Today’s machine learning teams consist of people with different skill sets. There are a bunch of different roles that are needed, but today I am going to talk about the two key roles that I get asked about the most: machine learning researcher / data scientist vs. machine learning engineer.
Do we need both?
There is a big difference between the style of work and background of these roles and that is also the reason why the leading technology companies have decided to have separate teams to focus on machine learning algorithms and machine learning engineering.
I am going to describe the common problems, workloads and focuses these roles have and what kinds of differences in talent you might expect to see between these two.
Machine learning researcher / data scientist
Machine learning researchers or data scientists are people who work with data and build machine learning models. They clean and interpret data and build models using a combination of machine learning algorithms and data.
Data Scientist (n.): Person who is better at statistics than any software engineer and better at software engineering than any statistician. Check out this comprehensive guide on hiring data scientists.
Credit for the definition goes Josh Wills (@josh_wills).
Modern Machine Learning Researchers come often from the academic field and their background is usually in university research projects. This research is now being applied to real world use cases with lightning speed due to breakthroughs in research, accumulation of data and easy access to computational resources like GPUs.
It might be surprising how big of a technological gap there is between research and real world production systems. In theoretical or research settings, repeatability, record keeping, testing and collaboration play a much smaller role compared to production systems where teams of 10 or more researchers might work on the same data and models to optimize, for instance, the conversion rate of a recommendation engine.
Simply put, university researchers often work alone or in small teams. Researchers have a fixed dataset that they train a model on and once satisfied with the results, they write a paper and often never go back to the code ever again or actually deploy the model at scale for real world use cases.
Real world applications are fundamentally different in a few major aspects.
- Teams are larger
- People leave for other companies
- New people come in
- The world changes, data evolves and models go stale
- Models go into production and therefore must be tested and monitored
- The main driver is long term ROI instead of just getting the research result
These requirements present a host of issues that require a lot of software infrastructure support. This is mainly DevOps work that involves building data pipelines, automated testing, autoscaling computational clusters and ensuring high availability for serving models. This all is something most researchers have never done before. This has lead to the emergence of a new type of role often called the machine learning engineer.
Machine learning engineer
Machine learning engineers are the support troops of researchers and data scientists. Machine learning engineers rarely touch the models or are interested in the form or contents of the data they work with. Their major concern is making data scientists’ life as easy as possible.
Machine learning engineers do anything from data lake set up and management to building easy to use computational clusters for training and finally ensuring high availability deployment of models.
Machine learning engineers come from software development and DevOps backgrounds and have started to specialize in ML infrastructure. These people are familiar with containers, container orchestration – tools like Docker and Kubernetes –, running clusters in various compute clouds or on-premise and building robust deployment pipelines.
Focus on your core
We see a lot of teams where data scientists don’t get enough engineering support and spend a lot of time on things that are well out of their area of expertise, just to get things running. This slows down progress and iteration speed.
Below is an image from Google research team’s study that illustrates complexity and scope of the surrounding machine learning infrastructure in real-world ML systems.
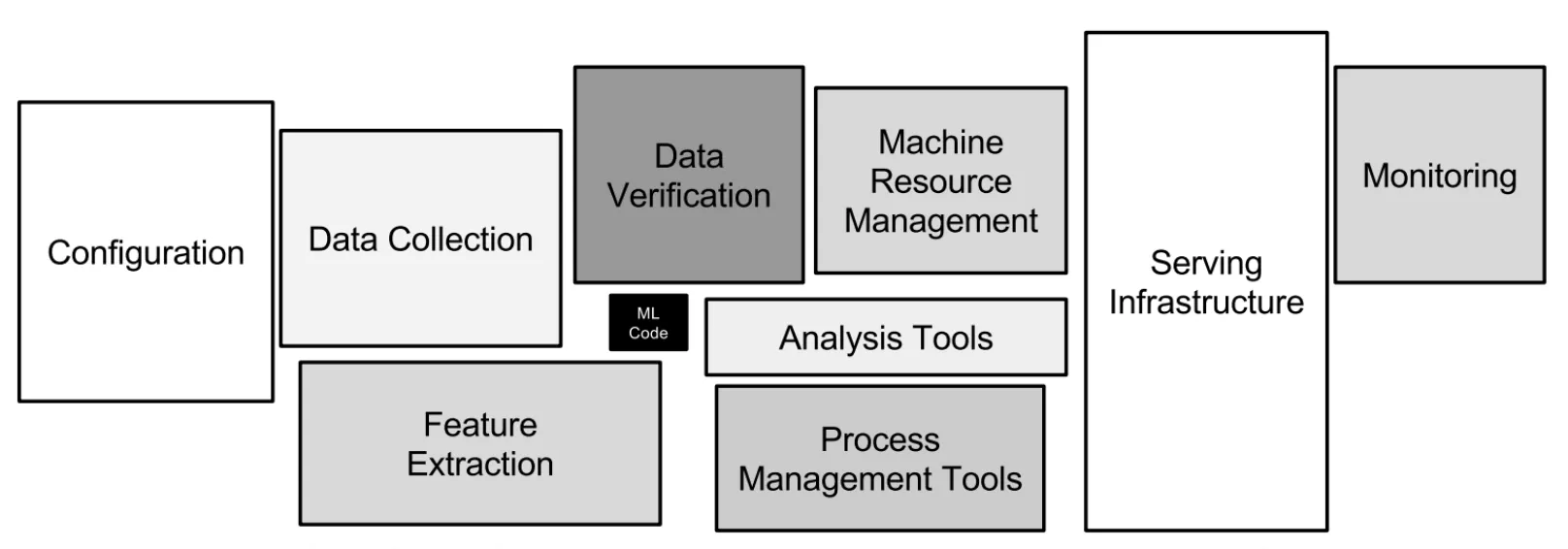
Source: Hidden Technical Debt in Machine Learning Systems
Machine learning in production is very complicated – in many ways even more complicated than normal web scale systems – and you should treat the engineering side with respect, choose the right tools to support the team and staff enough to move faster.
In addition, you should not expect data scientists to build the engineering side of your machine learning stack. The data and machine learning modelling are vast and complicated areas of expertise and require a lot of study on their own.
If you want the most out of your machine learning team, make sure these two areas work seamlessly together and staff both sides equally.