
This article shows an example of a pipeline that integrates Valohai and Superb AI to train a computer vision model using pre-trained weights and transfer learning. For the model, we are using YOLOv3, which is built for real-time object detection.
Superb AI is used in this example to manage the training data and produce a labeled dataset that can be used for training. Valohai, on the other hand, takes in that data and runs a pipeline with a training step and a batch inference step. We’ve written a more thorough breakdown of how these platforms complement each other here.
- Superb AI is an ML DataOps platform that helps computer vision teams automate and manage the full data pipeline: from ingestion and labeling to data quality assessment and delivery.
- Valohai is an MLOps platform that helps build and operate fully automated training pipelines on any cloud or on-prem hardware. Perfect for computer vision and deep learning.
Project details
| Repository | https://github.com/valohai/yolov3-tf2 |
| Model | YOLOv3-416 (weights) |
| Frameworks | Tensorflow 2.4.0 + OpenCV 4.1 |
| Mode | Transfer Learning |
| Dataset | ~3000 images (COCO 2017 validation set) |
| Classes | person, car, chair, book, bottle |
Note: The pipeline is generic, which means it is trivial to train with any dataset and any kind of classes from the Superb.ai platform, using any weights that fit the YOLOv3 model. Listed here are just the defaults we used.
Preparing the data in Superb AI
First, we need to create a new project in the Superb AI platform. Choose any name and description. The data type will be Image and annotation type Box for this example.
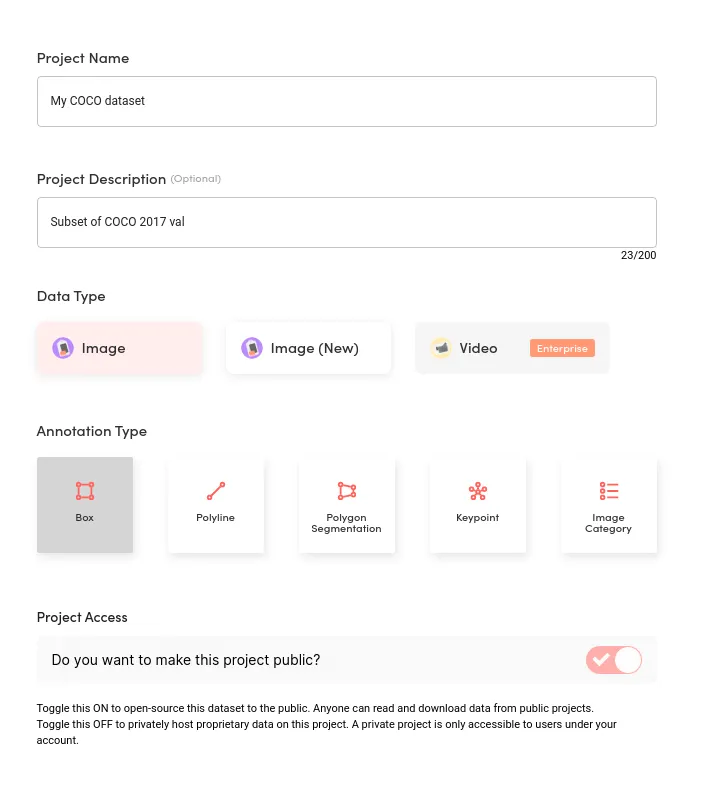
Then add five classes (person, car, chair, book, bottle) to match our COCO dataset, which we will upload to the platform.
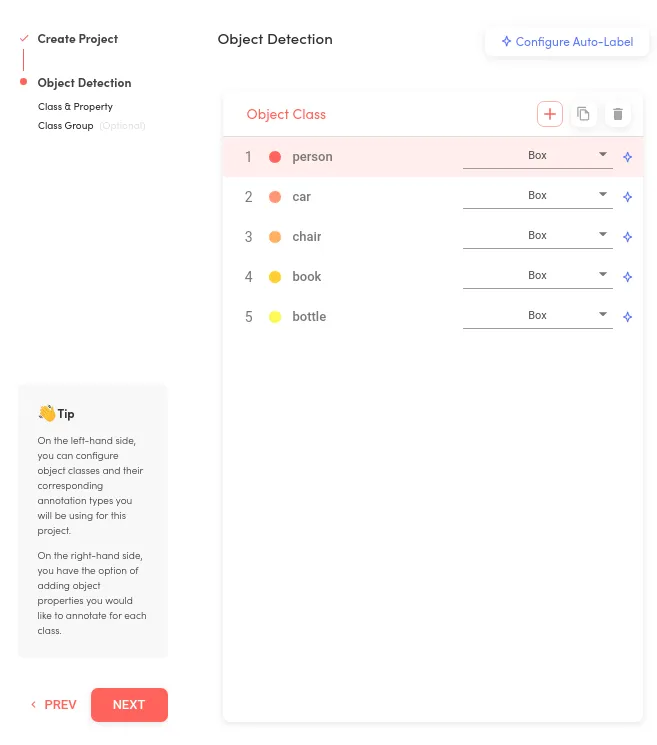
One can utilize the Superb AI’s automatic labeling features too, but in this example, we will have the labels already in the COCO dataset. Now that we have our project and dataset template prepared in the platform, it is time to convert and upload the actual data + labels using Superb AI SDK and CLI. Follow the instructions in this example repository.
Once the conversion and upload are done, the project should contain more than 3000 images, ready to be used by the training pipeline in Valohai.
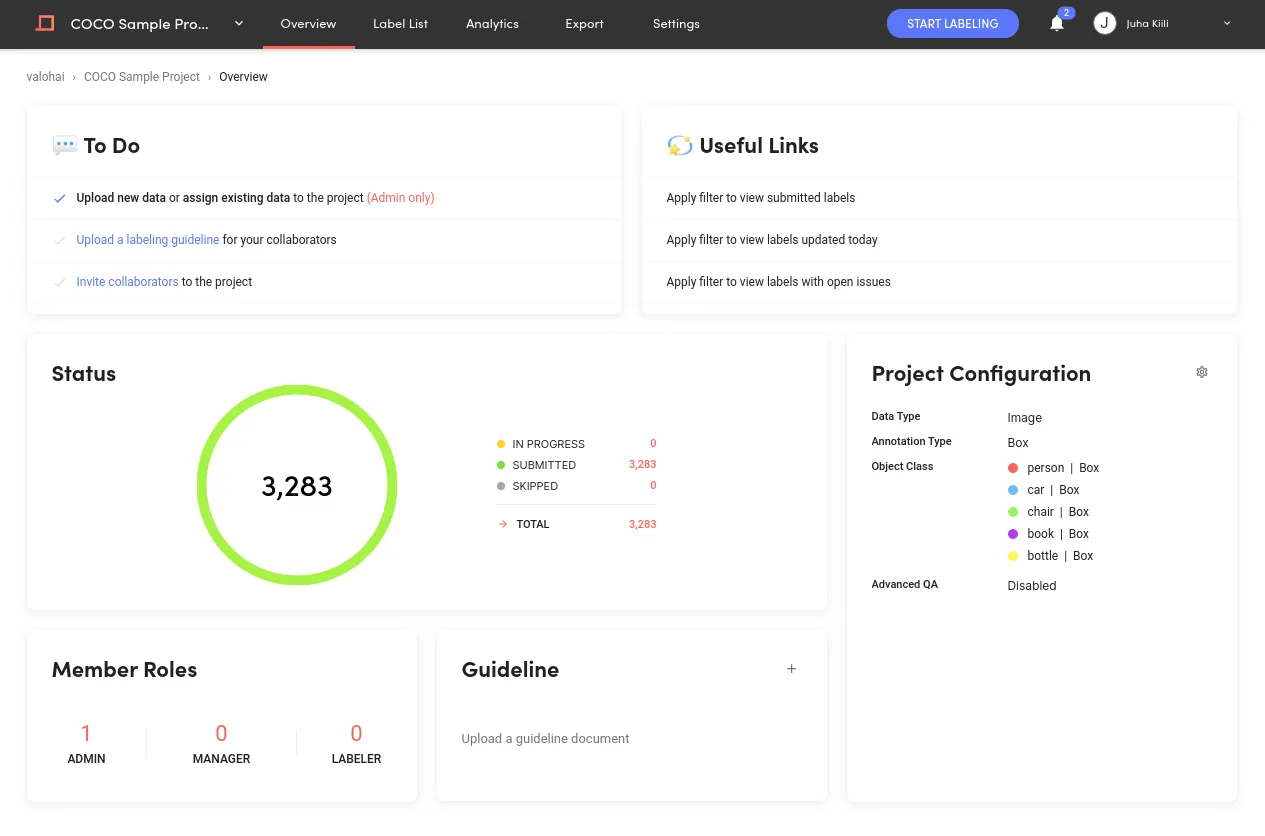
The Valohai training pipeline
In Valohai, the training pipeline is a key component of any successful project. Our example pipeline consists of four steps.
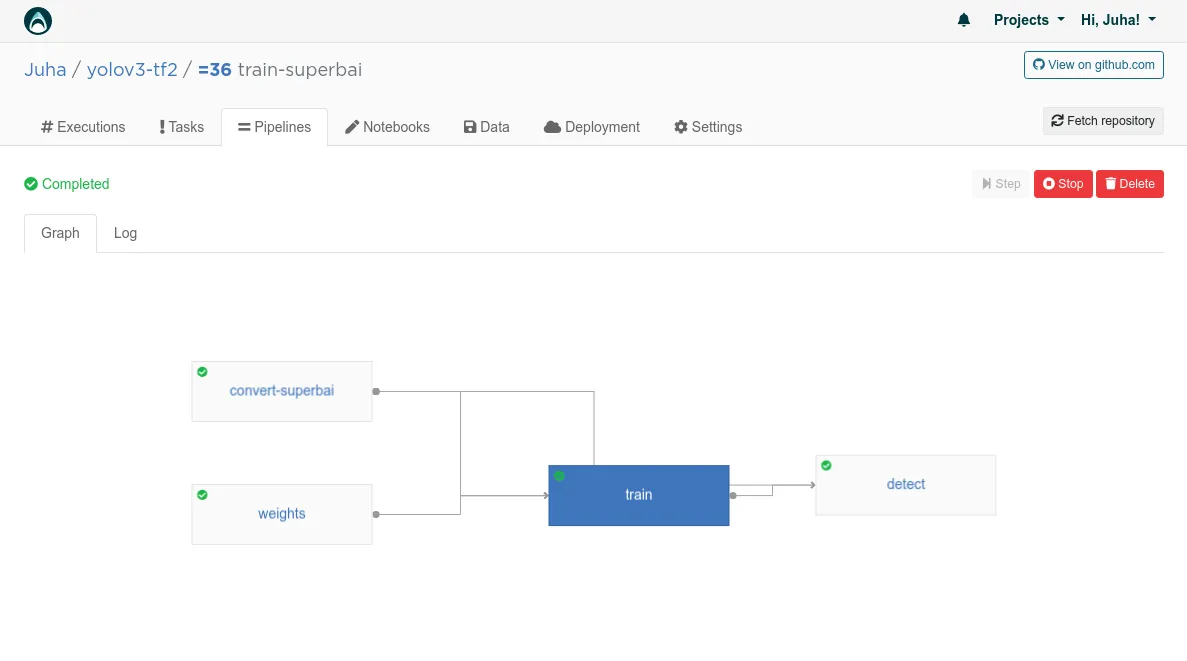
The convert-superbai step pulls the data from Superb.ai, splits the training and validation sets based on Superb.ai tagging, and finally converts the two sets into .tfrecord files for the model.
The weights step downloads the pre-trained weights from Joseph Redmon’s website, converts them to a Tensorflow checkpoint, and finally validates that they work correctly by running inference for a single image.
The train step trains the model in a GPU environment (other steps are CPU by default) based on the hyperparameters.
Finally, the detect step runs inference on the freshly trained model for the set images given as an input for the step. The output of this step is new versions of the images, with bounding boxes and labels rendered on top of the original image.
Each step is (usually) a single Python file. Here is the source code for weights.py of our weights step. It has one parameter weights_num_classes (how many classes were used for the pre-trained model)and one input weights (the actual pre-trained weights).
The parameters and inputs are fed to the valohai.prepare() call to Valohai SDK. Valohai CLI can parse this call to automatically generate the necessary configuration for parameterizing the step.
The pipeline itself is defined in the pipeline.py, which also uses the new SDK.
View code on GitHubSetting up the pipeline in Valohai
First, create a new project in Valohai and link the GitHub example repository from the project settings.
Now you can create a new pipeline from the pipelines tab and select train-superbai from the blueprints dropdown.
Integrating with Superb AI
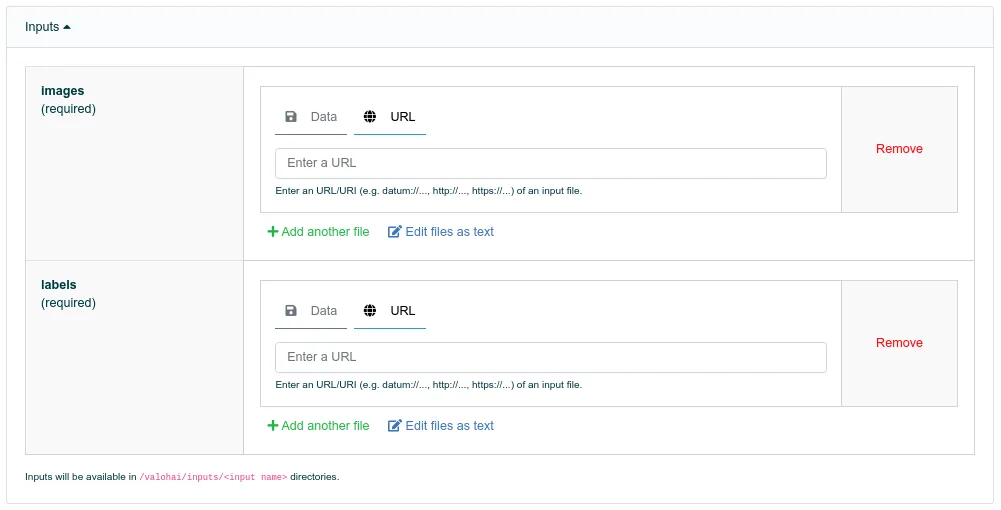
Before running the pipeline, you need to tell it where to get the data. The images and labels are two separate URLs, which means two copy-pastes from Superb.ai to Valohai.
Images: Settings > General(Superb.ai)

Labels: Export > Export History (Superb.ai)

Pipeline Inputs (Valohai)
Running the pipeline
Now that we are integrated with our dataset in the Superb AI platform, our pipeline is ready to rumble!
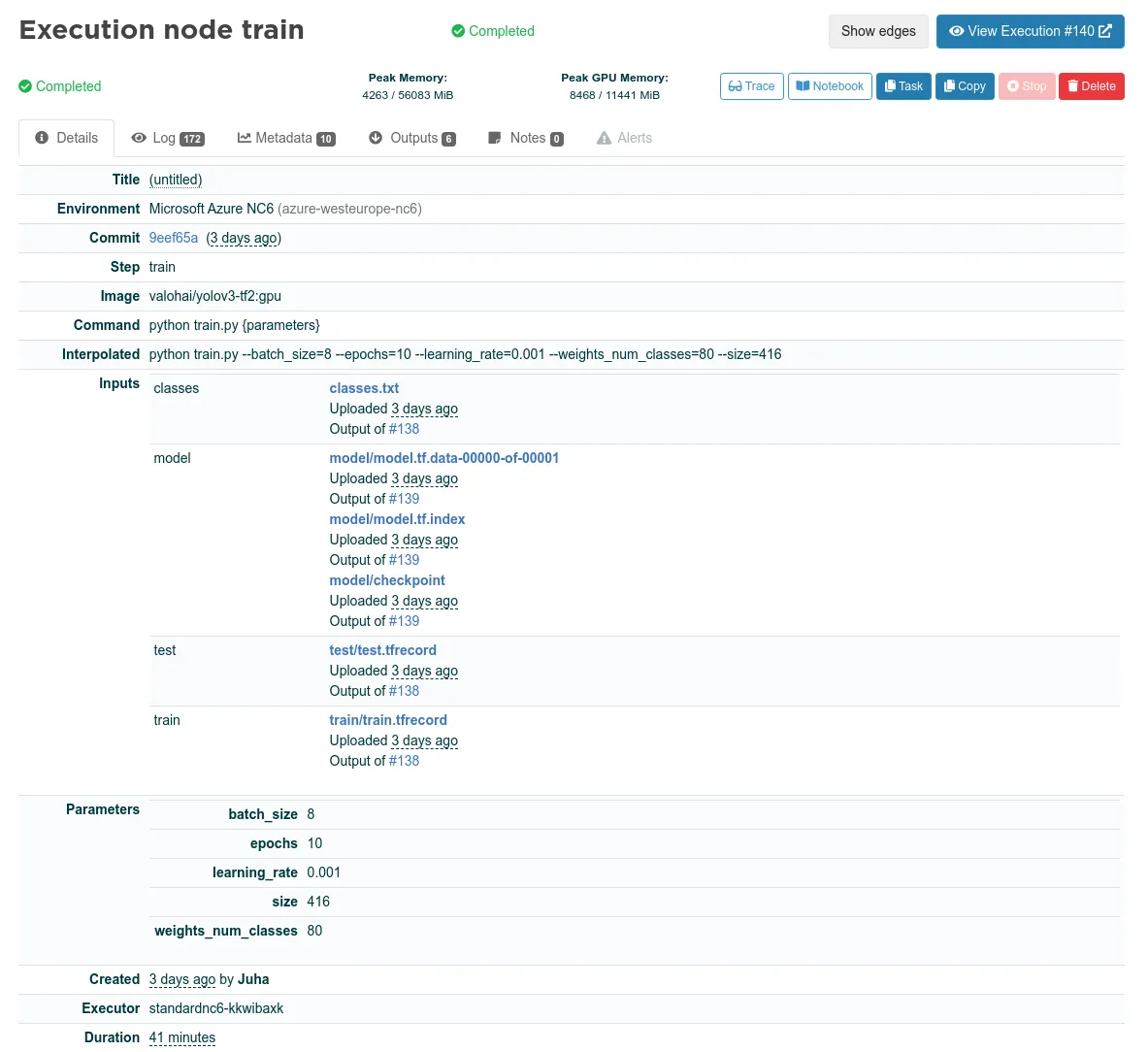
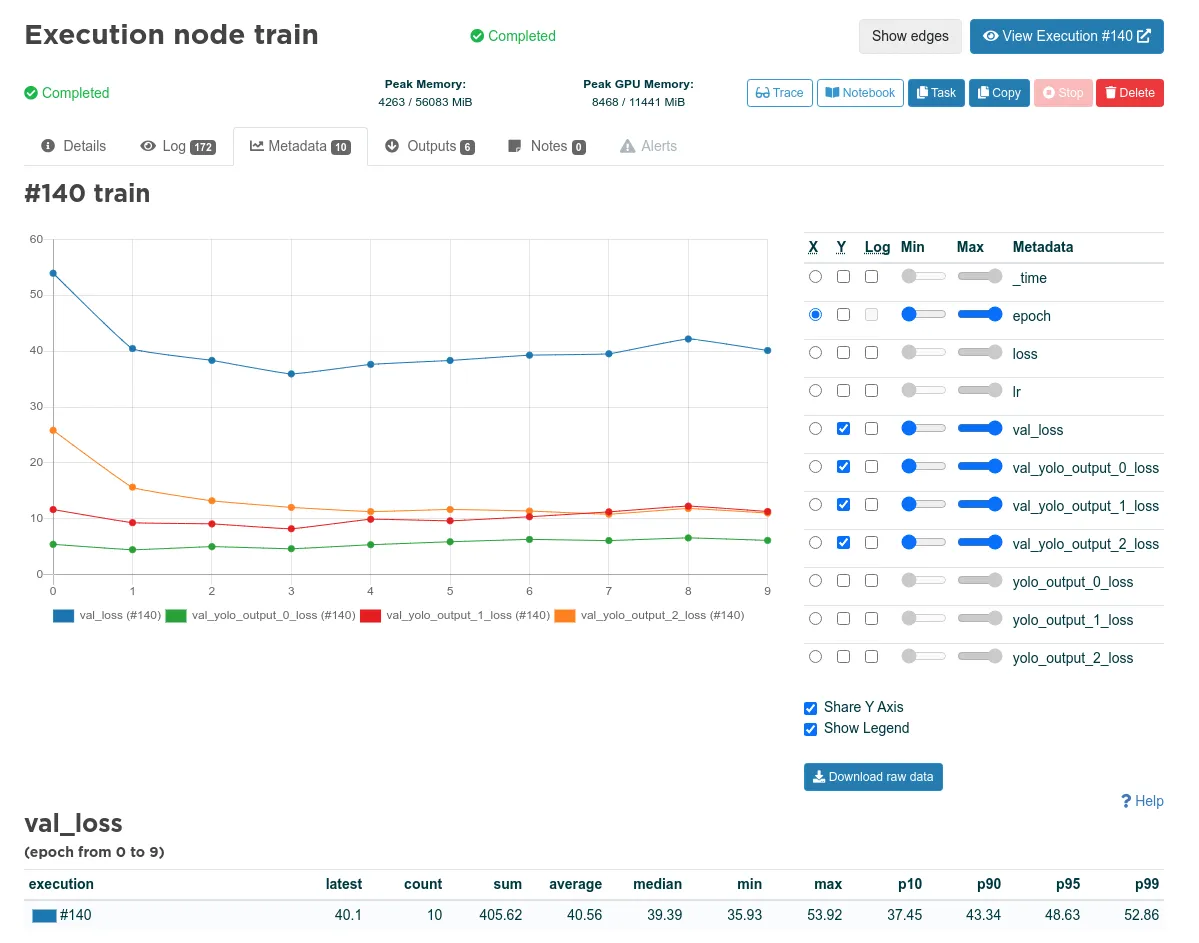
Valohai records all the inputs, parameters, logs, and metrics for each step of the pipeline. These are the inputs, parameters, Docker image, environment, and the rest of the information for the execution of the train step:
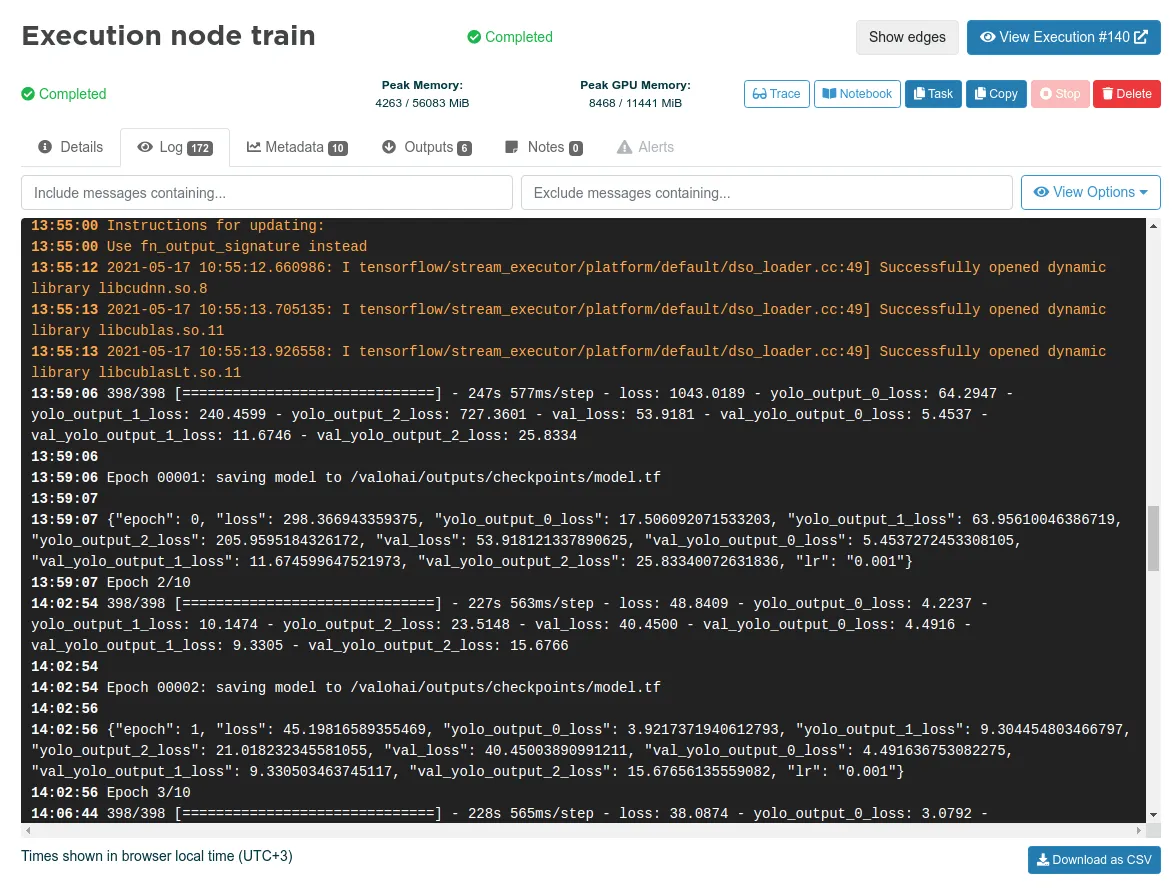
This is a slice of all the logs printed out by the training code.
These are the metrics printed out by the training code. Valohai parses all printed JSON as a metric (called metadata in Valohai).
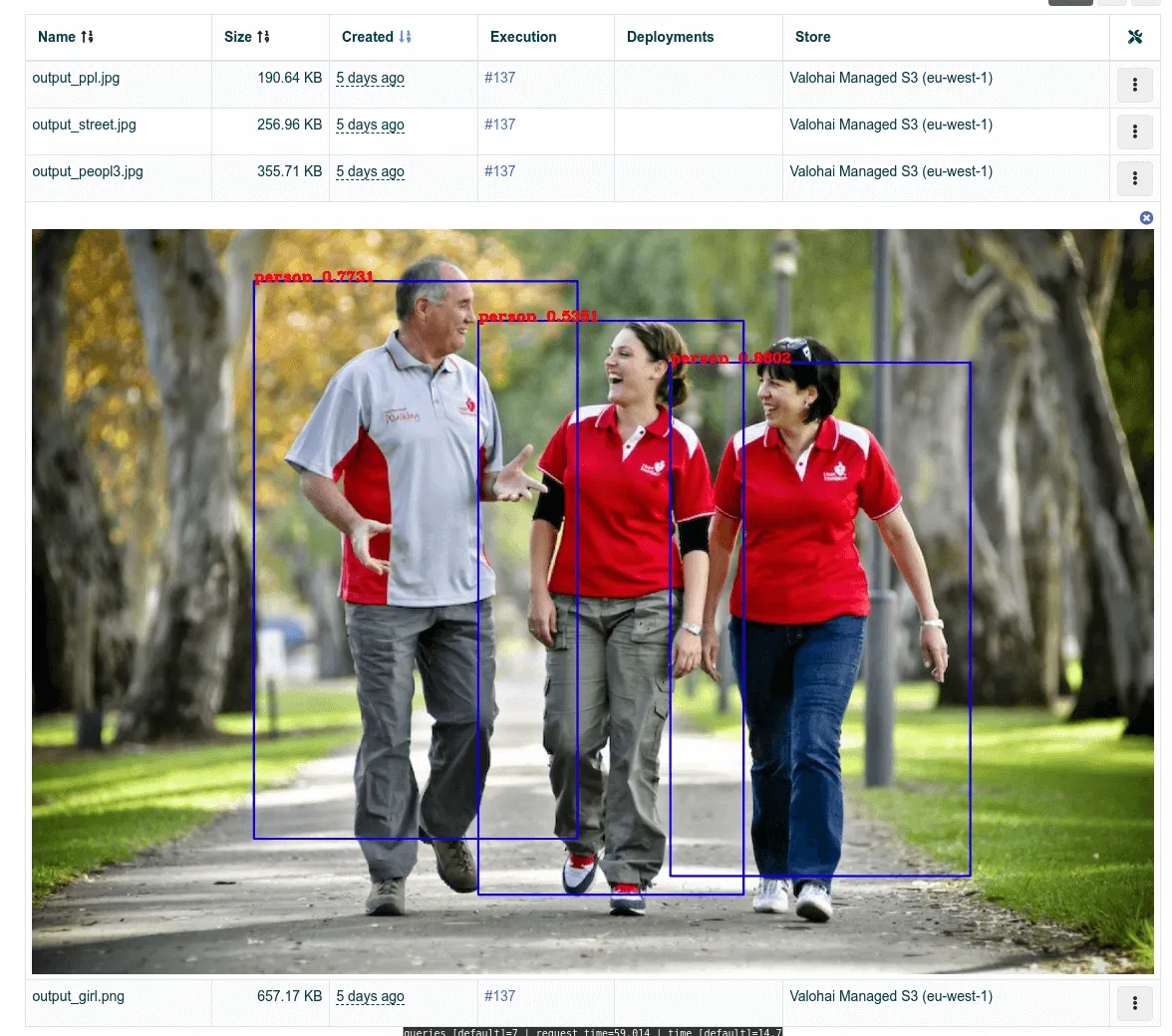
Finally, in the outputs tab of the detect step, we can inspect how the model is performing with some actual images.
Iterating on labels
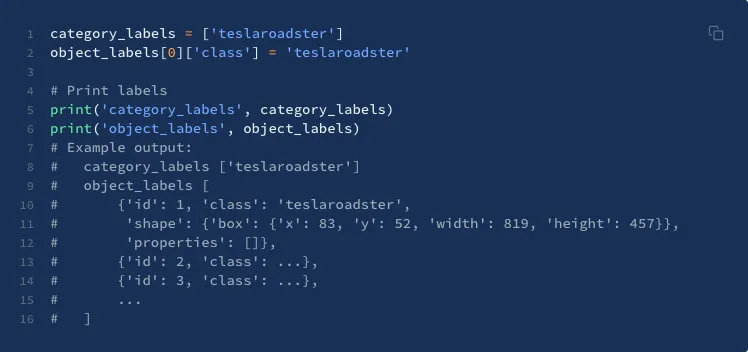
Once you know where your model needs optimization as it relates to data, you can jumpstart your next iteration by quickly sending your model’s output back into the Superb AI Suite via their SDK for model-assisted labeling.
Why setting up an end-to-end pipeline for your YOLOv3 model is a no-brainer
In this article, the end-to-end pipeline is built on top of two purpose built tools: Superb AI for the data management and Valohai for the model lifecycle management. The whole setup in this example can be done within hours, but the value of the upfront work compounds every time the model is trained.
The training dataset evolves over time and it can be relabeled and changed independently from the training pipeline. Similarly, the code in the training pipeline can be iterated, while keeping the end-to-end pipeline intact for continuous operations. Additionally, the training pipeline on Valohai can be scaled with ease to more powerful GPU-instances as the training dataset and modeling complexity grows.
If you want to learn more about end-to-end pipelines with Valohai and Superb AI, fill the form below. 👇