In the age of technology, conventional methods are being automated, and computers are taking over. Similarly, for energy distribution, smart grids are replacing traditional energy distribution grids which allow efficient distribution and demand-side management.
Why Load Forecasting?
With an increase in population and an overall expansion of the energy infrastructure, electricity demand is increasing rapidly. To manage this increasing demand efficiently, so-called smart grids are used. The cardinal feature of demand-side management in smart grids is load forecasting, as it allows the operators of the smart grid to make efficient and effective decisions, which is the topic of interest of this blog post.
There are three different categories of load forecasting, namely short-term load forecasting (STLF, ranging from a few hours to a few days), medium-term load forecasting (MTLF, several days up to a few months), and long-term load forecasting (LTLF, greater than or equal to one year). This study focuses on STLF which is a particularly challenging problem because decisions need to be made within a very short span of time and there is less room for error.
Previous research in a paper published by Hung Nguyen in an IEEE conference in 2017 used Autoregressive Moving Average (ARMA) and Seasonal Autoregressive Integrated Moving Average (SARIMA) for load forecasting. This study to analyze ARMA and SARIMA provided a mean absolute percentage error (MAPE) of 9.13% and 4.36% respectively. The LSTM models introduced in this study bring this MAPE metric down to 1.975%!
Solution: Machine Learning
Load forecasting is a complex multi-variable and multi-dimensional estimation problem where forecasting methods such as curve fitting using numerical methods do not provide accurate results as they fail to track the seemingly random trends accurately, which is something machine learning algorithms are better at.
The first step towards developing a machine learning model for load forecasting is to understand the various parameters on which electricity demand is dependent. It depends on several different parameters such as time of the day, previous electricity demand trends, weather, humidity, electricity price, etc. However, for the sake of simplicity, we will be using past energy trends, correlated weather data and a timestamp for our predictions. Two different datasets are used to test these models. The first one is provided by Réseau de transport d’électricité (RTE) France while the second one is from the Electrical Reliability Council of Texas (ERCOT). The datasets provided in the GitHub repository have various other parameters as well (e.g., electricity price), some of which would have a significant effect on load forecasting. You may try to train the algorithm on those parameters as well and see how your result varies. Make sure you train the algorithms on Valohai and avoid burning your own processing power and RAM.
Our results using the ERCOT dataset will be compared with previous research on ARMA and SARIMA to see how well our models work when stacked against existing research.
LSTM models such as the ones we’ll be using here are critical to load forecasting. Adding too many layers and hidden nodes can quickly lead to an overtrained system which performs exceptionally well on training data but fails as soon as it enters a real-world scenario. Too simple a system and you would end up with below average forecasting for both training and test data.
We performed extensive tests for model selection. These tests were performed on the RTE dataset with 70,080 samples used for training and 17,567 samples used for testing. The first step to be carried out, before actually initiating our experiment, is to load the data into Python and split it into train and test datasets. You can see in the code below:
View code on GitHubThe second step is to set up a model. This model would change with each step. You can see a simple model with 50 hidden layers and no return sequence in the code below:
View code on GitHubWe pass training data and some additional parameters such as batch size, epoch value, etc. to this model. When setting the batch size, take note that larger batch sizes could mean better training results, at the expense of more computing resources consumed. You can see the code used to train our model below:
View code on GitHubOnce our model has been trained, we can start making predictions with it to test its accuracy. We will be making predictions and then compare them with our test data set. In this step we will be calculating two measures to test our accuracy, the mean absolute percentage error (MAPE) and root mean square error (RMSE). We use the following code to achieve this:
View code on GitHubThe steps highlighted above provide you with sufficient information to test your models, but seeing is believing. Just to verify the numbers on the screen, we will plot the graph of our models against actual values and analyze it visually. You can use the following code to plot these graphs:
View code on GitHubOur Models
Two different LSTM models are used in this study. These models were selected after thoroughly testing out several different LSTM models with a different number of layers, regularisers, and hidden nodes. You can see the two chosen models which provided the most optimal results below.
Our complex LSTM architecture uses two LSTM layers with a drop out regularizer after each LSTM layer. The first LSTM layer has 128 hidden nodes while the second LSTM layer has 64 hidden nodes. The second layer is densely connected to the next layer which in turn goes through a rectified linear unit (ReLU) activation function. You can see this model in detail below:
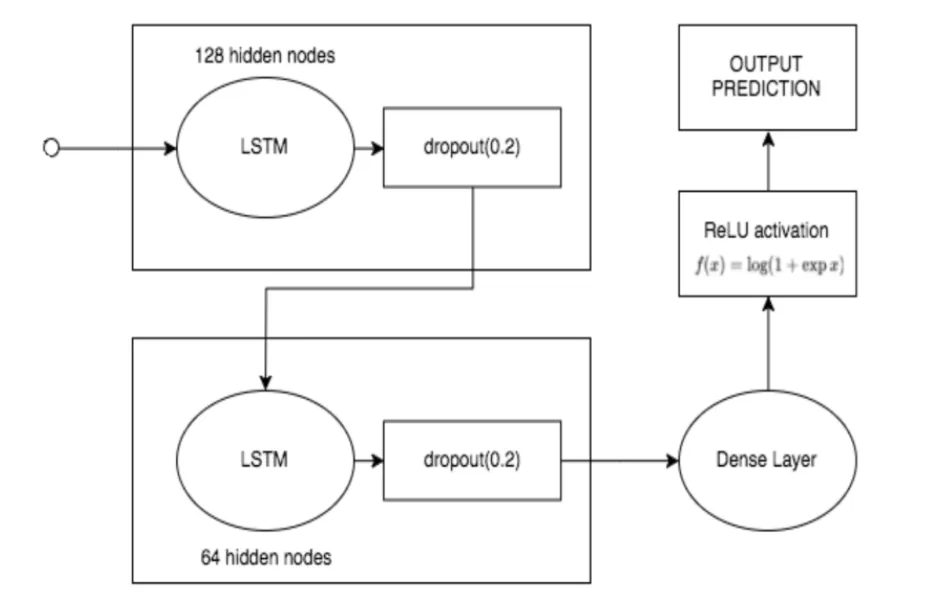
Complex LSTM
Our simple LSTM architecture uses a single LSTM layer with 50 hidden nodes followed by a ReLU activation function for electrical load forecasting. This model can be seen in detail below:
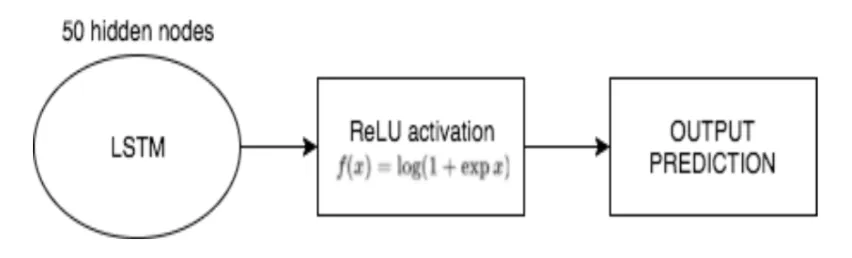
Simple LSTM
Prediction at a particular timestamp is strongly dependent upon electricity consumption on previous timestamps. Hence, energy consumption at five previous timestamps is also incorporated while making predictions.
The first model uses two LSTM layers and aims to track more complex patterns in electricity demand while the second model is a simple single layer LSTM model. The first model is expected to outperform the second model however it would take significantly more time to train and utilizes more resources. We will test both models to see if the difference between a complex network and a simple model is negligible or not.
Results
RTE Dataset
| Model # | MAPE | RMSE |
| Simple LSTM | 5.304 | 660.653 |
| Complex LSTM | 5.256 | 658.651 |
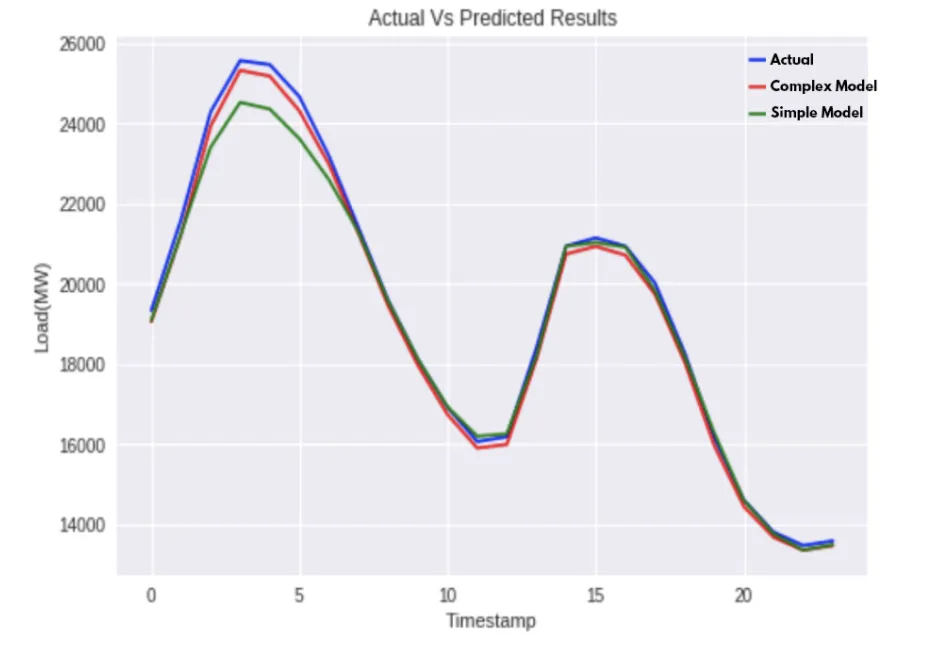
ERCOT Dataset
| Model # | MAPE | RMSE |
| ARMA | 9.13 | 3451 |
| SARIMA | 4.36 | 1638 |
| Simple LSTM | 2.638 | 716.534 |
| Complex LSTM | 1.664 | 229.630 |
Conclusion
After viewing the results, we can see that LSTMs provide significantly improved results compared to the ARMA and SARIMA models. We can also see that our “simple model”, which is more straightforward and less compute intensive to train, provides results close to the more complex model and can be used where resources are limited.
These models can take significant resources on your computer to train and take a long time to setup the environment. Valohai relieves you from this burden as you can directly import our GitHub repository into your project and execute everything on the cloud. Cheers!
Setting Up Load Forecasting on Valohai
We have prepared a GitHub repository for you to reproduce these experiments on Valohai. To set it up on Valohai, follow the simple steps explained below! After logging in to your Valohai account, look at the top right corner of your screen. You will see a drop-down with the name “Projects.” Upon clicking it, you will get an object to create a new project. Select that option, and you are ready to create your first Valohai project.
We are going to name this project “load-forecasting” but feel free to rename it whatever you want.
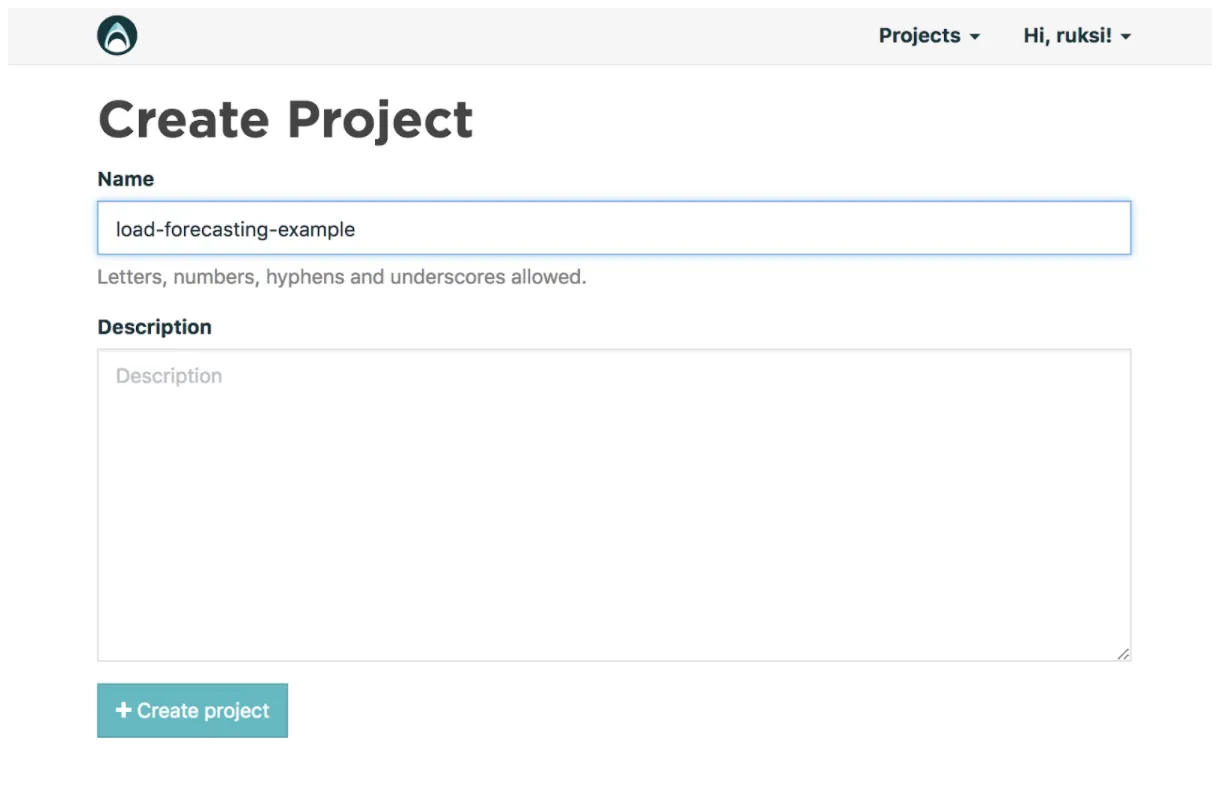
Once you are done, click on the “Create project” button.
Now, the next step is to link our GitHub repository to the project that you just created: https://github.com/valohai/load-forecasting
Head over to “Settings” and within settings, open the repository tab as seen in the screenshot below:
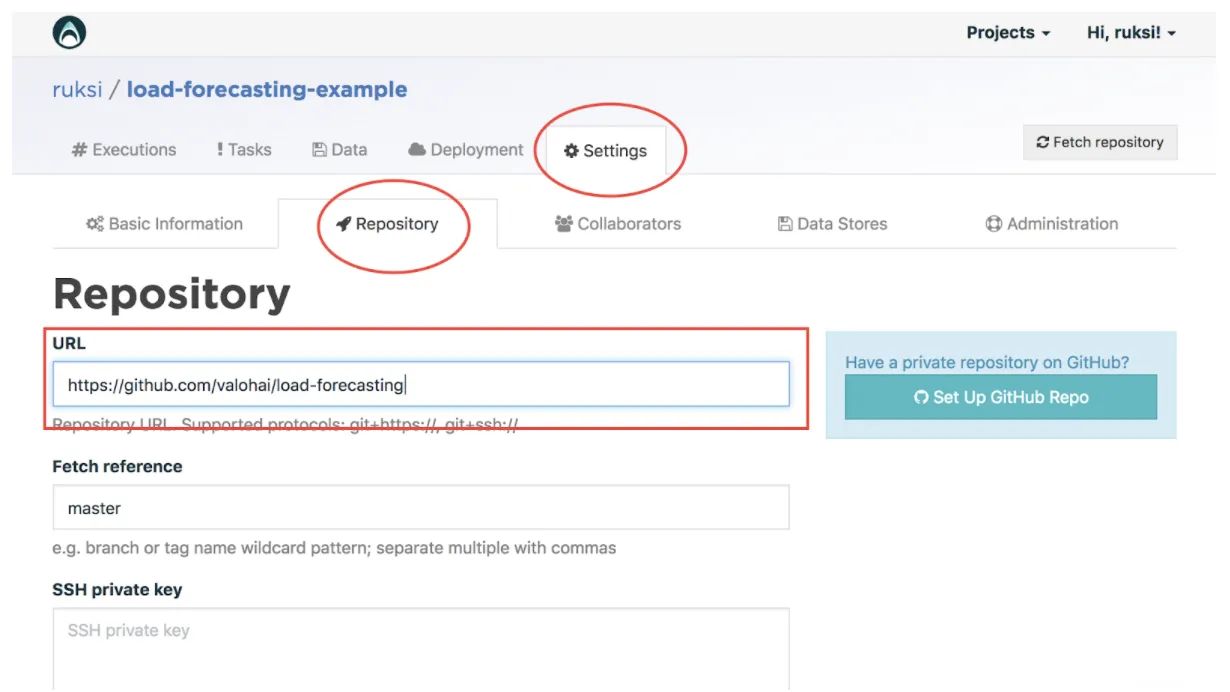
Enter the URL https://github.com/valohai/load-forecasting and as it is a public repository, no authentication information is required, click save.
Valohai will automatically fetch this repository from GitHub. However, if you face any issues, you can do it manually by clicking the “fetch repository” button in the top right.
Once your repository has been set up, you can create an execution. Click on the “Create execution” button shown below.
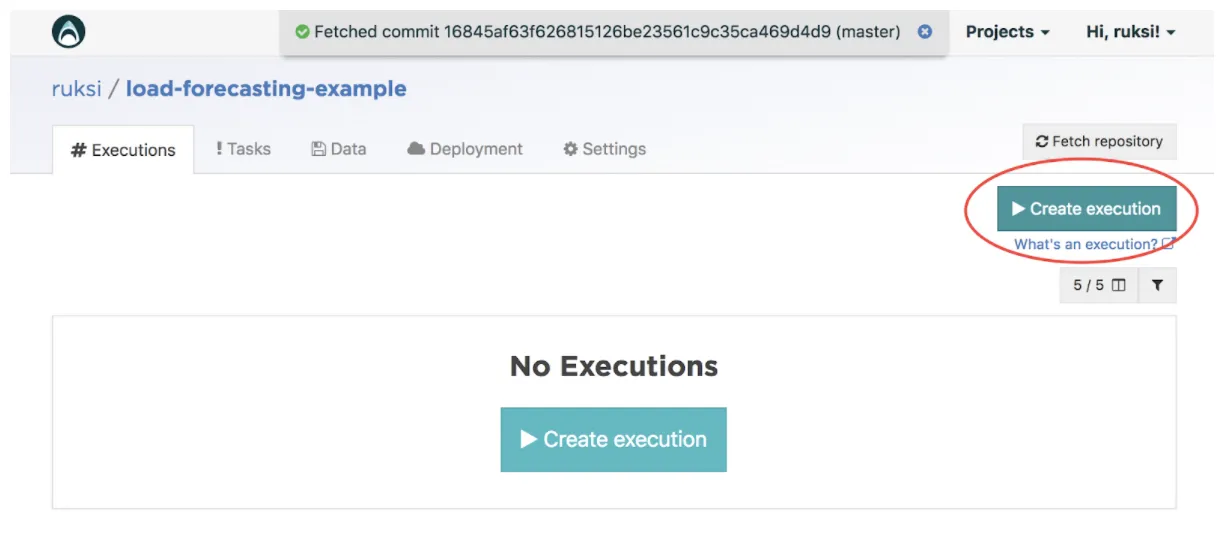
We will start with creating an execution for training our first model. Default settings are fine, but feel free to customize anything and click on “Create execution.”
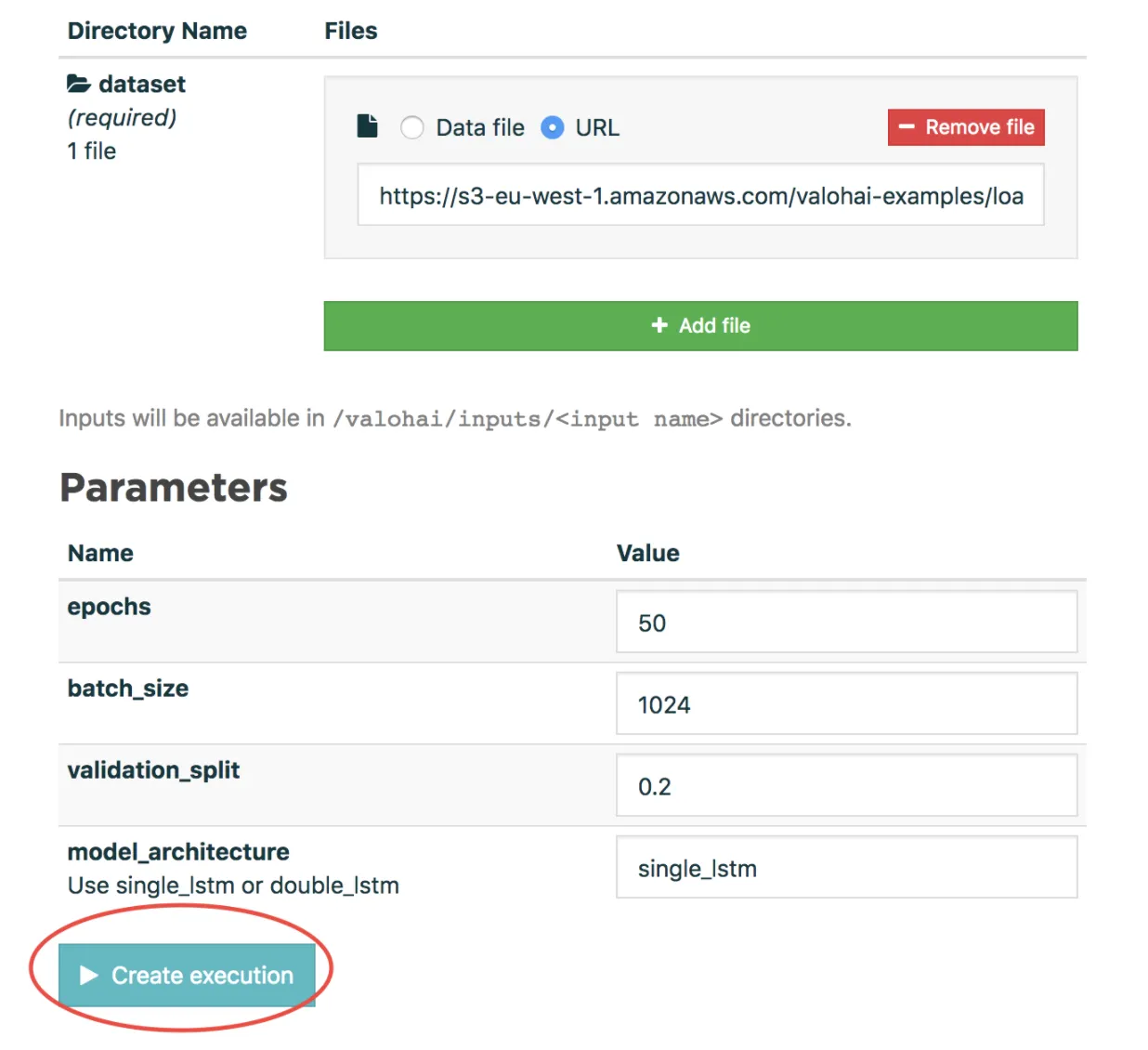
The model will use the RTE dataset by default, you can change this by editing input called “dataset” to https://s3-eu-west-1.amazonaws.com/valohai-examples/load-forecasting/ercot-dataset.csv on the web UI. Give it a minute or two to run. Once our training is complete and our model has been saved to disk, we can start with creating an execution for executing the model that we trained in the first step. To ensure that the training process was successful, check that your logs seem about the same as the screenshot below:
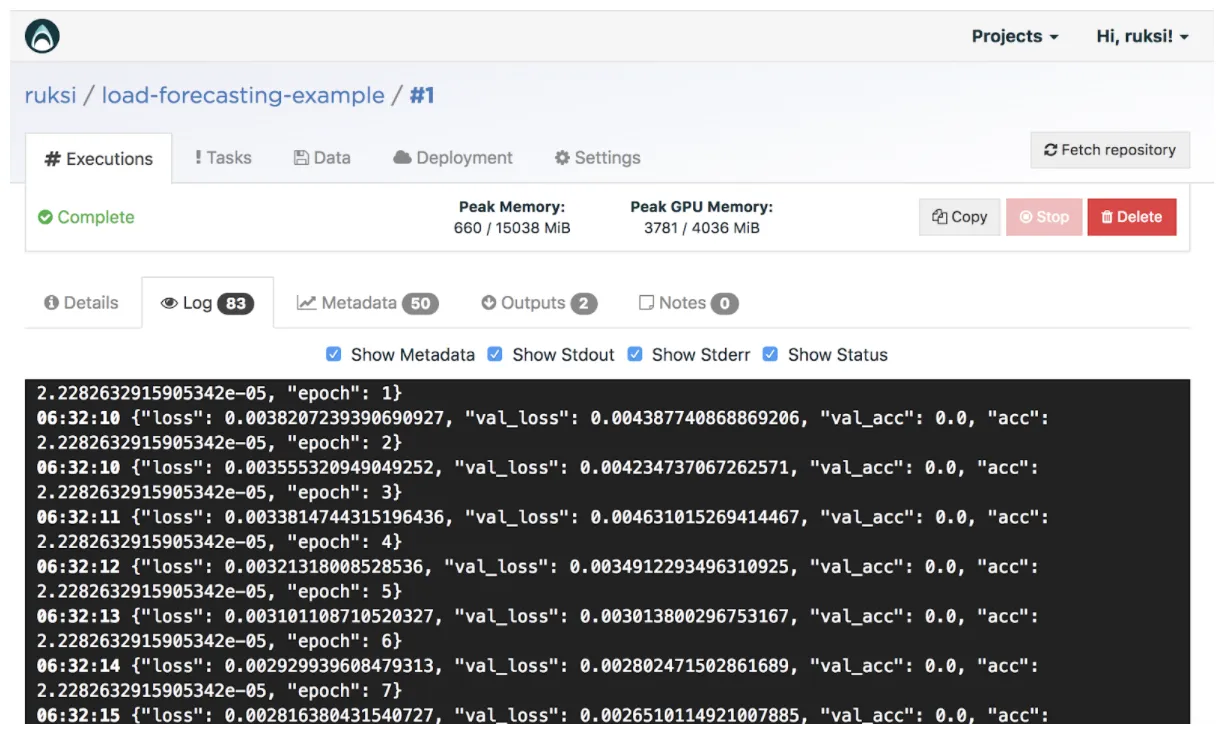
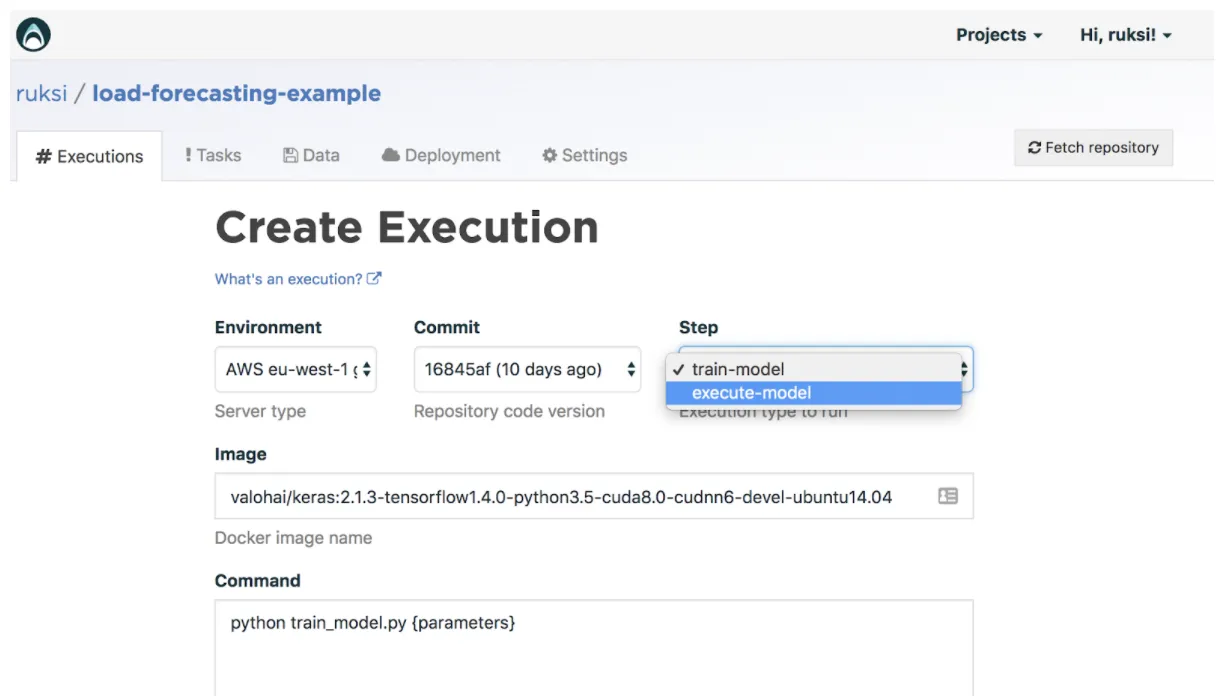
To get the final score (MSE and MAPE) of our trained model, we are going to repeat the process of creating an execution however the “step” field needs to be changed to “execute-model.”
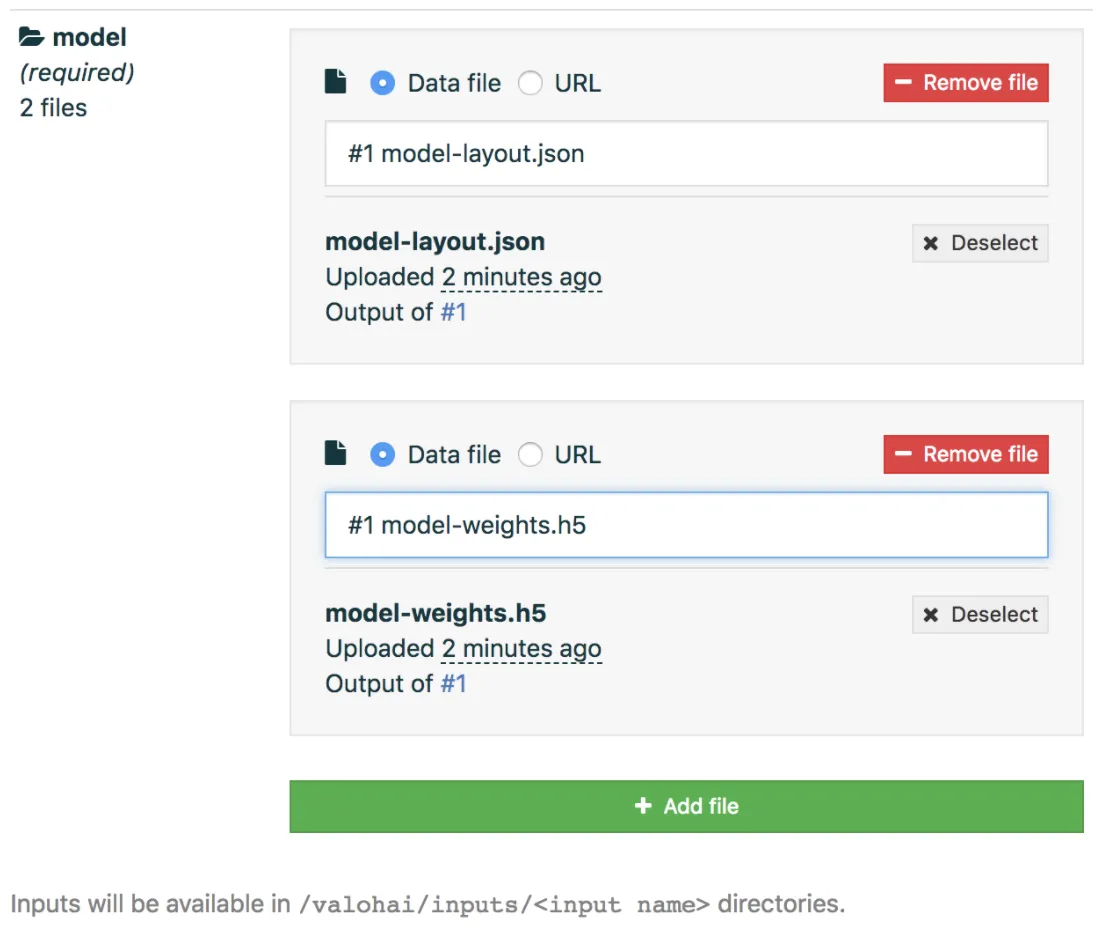
And you need to select the outputs of the previous execution as inputs for this next execution.
Once this execution has been created and executed, you will be able to see the score of this specific machine learning model like below:

Now you could repeat the process with various hyperparameters to get more optimal MSE, or even schedule the training using Valohai API. To start improving the code itself, you can fork the GitHub project at: https://github.com/valohai/load-forecasting