What is CI/CD for Machine Learning?
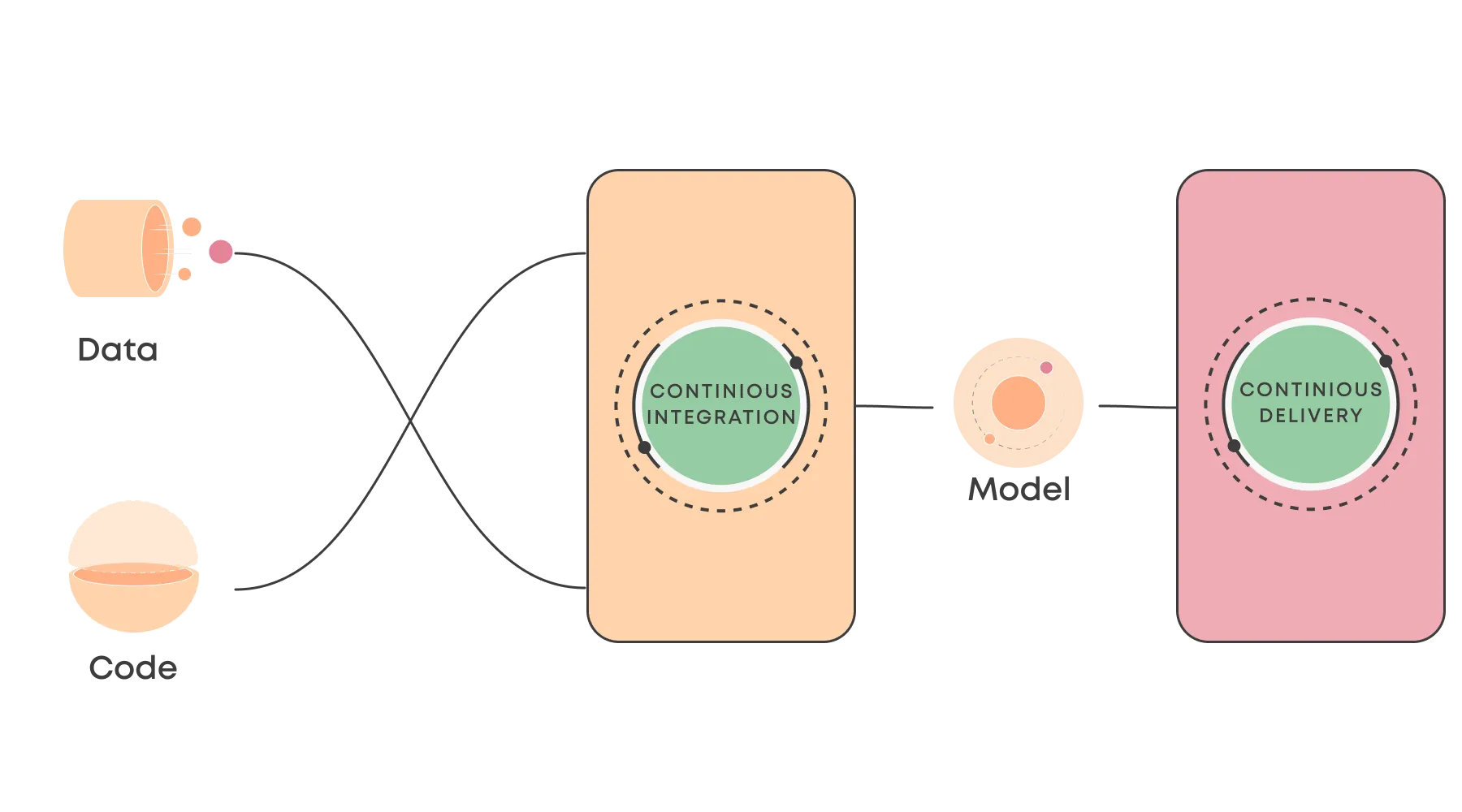
Continuous Integration and Continuous Delivery are becoming more popular for machine learning as ML algorithms are integrated into existing software products.
The aim of a CI/CD pipeline is the same in machine learning as it is in software development, to make it more efficient and safer to release new versions. In this article, we've collected a few common patterns of CI/CD for machine learning.
What is MLOps?
MLOps (machine learning operations), sometimes also written as ML Ops, is a practice that aims to make developing and maintaining production machine learning seamless and efficient. While MLOps is relatively nascent, the data science community generally agrees that it's an umbrella term for best practices and guiding principles around machine learning – not a single technical solution.
What are Continuous Integration and Continuous Delivery (CI/CD)?
Continuous Integration and Continuous Delivery are modern software development concepts that revolve around automating the release of software and accelerating release cycles. Continuous Integration refers to automating the building and testing of the application, including unit and integration tests, while Continuous Delivery refers to packaging and deploying the application to staging or production environments.
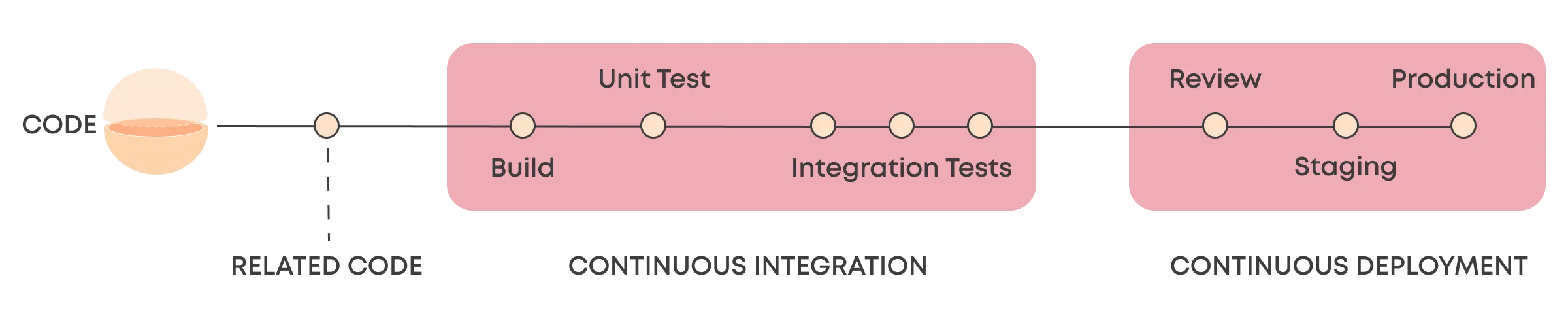
CI/CD has been a crucial concept for software teams in shortening the time to market with new features and updates, and it's unlikely that you'll see any developer teams today without at least some level of automation for integration and delivery. There are plenty of articles online that go deeper into the CI/CD terminology like this one from Harness.
These terms are becoming increasingly relevant for data scientists who are building machine learning models for production use.
How is CI/CD for Machine Learning Different?
The crucial difference between machine learning and traditional software is that in ML it's not just the code that dictates the end product. Instead, as we've explored in our article on DevOps vs. MLOps, it's a combination of code and data. Thus, comparing the CI/CD of an ML system starts with two things that can trigger it: either a new code version or a new dataset.
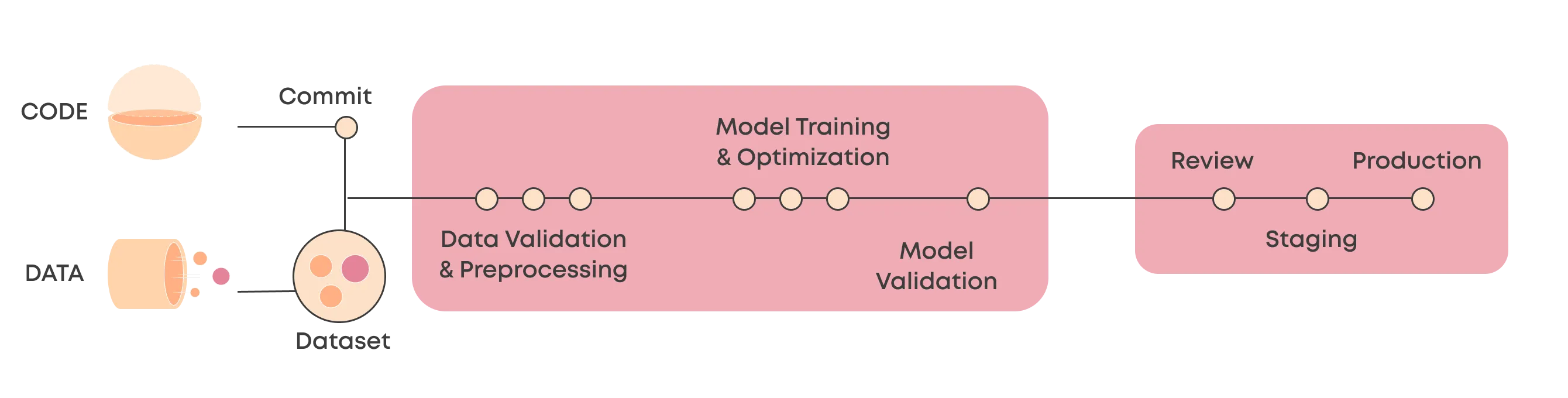
What in software development is called a CI pipeline, in ML would perhaps be more appropriately be called a Continuous Training pipeline or an ML pipeline. This pipeline fetches the latest code and data, runs any preprocessing and testing steps for the data, trains and runs any hyperparameter optimization, and validates the model performance against test data.
If you plan on serving your model as an API endpoint that outputs predictions, your CD process will look quite similar to other web applications. However, there are quite a few ways you can serve a machine learning model to the end-user, and thus the delivery side of CI/CD may also vary.
A few the critical differences between CI/CD pipeline in ML and CI/CD pipeline in software development are:
- Data is a critical part of the whole CI/CD pipeline, and you'll likely want to include steps that preprocess, test, and monitor your data.
- Model training and hyperparameter optimization take much longer than most applications take to build, and training will likely require specific hardware such as GPUs.
- Model validation is key in automating but may be quite difficult to do. Testing software is often quite binary (pass/fail), but model performance is much more a scale.
- Software doesn't degrade over time as models do. It's possible that a machine learning CI/CD needs to run rather frequently based on data changes (even when none is actively working on the project). This puts extra emphasis on robust automation.
Connecting Machine Learning CI/CD with Application CI/CD
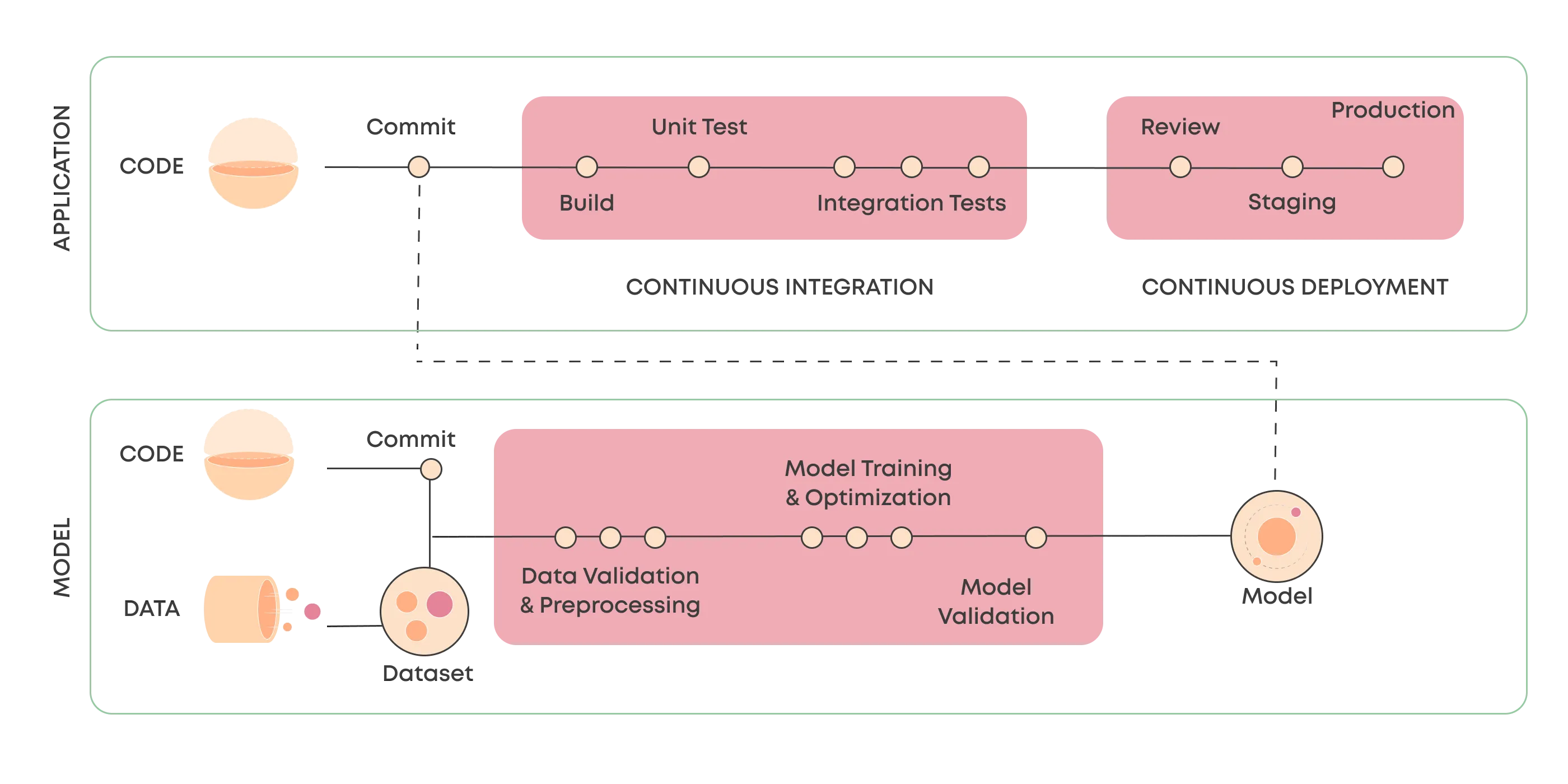
There isn't an established pattern for CI/CD in machine learning because a model can be served in many different ways. For example, batch, online, and edge inference all add their own flavors.
We often see a pattern, especially in IoT and other edge use cases, where the machine learning CI/CD connects to the application CI/CD. As a result, newly trained models get pulled into the main CI/CD pipeline (similarly to other dependencies) when it's being run. In these cases, a model library functions as the point of integration.
In Valohai, we've built a specific tagging system that makes it easy to pull the latest model for each project through the API and use that in other external systems (such as a CI/CD pipeline).
How to Build a CI/CD for Machine Learning with Valohai?
A simple way to build a CI/CD workflow is to trigger a Valohai pipeline with GitHub Actions. Valohai is built API-first so that you can trigger anything from single executions to multi-step pipelines. In the example below, we'll look at just starting a single Valohai execution (for example, model training) when a commit is made in the master branch.
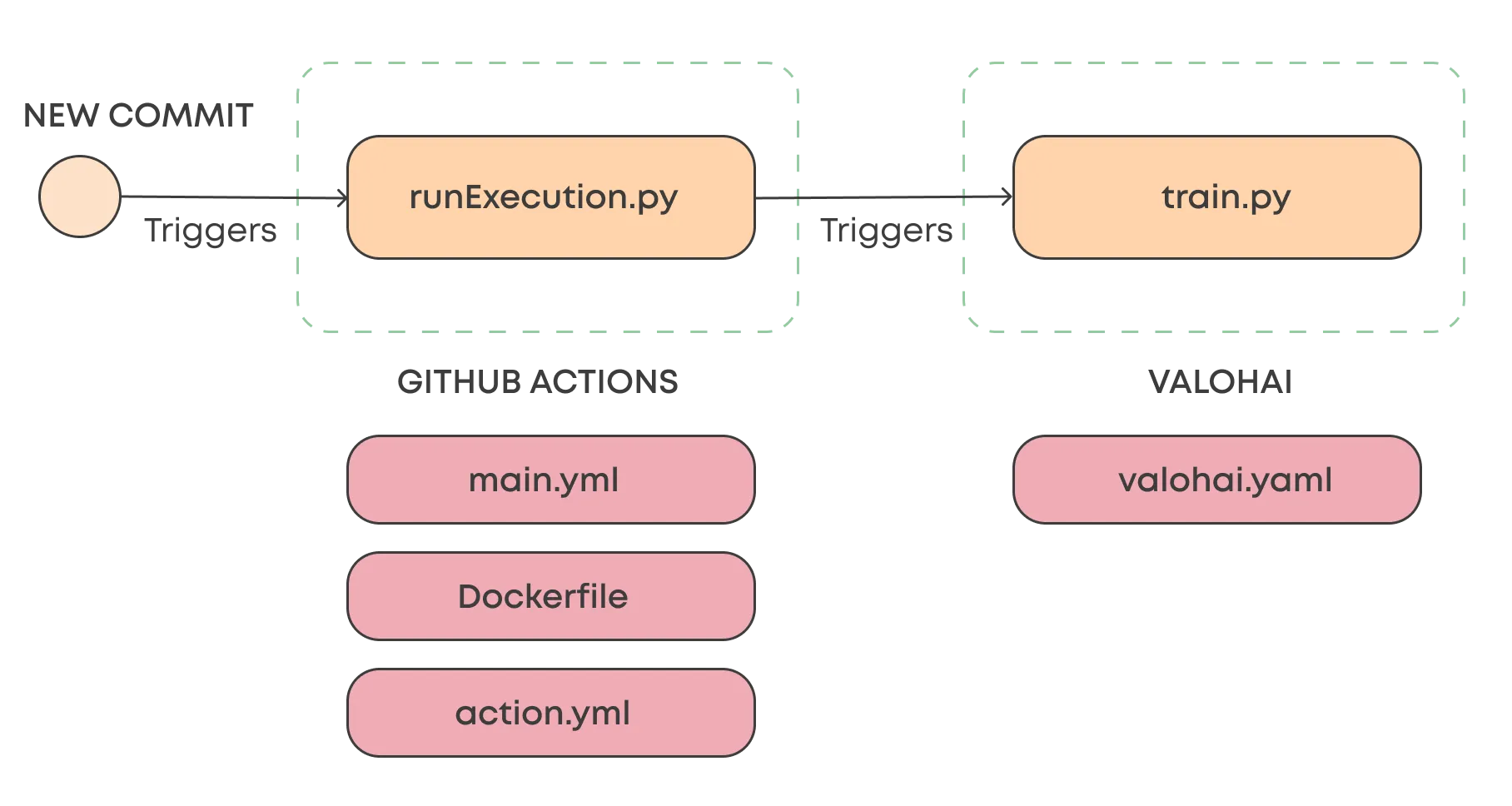
This setup consists of two Python scripts, one on the GitHub Actions side and one on the Valohai side. The runExecution.py script sends an API call to Valohai, which runs the train.py, the actual ML code.
In addition to these scripts, both platforms require some configuration files.
 A simple Valohai project with the GitHub Actions scripts and configs
A simple Valohai project with the GitHub Actions scripts and configs
Learn more about CI/CD for Machine Learning & Deep Learning
The best of the best

MLOps in the Wild
A collection of MLOps case studiesSkimmable. Inspirational.
The MLOps space is still in its infancy and how solutions are applied varies case by case. We felt that we could help by providing examples of how companies are working with tooling to propel their machine learning capabilities.
Think of this as a lookbook for machine learning systems. You might find something that clicks and opens up exciting new avenues to organize your work – or even build entirely new types of products.
Download