Introduction
After looking at a lot of Java/JVM based NLP libraries listed on Awesome AI/ML/DL I decided to pick the Apache OpenNLP library. One of the reasons comes from the fact another developer (who had a look at it previously) recommended it. Besides, it’s an Apache project, they have been great supporters of F/OSS Java projects for the last two decades or so (see Wikipedia ). It also goes without saying that Apache OpenNLP is backed by the Apache 2.0 license .
In addition, this tweet from an NLP researcher added some more confidence to the matter:
In my current research project, I experimented with @ApacheOpennlp and was delighed to see it’s a valuable NLP toolkit with a user-friendly API. Too early to draw a comparison between @ApacheOpennlp and @stanfordnlp . I will see how they perform in named entity recognition first.
— Linda (Xia) Liu (@DrLiuBigData) March 2, 2019
I’ll like to say my personal experience has been similar with Apache OpenNLP so far and I echo the simplicity and user-friendly API and design. You will see as we explore it further, that being the case.
Exploring NLP using Apache OpenNLP
Java bindings
We won’t be covering the Java API to Apache OpenNLP tool in this post but you can find a number of examples in their docs . A bit later you will also need some of the resources enlisted in the Resources section at the bottom of this post in order to progress further.
Command-line Interface
I was drawn to the simplicity of the CLI available and it just worked out-of-the-box, for instances where a model was needed, and when it was provided. It would just work without additional configuration.
To make it easier to use and also not have to remember all the CLI parameters it supports I have put together some shell scripts . Have a look at the README to get more insight into what they are and how to use them.
Getting started
You will need the following from this point forward:
- Git client 2.x or higher (an account on GitHub to fork the repo)
- Java 8 or higher (suggest install GraalVM CE 19.x or higher)
- Docker CE 19.x or higher and check it is running before going further
- Ability to run shell scripts from the CLI
- Understand reading/writing shell scripts (optional)
Note: At the time of the writing version 1.9.1 of Apache OpenNLP was available.
We have put together scripts to make these steps easy for everyone:
This will lead us to the folder with the following files in it:
Note: a docker image *has been provided to be able to run a docker container that would contain all the tools you need to go further.
You can see the shared folder has been created, which is a volume mounted into your container but it’s actually a directory created on your local machine and mapped to this volume.
So anything created or downloaded there will be available even after you exit out of your container!
Have a quick read of the main README file to get an idea of how to go about using the docker-runner.sh shell script , and take a quick glance at the Usage section as well.
Thereafter also take a look into the Apache OpenNLP README file to see the usages of the scripts provided there in.
Run the NLP Java/JVM docker container
At your local machine command prompt while at the root of the project, do this:
There is a chance you get this first, before you get the prompt:
And then you will be presented with prompt inside the container:
The container is packed with all the Apache OpenNLP scripts/tools you need to get started with exploring various NLP solutions.
Installing Apache OpenNLP inside the container
Here is how we go further from here when you are inside the container, at the container command-prompt:
You will see the apache-opennlp-1.9.1-bin.tar.gz artifact being downloaded and expanded into the shared folder:
Viewing and accessing the shared folder
Just as you run the container, a shared folder is created, it maybe empty in the beginning but as we go along we will find it fill up with different files and folders.
It’s also where you will find the downloaded models and the Apache OpenNLP binary exploded into its own directory (by the name apache-opennlp-1.9.1 ).
You can access and see the contents of it from the command-prompt (outside the container) as well:
From inside the container this is what you see:
Performing NLP actions inside the container
The good thing is without ever leaving your current folder you can perform these NLP actions (checkout the Exploring NLP Concepts section in the README ):
Usage help of any of the scripts: at any point in time you can always query the scripts by calling them this way:
For e.g.
gives us this usage text as output:
- Detecting language in a single line text or article (see legend of language abbreviations used)
See Detecting languages section in the README for more examples and detailed output.
- Detecting sentences in a single line text or article.
See Detecting sentences section in the README for more examples and detailed output.
- Finding person name, organisation name, date, time, money, location, percentage information in a single line text or article.
See Finding names section in the README for more examples and detailed output. There are a number of types of name finder examples in this section.
- Tokenize a line of text or an article into its smaller components (i.e. words, punctuation, numbers).
See Tokenise section in the README for more examples and detailed output.
- Parse a line of text or an article and identify groups of words or phrases that go together (see Penn Treebank tag set for legend of token types), also see https://nlp.stanford.edu/software/lex-parser.shtml.
See Parser section in the README for more examples and detailed output.
- Tag parts of speech of each token in a line of text or an article (see Penn Treebank tag set for legend of token types), also see https://nlp.stanford.edu/software/tagger.shtml.
See Tag Parts of Speech section in the README for more examples and detailed output.
- Text chunking by dividing a text or an article into syntactically correlated parts of words, like noun groups, verb groups. You apply this feature on the tagged parts of speech text or article. Apply chunking on a text already tagged by PoS tagger (see Penn Treebank tag set for legend of token types, also see https://nlpforhackers.io/text-chunking/ )
See Chunking section in the README for more examples and detailed output.
Exiting from the NLP Java/JVM docker container
It is as simple as this:
And you are back to your local machine prompt.
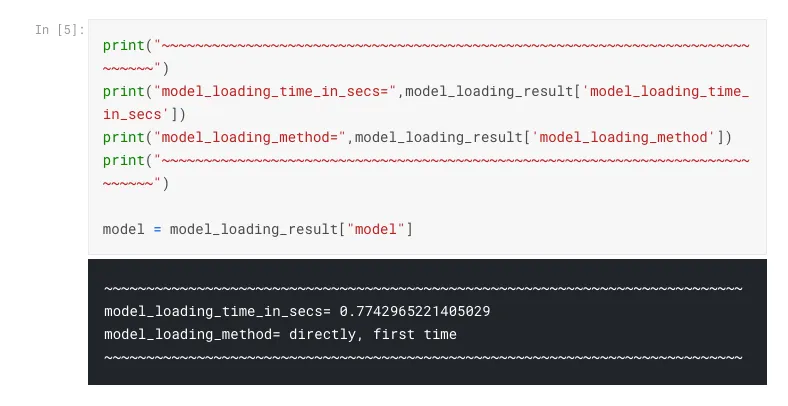
Benchmarking
One of the salient features of this tool is, it’s recording and reporting metrics of it’s actions at different execution points - time taken at micro and macro levels, here’s a sample output to illustrate this feature:
From the above I have come across 5 metrics that are useful for me as a scientist or an analyst or even as an engineer:
Information like this is invaluable when it comes to making performance comparisons like:
- between two or more models (load-time and run-time performance)
- between two or more environments or configurations
- between applications doing the same NLP action put together using different tech stacks
- also includes different languages
- finding co-relations between different corpuses of text data processed (quantitative and qualitative comparisons)
Empirical example
BetterNLP library written in python is doing something similar, see Kaggle kernels: Better NLP Notebook and Better NLP Summarisers Notebook (search for time_in_secs inside both the notebooks to see the metrics reported).
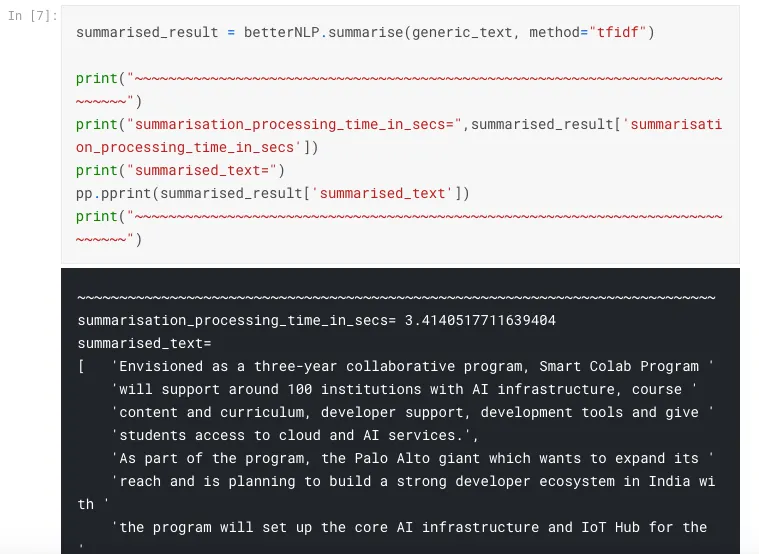
Personally, it’s quite inspiring and also validates that this is a useful feature (or action) to offer to the end-user.
Other concepts, libraries and tools
There are other Java/JVM based NLP libraries mentioned in the Resources section below, for brevity we won’t cover them. The links provided will lead to further information for your own pursuit.
Within the Apache OpenNLP tool itself we have only covered the command-line access part of it and not the Java Bindings. In addition, we haven’t gone through all the NLP concepts or features of the tool again for brevity have only covered a handful of them. But the documentation and resources on the GitHub repo should help in further exploration.
You can also find out how to build the docker image for yourself, by examining the docker-runner script .
Conclusion
After going through the above, we can conclude the following about the Apache OpenNLP tool by exploring its pros and cons:
Pros
- It’s an easy to use API and understand
- Shallow learning curve and detailed documentation with lots of examples
- Covers a lot of NLP functionality, there’s more in the docs to explore than we did above
- Easy shell scripts and Apache OpenNLP scripts have been provided to play with the tool
- Lots of resources available below to learn more about NLP (See the Resources section below)
- Resources provided to quickly get started and explore the Apache OpenNLP tool
Cons
- Looking at the GitHub repo, it seems the development is slow or has been stagnated (last two commits have a wide gap i.e. May 2019 and Oct 15, 2019)
- A few models are missing when going through the examples in the documentation (manual)
- The current models provided may need further training as per your use case(s), see this tweet:
If your project’s success depends heavily on performance of Named Entity Recognition, please start with OpenNLP. Be aware that NER’s results are highly domain specific. If your textual data is very different from the training data OpenNLP or StanfordNLP used, train your own model
— Linda (Xia) Liu (@DrLiuBigData) November 10, 2019
Resources
Apache OpenNLP
-
nlp-java-jvm-example GitHub project
-
Docs
-
Download
-
Legends to support the examples in the docs
Other related posts
- How to do Deep Learning for Java on the Valohai Platform?
- NLP with DL4J in Java, all from the command-line
About me
Mani Sarkar is a passionate developer mainly in the Java/JVM space, currently strengthening teams and helping them accelerate when working with small teams and startups, as a freelance software engineer/data/ml engineer.
- Twitter: @theNeomatrix369
- GitHub: @neomatrix369