
What is Git?
Git is a version control system designed to track changes in a source code over time.
When many people work on the same project without a version control system it’s total chaos. Resolving the eventual conflicts becomes impossible as none has kept track of their changes and it becomes very hard to merge them into a single central truth. Git and higher-level services built on top of it (like Github) offer tools to overcome this problem.
Usually, there is a single central repository (called “origin” or “remote”) which the individual users will clone to their local machine (called “local” or “clone”). Once the users have saved meaningful work (called “commits”), they will send it back (“push” and “merge”) to the central repository.
What is the difference between Git & GitHub?
Git is the underlying technology and its command-line client (CLI) for tracking and merging changes in a source code.
GitHub is a web platform built on top of git technology to make it easier. It also offers additional features like user management, pull requests, automation. Other alternatives are for example GitLab and Sourcetree.
Terminology
-
Repository - “Database” of all the branches and commits of a single project
-
Branch - Alternative state or line of development for a repository.
-
Merge - Merging two (or more) branches into a single branch, single truth.
-
Clone - Creating a local copy of the remote repository.
-
Origin - Common alias for the remote repository which the local clone was created from
-
Main / Master - Common name for the root branch, which is the central source of truth.
-
Stage - Choosing which files will be part of the new commit
-
Commit - A saved snapshot of staged changes made to the file(s) in the repository.
-
HEAD - Shorthand for the current commit your local repository is currently on.
-
Push - Pushing means sending your changes to the remote repository for everyone to see
-
Pull - Pulling means getting everybody else’s changes to your local repository
-
Pull Request - Mechanism to review & approve your changes before merging to main/master
Basic commands
-
git init(Documentation) - Create a new repository on your local computer. -
git clone(Documentation) - Start working on an existing remote repository. -
git add(Documentation) - Choose file(s) to be saved (staging). -
git status(Documentation) - Show which files you have changed. -
git commit(Documentation) - Save a snapshot (commit) of the chosen file(s). -
git push(Documentation) - Send your saved snapshots (commits) into the remote repository. -
git pull(Documentation) - Pull recent commits made by others into your local computer. -
git branch(Documentation) - Create or delete branches. -
git checkout(Documentation) - Switch branches or undo changes made to local file(s). -
git merge(Documentation) - Merge branches to form a single truth.
Rules of thumb for Git
Don’t push datasets
Git is a version control system designed to serve software developers. It has great tooling to handle source code and other related content like configuration, dependencies, documentation. It is not meant for training data. Period. Git is for code only.
In software development, code is king and everything else serves the code. In data science, this is no longer the case and there is a duality between data and code. It doesn’t make sense for the code to depend on data any more than it makes sense for data to depend on code. They should be decoupled and this is where the code-centric software development model fails you. Git shouldn’t be the central point of truth for a data science project.
There are extensions like LFS that refer to external datasets from a git repository. While they serve a purpose and solve some of the technical limits (size, speed), they do not solve the core problem of a code-centric software development mindset rooted in git.
You will always have datasets floating around in your local directory though. It is quite easy to accidentally stage and commit them if you are not careful. The correct way to make sure that you don’t need to worry about datasets with git is to use the .gitignore config file. Add your datasets or data folder into the config and never look back.
Example:
# ignore archives
*.zip
*.tar
*.tar.gz
*.rar
# ignore dataset folder and subfolders
datasets/Don’t push secrets

This should be obvious, yet the constant real-world mistakes prove to us it is not. It doesn’t matter if the repository is private either. In no circumstances should anyone commit any username, password, API token, key code, TLS certificates, or any other sensitive data into git.
Even private repositories are accessible by multiple accounts and are also cloned to multiple local machines. This gives the hypothetical attacker exponentially more targets. Remember that private repositories can also become public at some point.
Decouple your secrets from your code and pass them using the environment instead. For Python, you can use the common .env file with which holds the environment variables, and the .gitignore file which makes sure that the .env file doesn’t get pushed to the remote git repository. It is a good idea to also provide the .env.template so others know what kind of environment variables the system expects.
.env:
API_TOKEN=98789fsda789a89sdafsa9f87sda98f7sda89f7
.env.template:
API_TOKEN=
.gitignore:
.env
hello.py:
import os
from dotenv import load_dotenv
load_dotenv()
api_token = os.getenv('API_TOKEN')This still requires some manual copy-pasting for anyone cloning the repository for the first time. For more advanced setup, there are encrypted, access-restricted tools that can share secrets through the environment, such as Vault.
Note: If you already pushed your secrets to the remote repository, do not try to fix the situation by simply deleting them. It is too late as git is designed to be immutable. Once the cat is out of the bag, the only valid strategy is to change the passwords or disable the tokens.
Don’t push notebook outputs
Notebooks are cool because they let you not only store code but also the cell outputs like images, plots, tables. The problem arises when you commit and push the notebook with its outputs to git.
The way notebooks serialize all the images, plots, and tables is not pretty. Instead of separate files, it encodes everything as JSON gibberish into the .ipynb file. This makes git confused.
Git thinks that the JSON gibberish is equally important as your code. The three lines of code that you changed are mixed with three thousand lines that were changed in the JSON gibberish. Trying to compare the two versions becomes useless due to all the extra noise.

Source: ReviewNB Blog
It becomes even more confusing if you have changed some code after the outputs were generated. Now the code and outputs that are stored in the version control do not match anymore.
There are two options at your disposal.
-
You can manually clear the outputs from the main menu (Cells -> All Output -> Clear) before creating your git commit.
-
You can set up a pre-commit hook for git that clears outputs automatically
We highly recommend investing to option #2 as manual steps that you need to remember are destined to fail eventually.
Don’t use the —force
Sometimes when you try to push to the remote repository, git tells you that something is wrong and aborts. The error message might offer you an option to “use the force” (the -f or --force). Don’t do it! Even if the error message calls for your inner Jedi, just don’t. It’s the dark side.
Obviously, there are reasons why the --force exists and it serves a purpose in some situations. None of those arguments apply to you young padawan. Whatever the case, read the error message, try to reason what could be the issue, ask someone else to help you if needed, and get the underlying issue fixed.
Do small commits with clear descriptions
Inexperienced users often fall into the trap of making huge commits with nonsensical descriptions. A good rule of thumb for any single git commit is that it should only do one thing. Fix one bug, not three. Solve one issue, not twelve. Remember that issues can often be split into smaller chunks, too. The smaller you can make it, the better.
The reason you use version control is that someone else can understand what has happened in the past. If your commit fixes twelve bugs and the description says “Model fixed”, it is close to zero value two months later. The commit should only do one thing and one thing only. The description should communicate the thing was. You don’t need to make the descriptions long-winded novels if the commits are small. In fact, a long description for a commit message implies that the commit is too big and you should split it into smaller chunks!
Example #1: a bad repository

Example #2: a good repository

In real life you often make all kinds of ad-hoc things and end up in the situation #1 on your local machine. If you haven’t pushed anything to the public remote yet, you can still fix the situation. We recommend learning how to use the interactive rebase.
Simply use:
git rebase -i origin/main
The interactive mode offers many different options for tweaking the history, rewording commit messages, and even changing the order. Learn more about the interactive rebase from here.
Don’t be afraid of branching & pull requests

Branching and especially pull requests are slightly more advanced and not everyone’s cup of tea, but if your data science project is mature, in production, and constantly touched by many different people, pull requests may be just the thing that is missing from your process.
When you create a new git repository, it will start with just a single branch called main (or master). The main branch is considered as the “central truth”. Branching means that you will branch out temporarily to create a new feature or a fix to an old one. In the meantime, someone else can work in parallel on their own branch. This is commonly referred to as feature branch workflow.
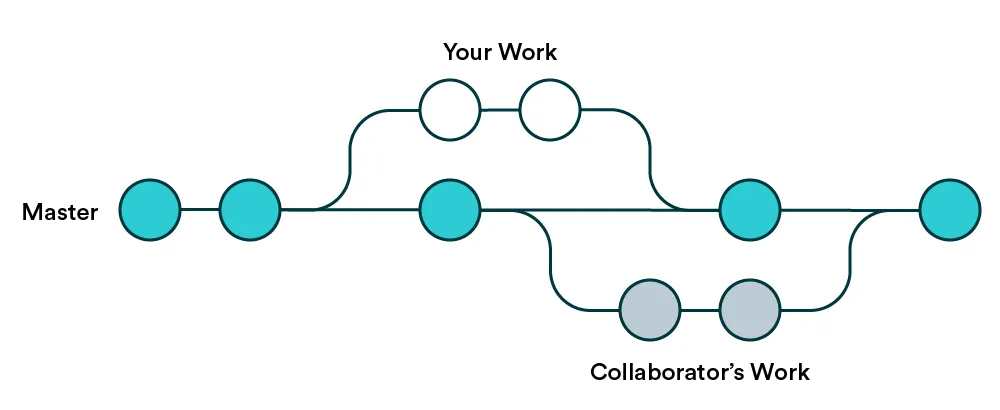
The idea with branches is to eventually merge back to the main branch and update “the central truth”. This is where pull requests come into play. The rest of the world doesn’t care about your commits in your own branch, but merging to main is where your branch becomes the latest truth. That is when it’s time to make a pull request.
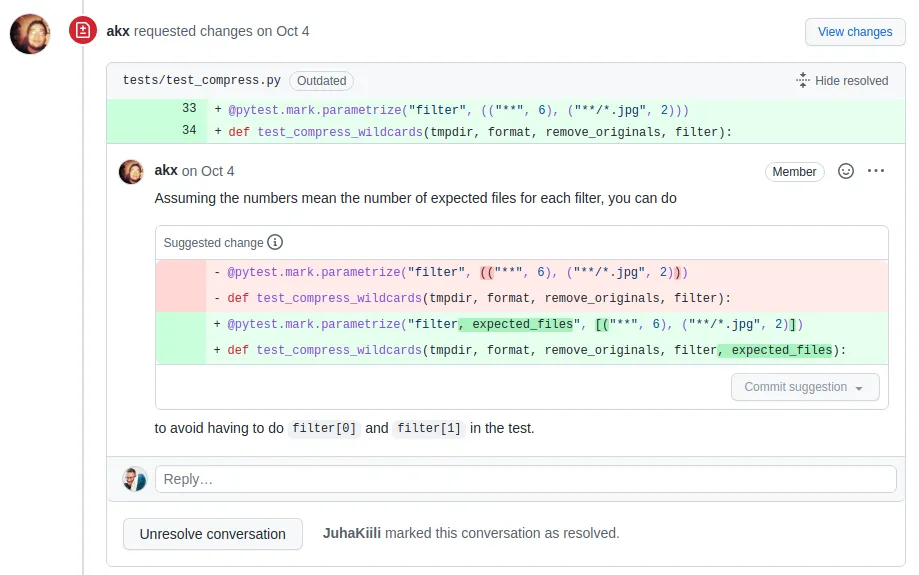
Pull requests are not a git concept, but a GitHub concept. They are a request for making your branch the new central truth. Using the pull request, other users will check your changes before they are allowed to become the new central truth. GitHub offers great tools to make comments, suggest their modifications, signal approval, and finally apply the merge automatically.
Want more practical engineering tips?
Data scientists are increasingly part of R&D teams and working on production systems, which means the data science and engineering domains are colliding. We want to make it easier for data scientists without an engineering background to learn the fundamental best practices of engineering.
We are compiling a guide on engineering topics that we hear data science practitioners think about, including Git, Docker, cloud infrastructure and model serving.
Download the preview edition of the Engineering Practices for Data Scientists and receive the full eBook when we release it.