Learning Tasks Differ from ETL Tasks?
At Skillup.co we had to build and deploy several data products in a year as a small team. We knew we wanted to build our models using open source libraries, from classical machine learning models to deep learning. We were also looking for a machine learning platform to help us scale and version control all our models .
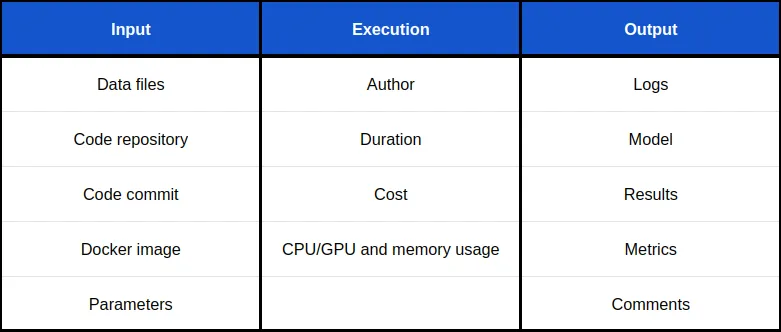
Airflow does a good job keeping track of each task details in the metadata database, but machine learning tasks have different requirements from ETL tasks. A machine learning task is associated with the data, code, environment, parameters and metrics . That information is not collected and displayed by Airflow. And Kubernetes only helps you with the infrastructure.
Collecting all relevant information for each execution in one place helps debugging machine learning models. In the following table, you can see the information we track to iterate on machine learning models faster.
Our choice for scaling machine learning tasks
You can already find several Airflow operators for machine learning platforms like Google DataFlow, Amazon SageMaker and Databricks. The issue with those operators is that they all have different specifications and are limited to executing code in those platforms.
Before we started doing any machine learning at Skillup.co, we used Airflow for all data engineering that consisted mostly of Python CLIs called by the Airflow BashOperator .
Then we decided to use Valohai, a machine learning platform built on open standards, to help us launch machine learning tasks remotely and get automatic version control.
Having a hybrid solution allowed us to keep sensitive data in our Airflow installation and delegate machine learning to Valohai.
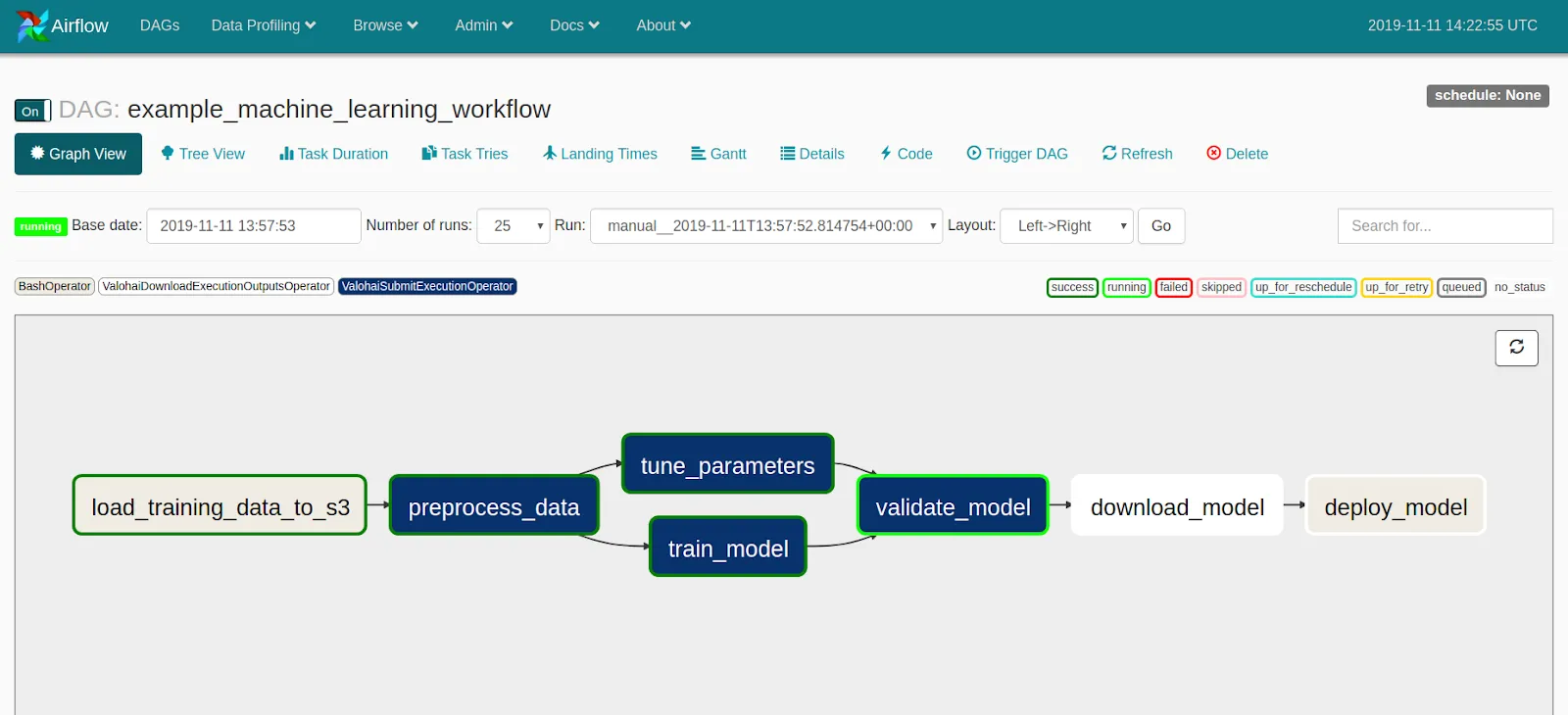
Machine learning workflow with an Airflow DAG. Blue tasks are executed remotely thanks to Valohai.
Thanks to Valohai’s open API, we developed the open-source airflow-valohai-plugin to integrate the two platforms. In the last year, we have used it to release four machine learning models in production.
Valohai Operator
The idea behind the Valohai operator is similar to the Kubernetes operator. The advantage is that you don’t need to understand Kubernetes and you also get automatic version control for machine learning.
Valohai will take care of launching and stopping cloud instances with your requirements, code and data. The Valohai operator simply executes a command in a Docker container, polls for its completion and returns the final status code.
You can execute code in any language and library by providing a Docker image and your code repository. You also get access to more than fifty cloud environments in AWS, Google and Azure.
To create a task on Airflow you only need to specify the Valohai project and step to execute. You can also override the default cloud environment, inputs and parameters if needed.
View code on GitHubSample code to submit an execution to Valohai from Airflow [ source ]
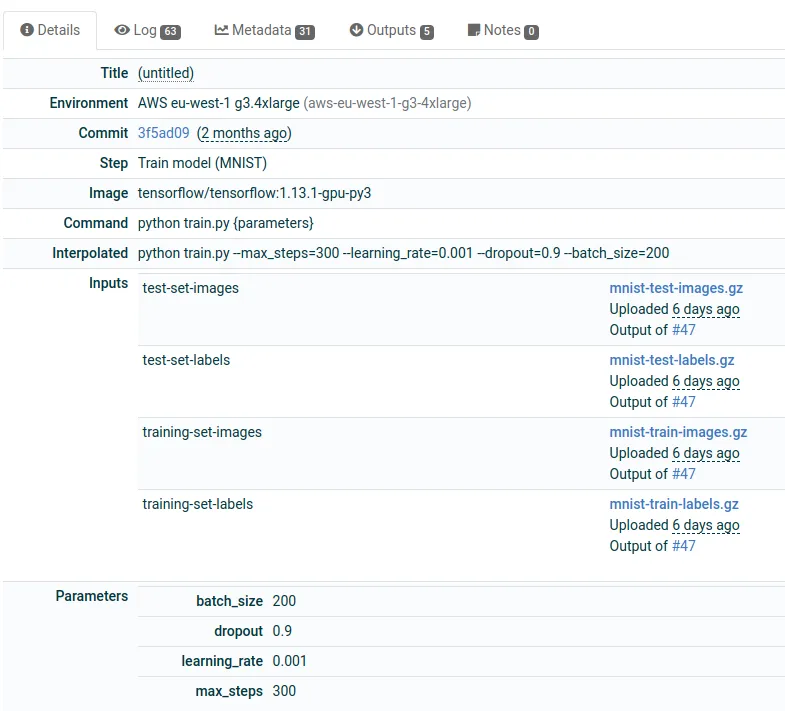
On the other hand, you need some light configuration on the Valohai side by creating a valohai.yaml. The valohai.yaml serves as a configuration file to set the defaults and validates the machine environment, docker image, command to run, parameters and input data files for each execution.
Having machine version control from the beginning helped us to debug the data, code and parameters that lead to a prediction and fix it faster. The same way that you want your Airflow tasks to be idempotent to avoid side effects when relaunching them, you want your machine learning models to be based on an audited version of the code and data. That’s easy to do if you always train your models on files stored on your data lake. Below you can see the parsed configuration in the Valohai UI for an execution.
Valohai is built on top of two smart choices that make it easy to integrate with any programming language and library.
First, choosing a CLI-first interface universal to all programming languages. CLIs are a popular interface to wrap your functions to execute them locally. CLIs are also the interface for the Bash, Kubernetes and Valohai operators.
Second, collecting execution metrics from standard output instead of having to install a custom library for each language. All languages have a tool to write a JSON object to standard output. Valohai will automatically parse that object and for example, help you compare the accuracy of each model.
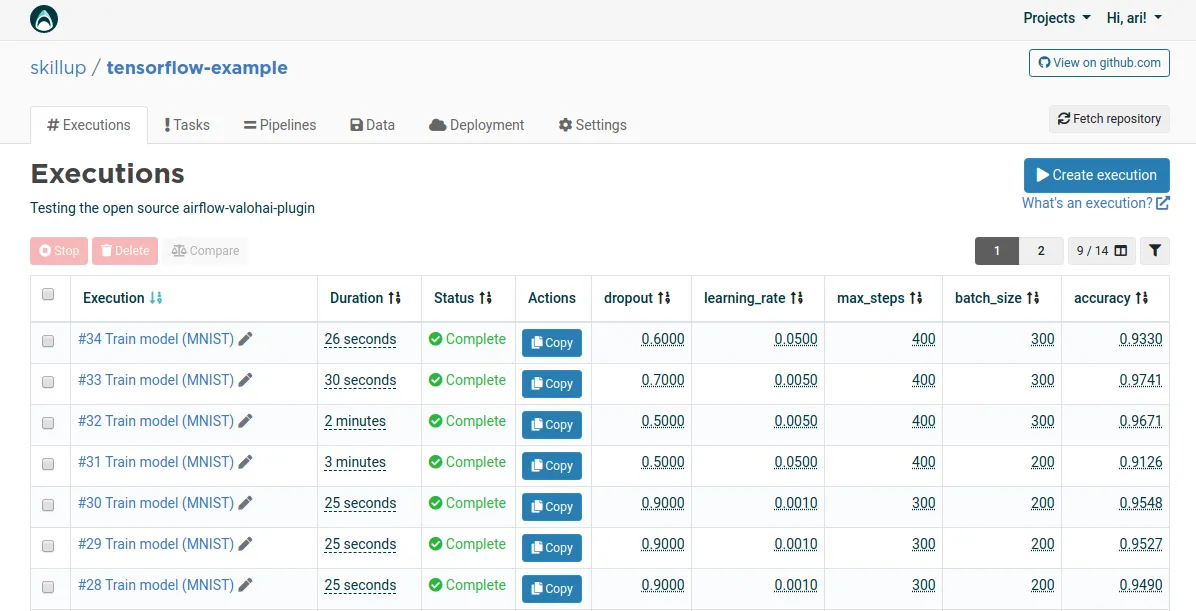
You can also manually launch executions without any side effects in the Valohai UI. In Airflow, clearing the state of a task will trigger the downstream tasks.
Last but not least, the new Valohai operator lets you easily pass the outputs from one execution as the inputs of the next one. This helped us create pipelines where the data is automatically versioned on S3. Also, each new execution is run on the same cloud provider and region as the S3 bucket making it fast for Valohai to download it on the AWS EC2 instance.
Conclusion
Apache Airflow is a powerful tool to create, schedule and monitor workflows but it was built for ETL tasks. Machine learning tasks require specific resources and their execution details should be version controlled.
If you have the resources to maintain a Kubernetes cluster you can scale machine learning tasks with the KubernetesPodOperator .
If you want to focus on building models, you can scale Airflow for machine learning tasks with the ValohaiSubmitExecutionOperator . This way, you will also get automatic version control for each execution.
