Introduction
We are all aware of Machine Learning tools and cloud services that work via the browser and give us an interface we can use to perform our day-to-day data analysis, model training, and evaluation, and other tasks to various degrees of efficiencies.
But what would you do if you want to do these tasks on or from your local machine or infrastructure available in your organisation. And, if these resources available do not meet the pre-requisites to do decent end-to-end Data Science or Machine Learning tasks. That’s when access to a cloud-provider agnostic deep learning management environments like Valohai can help. And to add to this, we will be using the free-tier that is accessible to one and all.
We will be performing the task of building a Java app, and then training and evaluating an NLP model using it, and we will do all of it from the command-line interface with less interaction with the available web interface — basically it will be an end-to-end process all the way to training, saving and evaluation of the NLP model. And we won’t need to worry much about setting up any environments, configuring or managing it.
Purpose or Goals
We will learn to do a bunch of things in this post covering various levels of abstractions (in no particular order):
- how to build and run a NLP model on the local machine?
- much less examples on NLP, mostly on classification or regression or computer vision (image, video, etc…)
- how to build and run a NLP model on the cloud?
- how to build NLP Java apps that run on the CPU or GPU?
- most examples out there are non-Java based, much less Java-based ones
- most examples are CPU based, much less on GPUs
- how to perform the above depending on absence/presence of resources i.e. GPU?
- how to build a CUDA docker container for Java?
- how to do all the above all from the command-line?
- via individual commands
- via shell scripts
What do we need and how?
Here’s what we need to be able to get started:
- a Java app that builds and runs on any operating system
- takes advantage of the GPU if available, otherwise uses the available CPU
- CLI tools that allow connecting to remote cloud services
- shell scripts and code configuration to manage all of the above
The how part of this task is not hard once we have our goals and requirements clear, we will expand on this in the following sections.
NLP for Java, DL4J and Valohai
NLP for Java: DL4J
We have all of the code and instructions needed to get started with this post, captured for you on GitHub. Below are the steps you go through to get acquainted with the project:
Quick startup
To quickly get started we need to do just these:
- open an account on app.valohai.com
- install Valohai CLI on your local machine
- clone the repo https://github.com/valohai/dl4j-nlp-cuda-example/
- create a Valohai project using the Valohai CLI tool, and give it a name
- link your Valohai project with the github repo
https://github.com/valohai/dl4j-nlp-cuda-example/on the Repository tab of the Settings page (https://app.valohai.com/p/\[your-user-id\]/dl4j-nlp-cuda-example/settings/repository/) - update Valohai project with the latest commits from the git repo
Now you’re ready to start using the power of performing Machine Learning tasks from the command-line.
See Advanced installation and setup section in the README to find out what we need to install and configure on your system to run the app and experiments on your local machine or inside a Docker container — this is not necessary for the purpose of this post at the moment but you can try it out at a later time.
About valohai.yaml
You will have noticed we have a valohai.yaml in the git repo and our valohai.yaml file contains a number of steps that you can use, we have enlisted them by their names, which we will use when running our steps:
- build-cpu-gpu-uberjar: build our uberjar (both CPU and GPU versions) on Valohai
- train-cpu-linux: run the NLP training using the CPU-version of uberjar on Valohai
- train-gpu-linux: run the NLP training using the GPU-version of uberjar on Valohai
- evaluate-model-linux: evaluate the trained NLP model from one of the above train-* execution steps
- know-your-gpus: run on any instance to gather GPU/Nvidia related details on that instance, we run the same script with the other steps above (both the build and run steps)
Building the Java app from command line
Assuming you are all setup we will start by building the Java app on the Valohai platform from the command-prompt, which is as simple as running one of the two commands:
And you will be prompted with the execution counter, which is nothing by a number:

Note: use --adhoc only if you have not setup your Valohai project with a git repo or have unsaved commits and want to experiment before being sure of the configuration.
You can watch your execution by:
and you can see either we are waiting for an instance to be allocated or console messages move past the screen when the execution has kicked off. You can see the same via the web interface as well.
Note: instances are available based on how popular they are and also how much quota you have left on them, if they have been used recently they are more likely to be available next.
Once the step is completed, you can see it results in a few artifacts, called outputs in the Valohai terminology, we can see them by:

We will need the urls that look like datum://[….some sha like notation…] for our next steps. You can see we have a log file that has captured the gpu related information about the running instance, you can download this file by:
Running the NLP training process for CPU/GPU from the command-line
We will use the built artifacts namely the uberjars for the CPU and GPU backends to run our training process:
We can watch the process if we like but it can be lengthy so we can switch to another task.
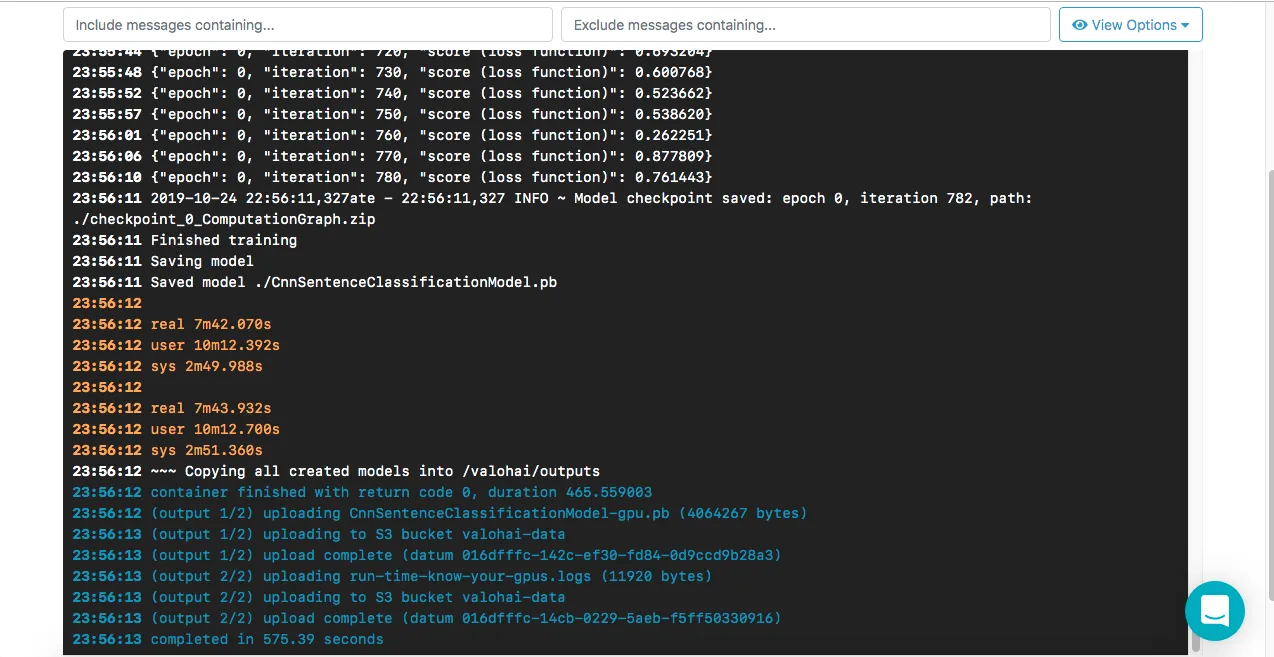
The above execution runs finish with saving the model into the ${VH_OUTPUTS} folder to enable it to be archived by Valohai . The model names get suffix to their names, to keep a track of how they were produced.
At any point during our building, training or evaluation steps, we can stop an ongoing execution (queued or running) by just doing this:
Downloading the saved model post successful training
We can query the outputs of an execution by its counter number and download it using:

See how you can evaluate the downloaded model on your local machine , both the models created by the CPU and GPU based processes (respective uberjars). Just pass in the name of the downloaded model as a parameter to the runner shell script provided.
Evaluating the saved NLP model from a previous training execution
And at the end of the model evaluation we get the below, model evaluation metrics and confusion matrix after running a test set on the model:
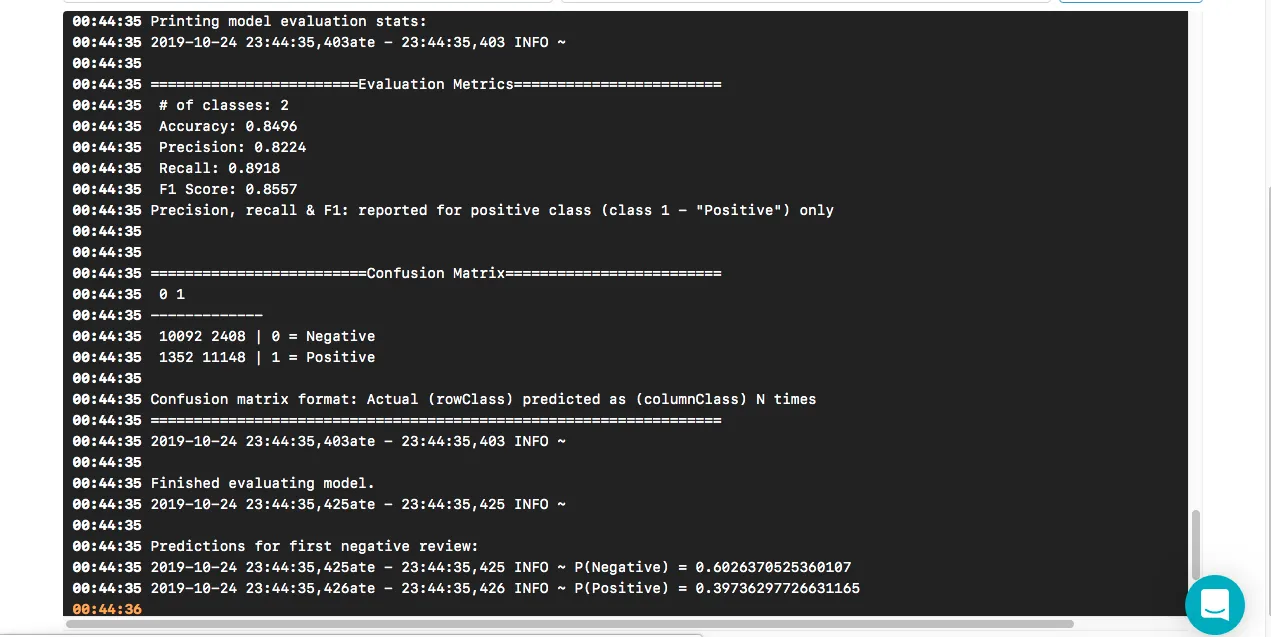
Note: the source code contains ML and NLP-related explanations at various stages in the form of inline comments.
Capturing the environment information about Nvidia’s GPU and CUDA drivers
This step is unrelated to the whole process of building and running a Java app on the cloud and controlling and viewing it remotely using the client tool, although it is useful to be able to know on what kind of system we ran our training on, especially for the GPU aspect of the training:
Keeping track of your experiments
- While writing this post, I ran a number of experiments and to keep track of the successful versus failed experiments in an efficient manner, I was able to use Valohai ’s version control facilities baked into its design by
- filtering for executions
- searching for specific execution by “token”
- re-running the successful and failed executions
- confirming that the executions were successful and a failure for the right reasons
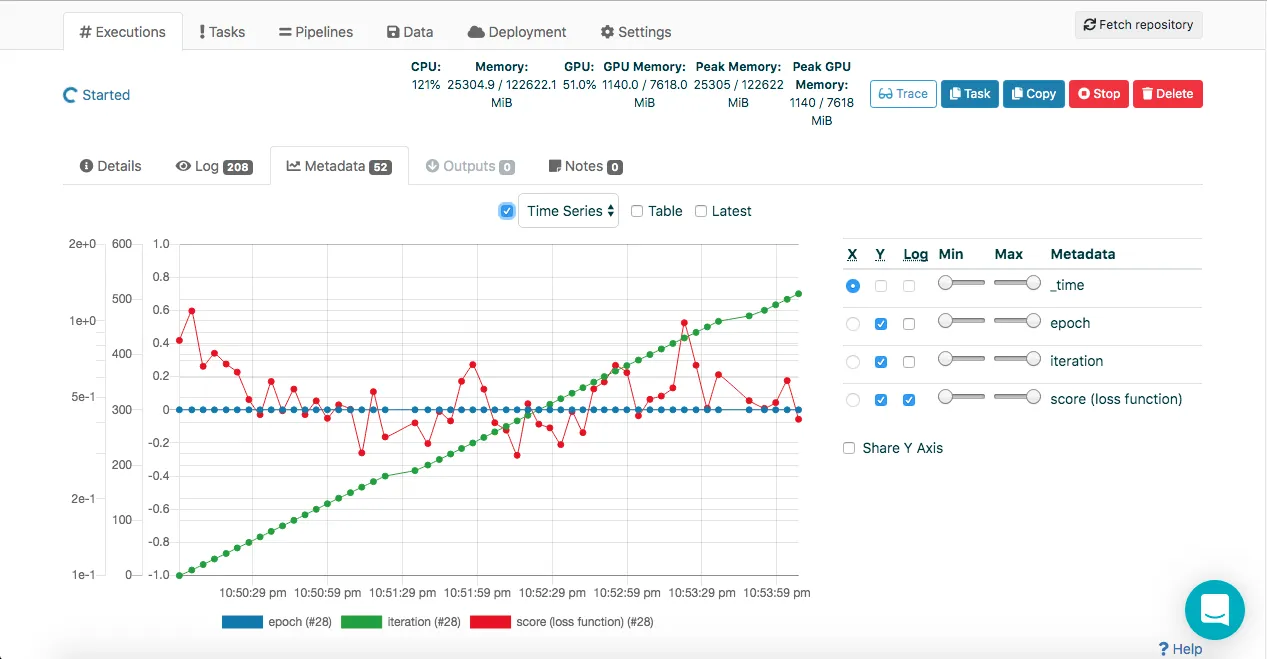
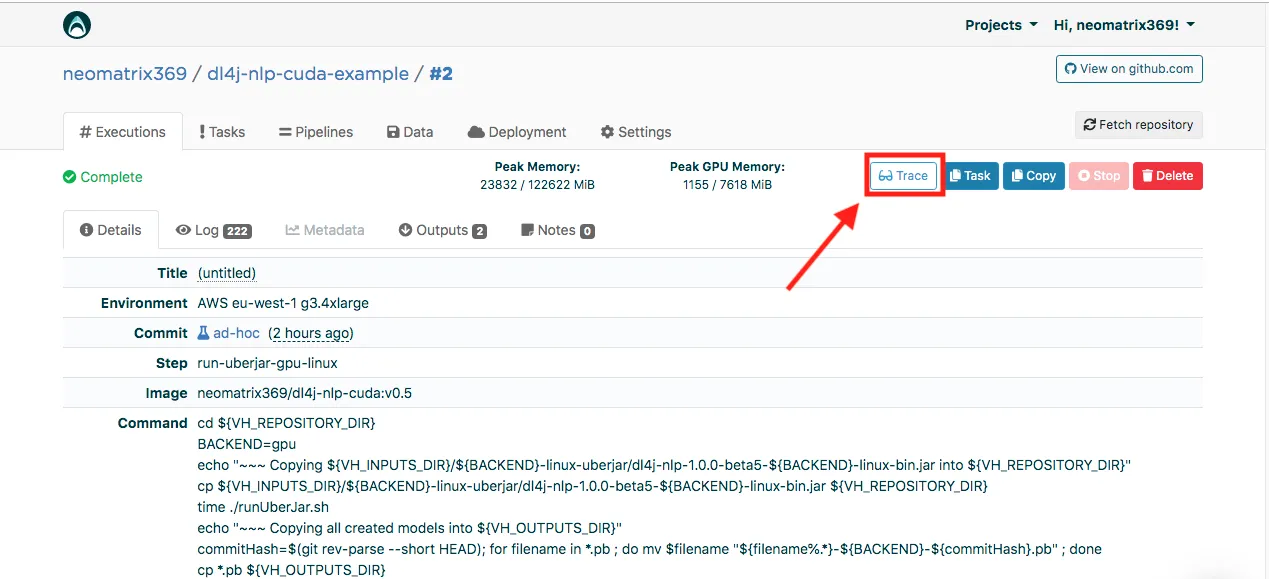
- also, checkout data-catalogs and data provenance on the Valohai platform, below is an example of my project (look for the Trace button):
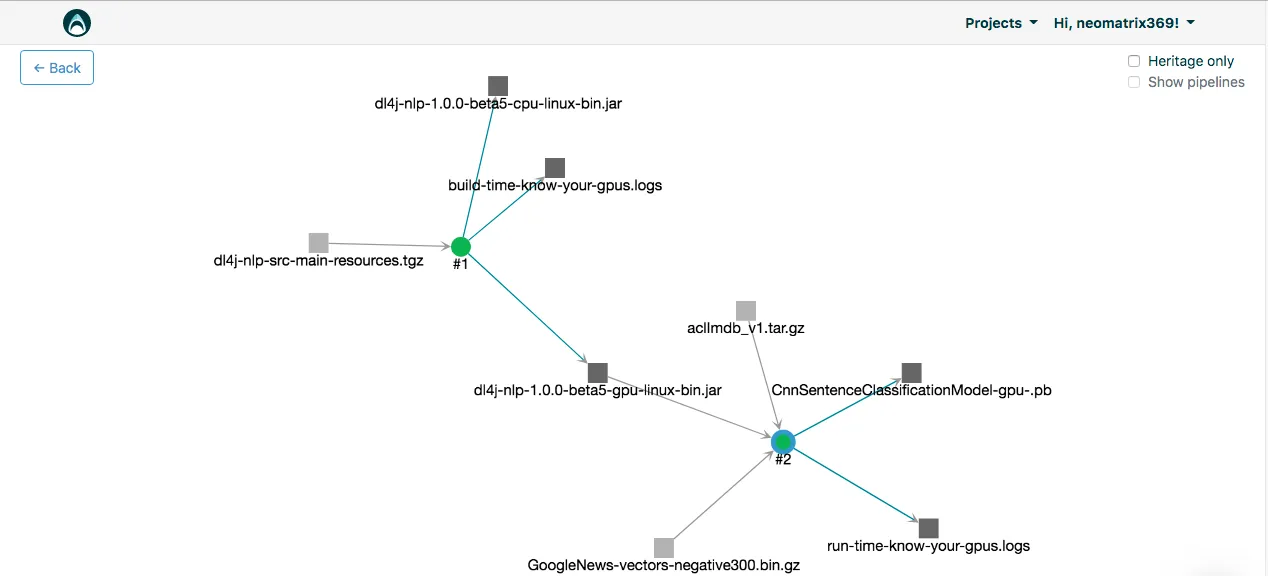
Comparing the CPU and GPU based processes
We could have discussed about comparisons between the CPU and GPU based processes in terms of these:
- app building performance
- model training speed
- model evaluation accuracy
But we won’t cover these topics in this post, although you have access to the metrics you need for it, in case you wish to investigate further.
Necessary configuration file(s) and shells scripts
All the necessary scripts can be found on the github repo , they can be found in:
- root folder of project
- docker folder
- resources-archive folder
Please also have a look at the README.md file for further details on their usages and other additional information that we haven’t mentioned in this post here.
Valohai - Orchestration
If we have noticed all the above tasks actually was orchestrating the tasks via a few tools at different levels of abstractions:
- docker to manage infrastructure and platform-level configuration and version control management
- java to be able to run our apps on any platform of choice
- shell scripts to be able to again run both building and execution commands in a platform agnostic manner and also be able to make exceptions for absence of resources i.e. GPU on MacOSX
- a client tool to connect with the remote cloud service i.e. Valohai CLI , and view, control executions and download the end-results
You are basically orchestrating your tasks from a single point making use of the tools and technologies available to do various Data and Machine Learning tasks.
Conclusion
We have seen that NLP is a resource consuming task and having the right methods and tools in hands certainly helps. Once again the DeepLearning4J library from Skymind and the Valohai platform have come to our service. Thanks to the creators of both platform. In addition we can see the below benefits (and more) this post highlights.
Benefits
We gain a bunch of things by doing the way we did the things above:
- not have to worry about hardware and/or software configuration and version control management — docker containers FTW
- able to run manual one-off building, training and evaluation tasks — Valohai CLI tool FTW
- automate regularly use tasks for your team to be able to run tasks on remote cloud infrastructure — infrastructure-as-code FTW
- overcome the limitations of an old or slow machine or a Mac with no access to the onboard GPU — CUDA-enabled docker image scripts FTW
- overcome situations when not enough resources are available on the local or server infrastructure, and still be able to run experiments requiring high-throughput and performant environments — a cloud-provider agnostic platform i.e Valohai environments FTW
- run tasks and not have to wait for them to finish and be able to run multiple tasks — concurrently and in-parallel on remote resources in a cost-effective manner — a cloud-provider agnostic platform i.e Valohai CLI tool FTW
- remotely view, control both configuration and executions and even download the end-results after a successful execution — a cloud-provider agnostic platform i.e Valohai CLI tool FTW
- and many others you will spot yourself
Suggestions
- using provided CUDA-enabled docker container: highly recommend not to start installing Nvidia drivers or CUDA or cuDNN on your local machine (Linux or Windows based) — shelve this for later experimentation
- use provided shell scripts and configuration files: try not to perform manual CLI command instead use shells scripts to automate repeated tasks, provided examples are a good starting point and take it further from there
- try to learn as much : about GPUs, CUDA, cuDNN from resources provided and look for more (see Resources section at the bottom of the post)
- use version control and infrastructure-as-code systems: git and the valohai.yaml are great examples of this
I felt very productive and my time and resources were effectively used while doing all of the above, and above all I can share it with others and everyone can just reuse all of this work directly - just clone the repo and off you go .
What we didn’t cover and is potentially a great topic to talk about, is the Valohai Pipelines in some future post!
Resources
-
dl4j-nlp-cuda-example project on GitHub
-
CUDA enable docker container on Docker Hub (use the latest tag: v0.5 )
-
GPU, Nvidia, CUDA and cuDNN
- See the Resources section on the github repo , under GPU, Nvidia, CUDA and cuDNN
-
- Java AI/ML/DL resources
- Deep Learning and DL4J Resources
- Awesome AI/ML/DL: NLP resources
- DL4J NLP resources
- Examples
- Java AI/ML/DL resources
-
Valohai resources
- valohai | docs | blogs | GitHub | Videos | Showcase | About valohai | Slack | @valohaiai
- Search for any topic in the Documentation
- Blog posts on how to use the Valohai CLI tool: [1] | [2]
- Custom Docker Images
-
Other related posts
- How to do Deep Learning for Java on the Valohai Platform?
- Blog posts on how to use the Valohai CLI tool: [1] | [2]
About me
Mani Sarkar is a passionate developer mainly in the Java/JVM space, currently strengthening teams and helping them accelerate when working with small teams and startups, as a freelance software engineer/data/ml engineer.
A Java Champion, software crafter, JCP Member, OpenJDK contributor, thought leader in the LJC and other developer communities and involved with @adoptopenjdk , @graalvm and other F/OSS projects. Writes code, not just on the Java/JVM platform but in other programming languages, hence likes to call himself a polyglot developer. He sees himself working in the areas of core Java, JVM, JDK, Hotspot, Graal, GraalVM, Truffle, VMs, Performance Tuning, Data and Machine Learning technologies.
Since sometime I have developed a strong interest in the areas of AI, Machine Learning, Data, Data Analytics (using R), Data Visualisation (using R & D3), Concurrency (Java), and Graal/GraalVM/Truffle and continue to develop my skills and understanding in the areas of Application and JVM Performance Tuning and Benchmarking.
An advocate of a number of agile and software craftsmanship practices and a regular at many talks, conferences (Devoxx, VoxxedDays) and hands-on-workshops – speaks, participates, organises and helps out at many of them. Expresses his thoughts often via blog posts (on his own blog site, DZone, Medium and other third-party sites), and microblogs (tweets).
Twitter: @theNeomatrix369 | GitHub: @neomatrix369