
Valohai MLOps platform provided the infrastructure for the Black-Box Optimization Challenge for the NeurIPS 2020 conference. The competition was organized together with Twitter, Facebook, SigOpt, ChaLearn, and 4paradigm.
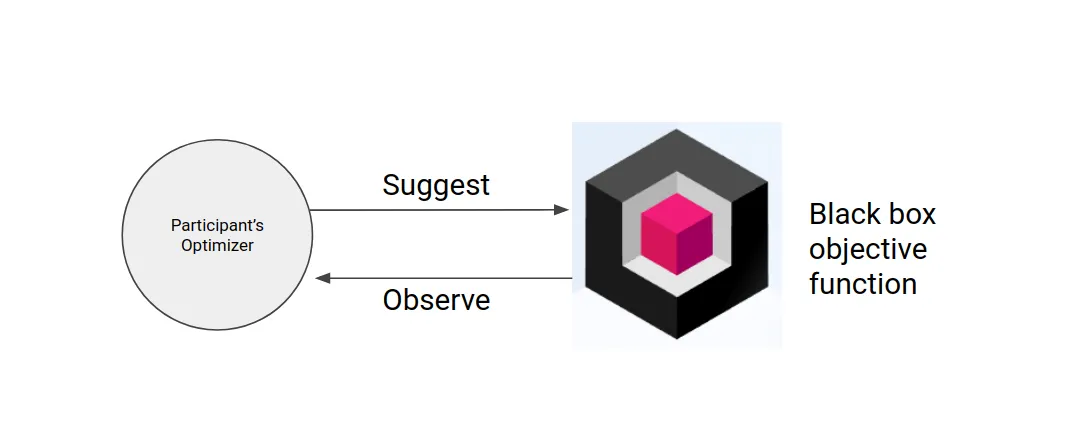
The competition was about creating an optimizer that optimizes a function inside a black box. The optimizer uses a very simple suggest/observe API that hides all the details inside the box. The black box could contain anything, but the competition’s title suggested that it would probably have at least some ML-related optimization problems.
The organizers’ role was to find a way to score all the optimizers uploaded by the participants and score them in a highly scalable way. For the scoring, we utilized an open-source library called Bayesmark running inside isolated Docker containers. For the scalable MLOps infrastructure around the containers, we used the Valohai MLOps platform and its powerful rest API.
The project had three distinct phases: Pre-production, production, and post-production – each with its unique MLOps needs.
Pre-production
We needed to test the scoring method, estimate the computational resources required, and calculate the baselines for the normalized scoring.
Bayesmark
Bayesmark is a framework for benchmarking Bayesian optimization methods on machine learning models and datasets. It takes an optimizer and scores it by training real ML models repeatedly. It measures how well the optimizer performs during these repeated runs and outputs a final score that can be compared against all the other optimizers.
Estimating workload
The initial plan was to use the Bayesmark framework with real models and real datasets. The math was as follows: Our original palette was nine models and 24 datasets. This sums up to 9 x 24 = 216 permutations per submission. On top of that, it is not enough to study a single permutation once. To get real results, one needs to run several studies (we chose 10), and each study consists of multiple iterations (we chose 128). We estimated ~30 teams, each making around ~10 submissions on average.
The total estimated number of training runs:
30 teams x 30 submissions x 216 permutations x 10 studies x 128 iterations = 248832000
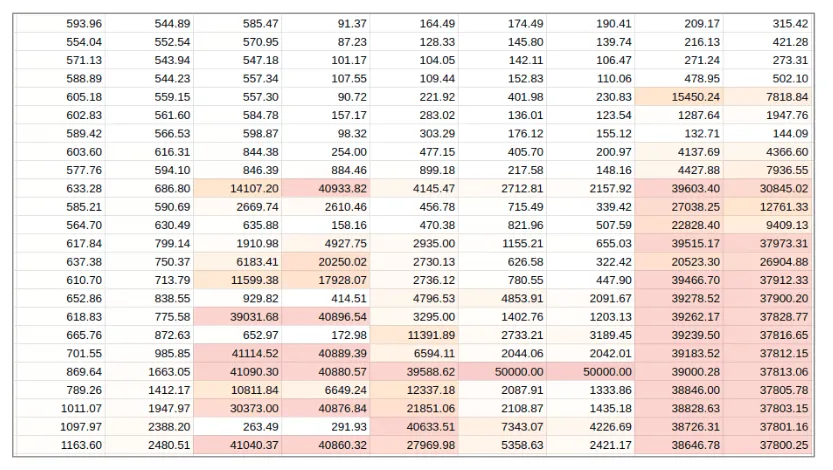
That is a whopping 248 million models to be trained. We really needed to optimize everything and figure out which datasets to crop down. Luckily it is straightforward to measure it using the Valohai grid search. Here is a table of how the computation was distributed between different datasets and models (the names are hidden to protect future competitions):
Calculating baselines
We wanted to get normalized scores out of the Bayesmark, which meant that we needed to provide the baselines. This means defining what the “best possible optimizer” and the “worst possible optimizer” is.
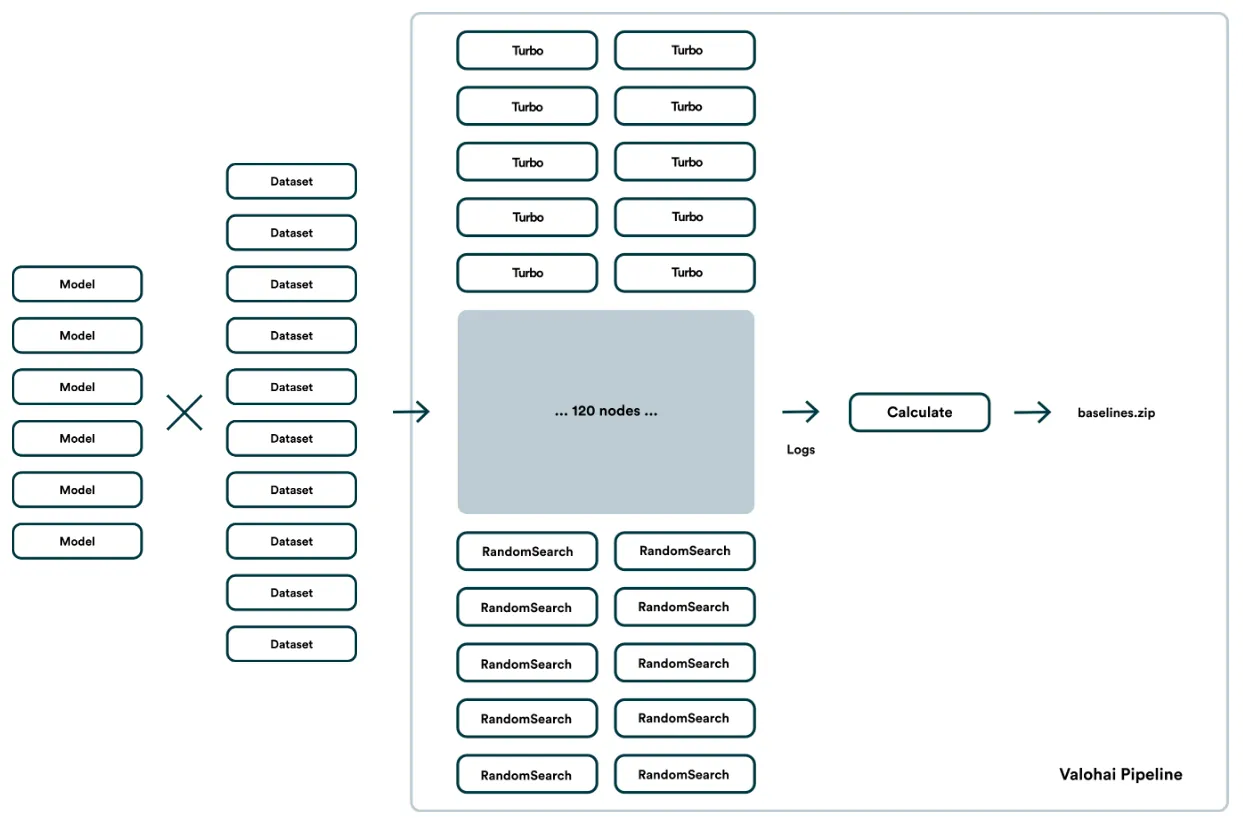
The “worst possible optimizer” is easy: Just run a random search a few times. The “best possible optimizer” is trickier: Run the best optimizer you can find (we used Turbo) and let it run for a REALLY long time.
The baseline is required for each model-dataset pair, which in our case eventually meant 60 different baselines to calculate. This was a time-consuming ordeal and called for a reusable Valohai pipeline of 60+60+1 nodes, so we could easily change parameters, trim down datasets and restart the run easily.
Production
From an infrastructure point of view, the competition needed two parts.
- The frontend for uploading submissions and watching them get scored in real-time into a shared leaderboard.
- The backend to run the benchmarking executions for the submissions
Frontend
The competition website

The Valohai dev team created a proprietary Django/React website to serve the participating teams and organizers.
Whenever any of the teams uploaded a new optimizer, the website backend would trigger a new batch of benchmarking executions using the Valohai API. The website backend would then frequently poll back the API for the queue status and intermediate scores. The teams could manually stop their scoring process midway. The backend would also auto-stop the entire batch if one of the runs encountered a fatal error (to free the resources).
Backend
Valohai MLOps platform, with its powerful API, acted as the competition backend.
During the competition, we used half of our available black boxes (30) and saved another half for the final validation. To run the 5 x 6 problems in parallel, we used the Valohai grid search functionality. Instead of running the entire thing in a single machine (~24 hours), we spread it into 30 parallel machines. This way, each submission was scored in less than an hour.
Valohai has an automated scaling system, which means we never had a machine sitting idle doing nothing. When the queue started to get longer, the scaling system would automatically bring up more instances to catch on. We did, however, set an upper limit for the maximum machine count just to be safe. At the peak of the competition, there were 300 cloud instances constantly crunching the scores.
Competition architecture
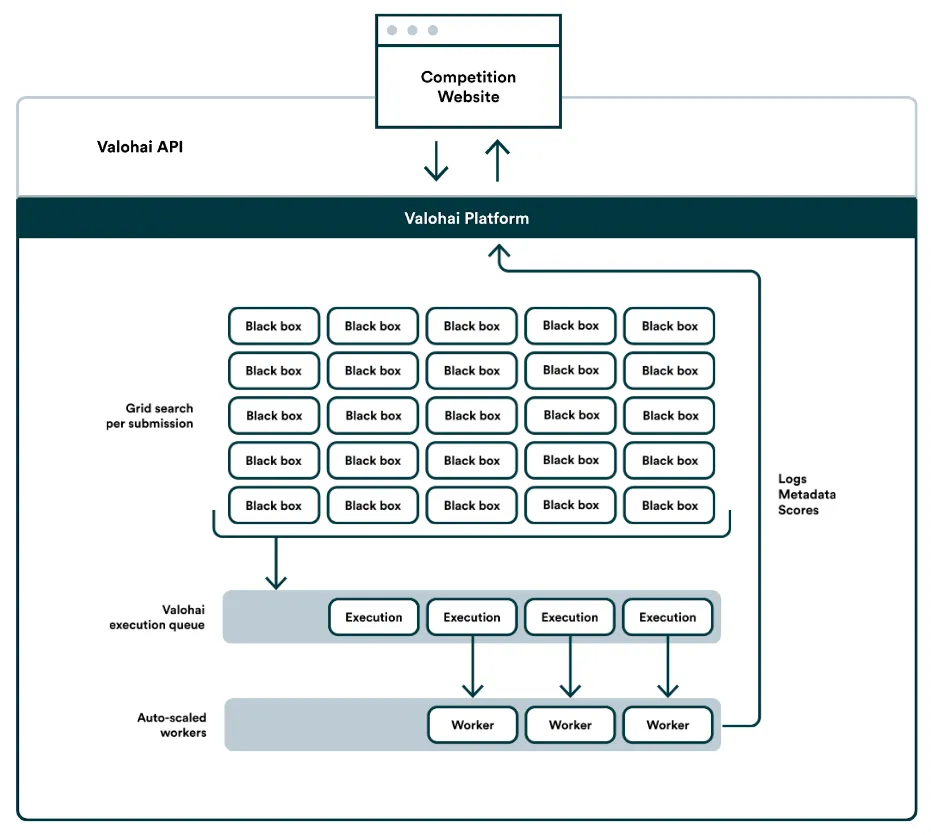
The Valohai platform version-controls everything it does. Not only did we see all the runs and their logs in real-time and after the fact, but they could also reproduce any execution later on to debug issues faced by the competitors. Technically, we could have streamed all the logs and exceptions back to the competitors too, but we felt like this would compromise the competition’s black-box nature and open a massive backdoor for exploits.
Valohai grid search tasks listed. Each row is a single submission.
Logs of a single benchmarking execution.
The numbers
Before the competition, we estimated 30 teams would join, making 30 submissions each. This estimation was too conservative. During the active competition phase, the numbers were:
-
70 teams uploaded a working optimizer
-
Total of 3608 scored submissions, 51 per team on average
-
Total of 108240 executions on Valohai platform
-
10.36 years of total compute time used
-
277 million model training runs
Post-production
Once the submission uploading was closed, it was time to calculate the final scores. We used half of the black boxes during the competition phase and saved another set for the final validation.
In the competition phase, we would run ten Bayesmark studies per dataset/model. For the final scores, the organizers decided to bump that to 100 studies. It would ensure that the final leaderboard was based on actual performance, and most of the luck would average out.
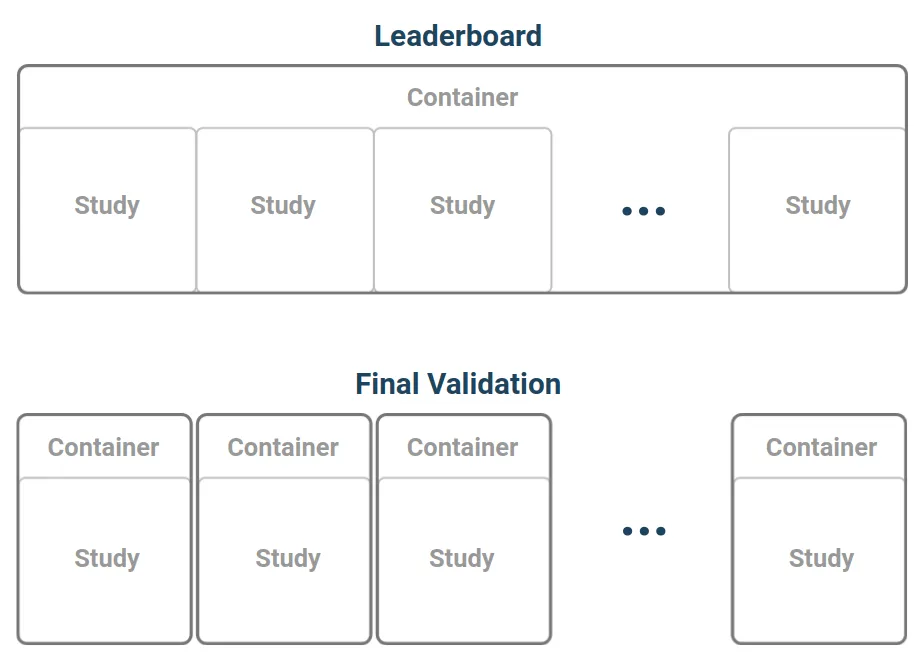
Another difference for the post-production scoring was the need to run each study in an isolated environment. We saved some overhead during the competition by running all the studies in the same docker container without clearing and restarting in-between. This approach was open to exploitation as the optimizer could pass some information from one study to another using the hard disk or some other means. We wanted to close this exploit for the final scores and ran tests with the isolated containers for the top 20 teams.
Final Words
The competition was a great success. We had more than double the participants and more than double the uploads per team than what was estimated. The scoring pipeline worked non-stop for four months and had only one short downtime, caused by an unexpected change in our cloud provider quota limits and not really the actual infrastructure.
The final leaderboard(s), talks, and papers are live on the competition website if you are interested in diving into the deep end.
For more information on the Valohai MLOps Platform, visit our product tour or better yet, book a demo.