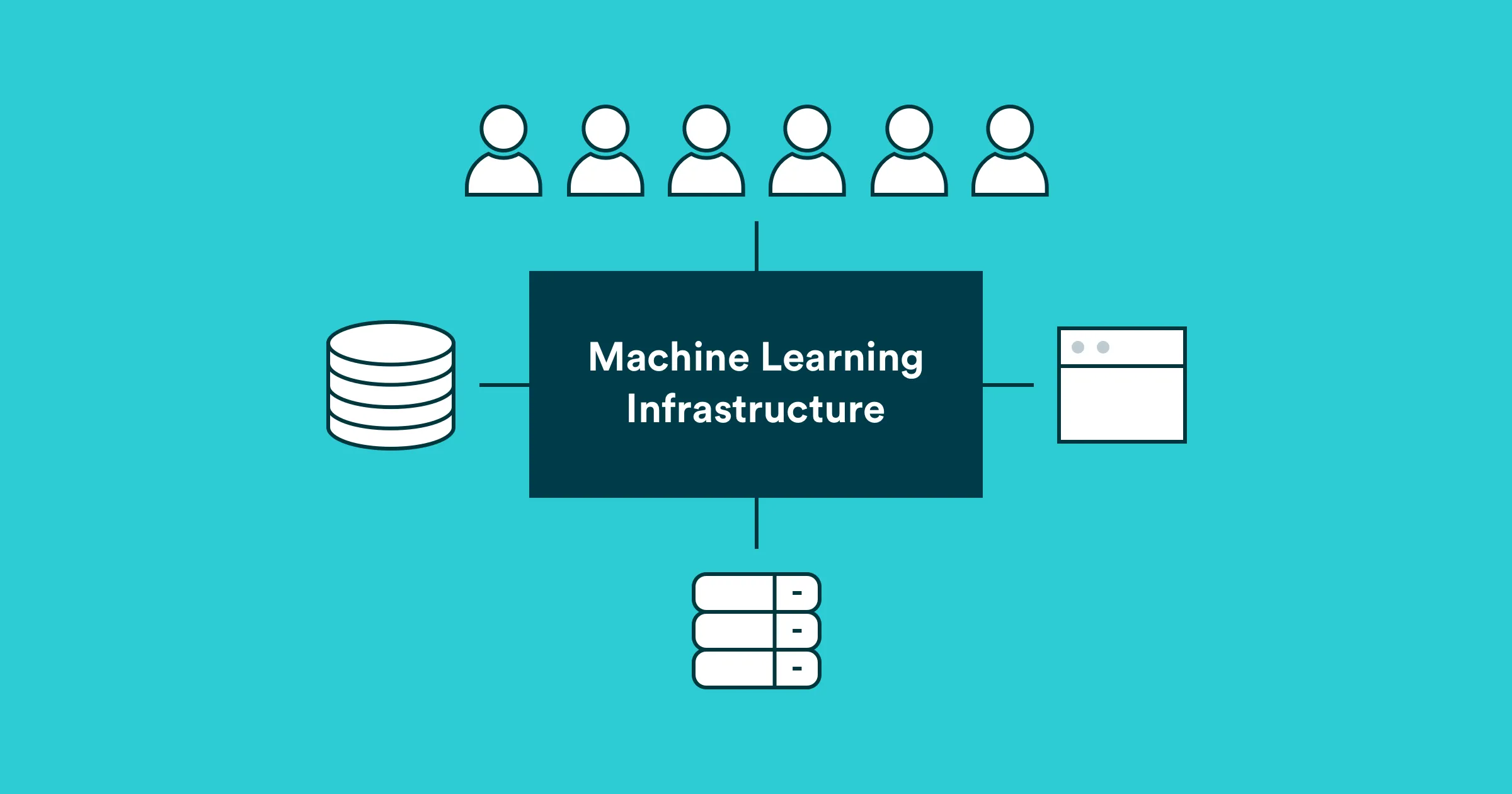
Machine learning infrastructure is one of the biggest things to concentrate on when building production-level machine learning models. One might think that the ML development pipeline is something as straightforward as having the data, having an algorithm, feeding the data to the algorithm, and voilà. In reality, the required infrastructure is vast and very complex.
Below you will find all you need to know about what machine learning infrastructure is and why it is so important, its components, and how to manage an ML infrastructure effectively.
What is machine learning infrastructure, and why is it important?
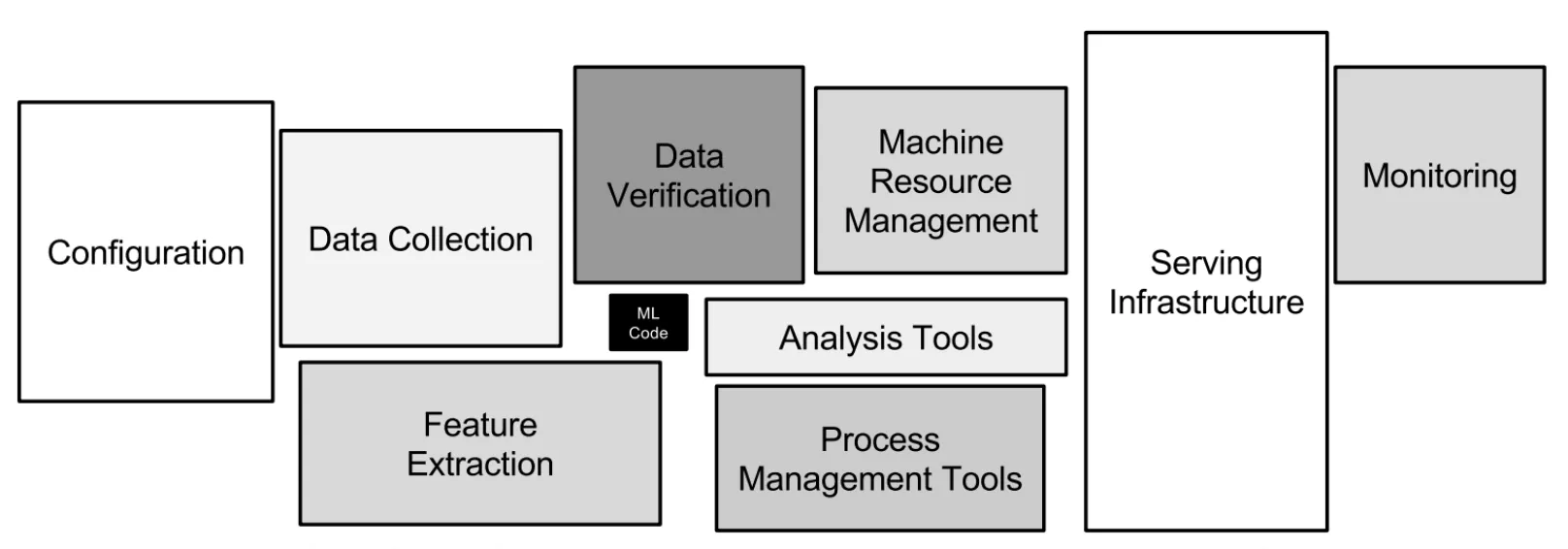
Components of the machine learning infrastructure. From: Hidden Technical Debt in Machine Learning Systems
Currently data scientists, who should concentrate on valuable ML development, need to do lots of DevOps work before they are ready to do the thing they do best — explore the data. Larger companies like Uber and Facebook have built their competitive advantage around machine learning and have proper tools and processes in place, in other words, they have the machine learning infrastructure.
However, the majority of companies are left out as they have neither the knowledge nor the resources to build an efficient and scalable machine learning workflow and pipeline of their own. The gap between big and small players keeps on growing.
To close the gap it is important to have proper tools and processes in place to manage the infrastructure. These will not only save data scientists’ time and shorten the time to market but also help to make sure that finalized models perform as planned. That’s why the business development and data scientist teams within any company have a mutual understanding of what it really takes to build a production-level machine learning infrastructure.
What does the typical machine learning infrastructure look like?
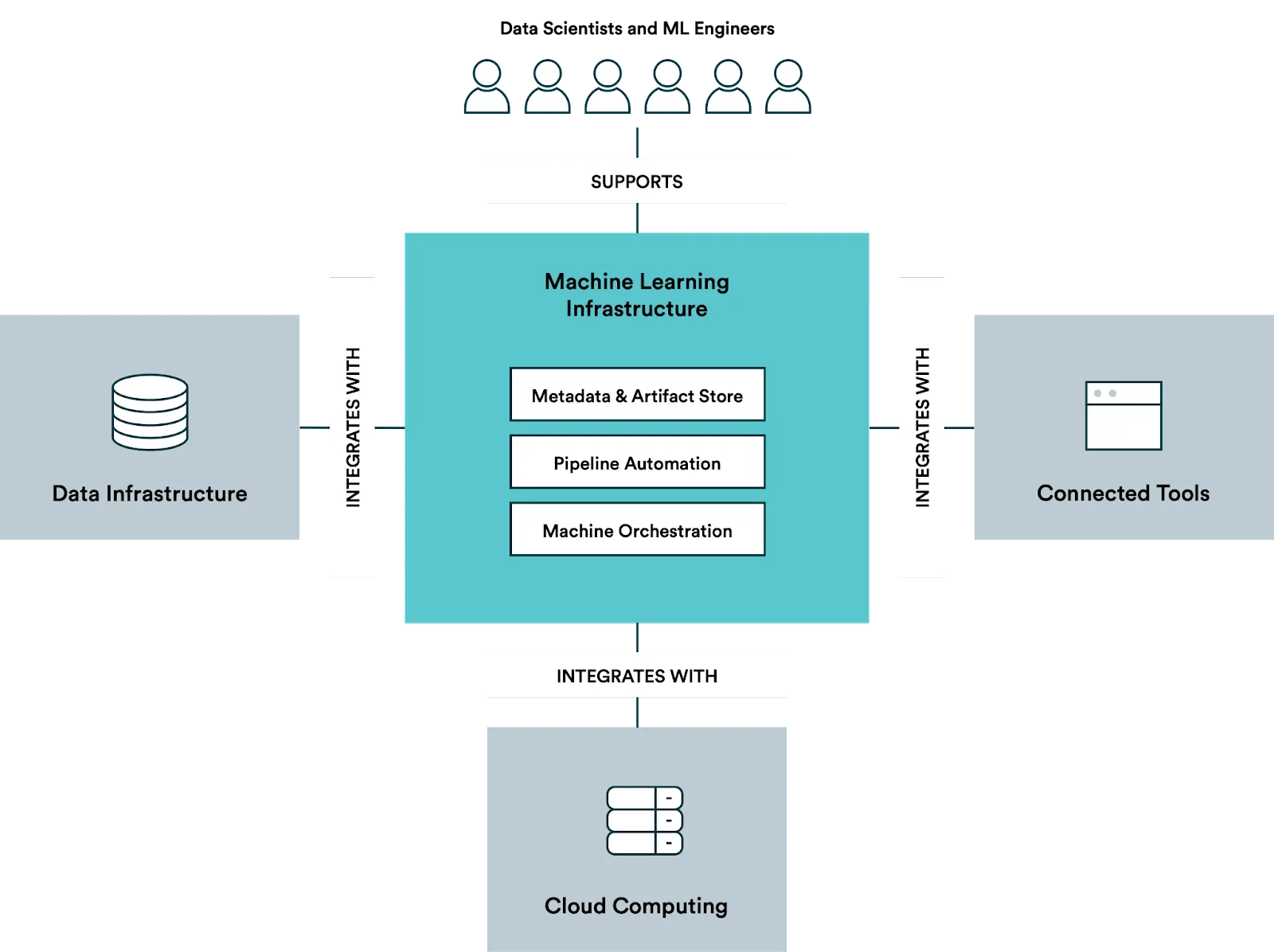
Recordkeeping, logging and version control (a.k.a. metadata and artifact store in the picture above) are, strictly speaking, not a part of a traditional ML platform. However, version control is becoming more and more important because your data scientists should be able to reproduce experiments. Below you can see an example of what versioning might look like based on Valohai’s process.

Automated ML pipelines are a concept where work is split up into different stages, starting from exploration and continuing with batch processing, normalization, training, deployment and many other steps in between. You need to build in support for handing over the results from one step to the next one.
Machine orchestration is the backbone of your machine learning infrastructure. The most advanced engines optimize resource usage, predict need, handle queuing and more.
Inference deployment is the final piece of your ML pipeline deployment. You might not want to make it possible to deploy in a live production environment, but make sure your data science teams are self-sufficient when it comes to deploying new models for the software teams that will be integrating the predictive models into your business apps.
Project and user management support allows to define which resources users - usually data scientists and ML engineers - are able to use, how to queue jobs by different users, which data is available to whom, etc. Because in the end, one will probably want to sandbox experiments into projects and manage privileges for users and teams.
And don’t forget about integrations! Data scientists should be able to continue using the tools and frameworks they love. There should also be different ways of interacting with the data infrastructure, computing devices, and other connected tools depending on the situation.
Why does machine learning infrastructure management matter?
Sometimes the final product does not perform as expected. An Uber self-driven car has run over a pedestrian. There used to be a face recognition system that can detect only people with lighter skin tones. One needs to catch the flaw before it’s too late and it ends up in production.
Before you catch it, you need to know what exactly went wrong and when. Was it a problem with the data set or with its preprocessing? Were some parameters performing better than the others?
To answer these questions, you need to know the exact model that went to production. This also means that the machine learning team needs to have a proper history of all the changes that were ever made always available at hand. And that is why you need a reliable tool to manage your machine learning infrastructure and always be aware of who did what and when.
Using Valohai for your ML infrastructure management
In order to understand why having an ML infrastructure management tool is worth investing in, let us take a look at how things are currently done in companies that do not utilise any MLOps tools.
One team of hundred data scientists kept track of their models by posting the binary file of the model into a Slack channel. It is easy to understand why this is a poor choice if you think about a sales department working without any CRM system. They would just jot their client history down to a Slack channel and try to find notes from there later on. Sounds insane, right?
Here is one more story to solidify the point. One member of a 50 person machine learning team keeps track of his executions in an Excel sheet on his own computer. This can be compared to a situation where a salesman would have a spreadsheet on his own laptop and no other sales team member would know what companies that salesman has contacted and what has been the end result of the meetings.
Just like keeping a record of customers in an Excel sheet would not work for a sales team, keeping a record of machine learning experiments in an Excel sheet does not work for a machine learning team either. Data scientists can have multiple scenarios regarding one data set and all of these should be tracked and visible to every project collaborator.
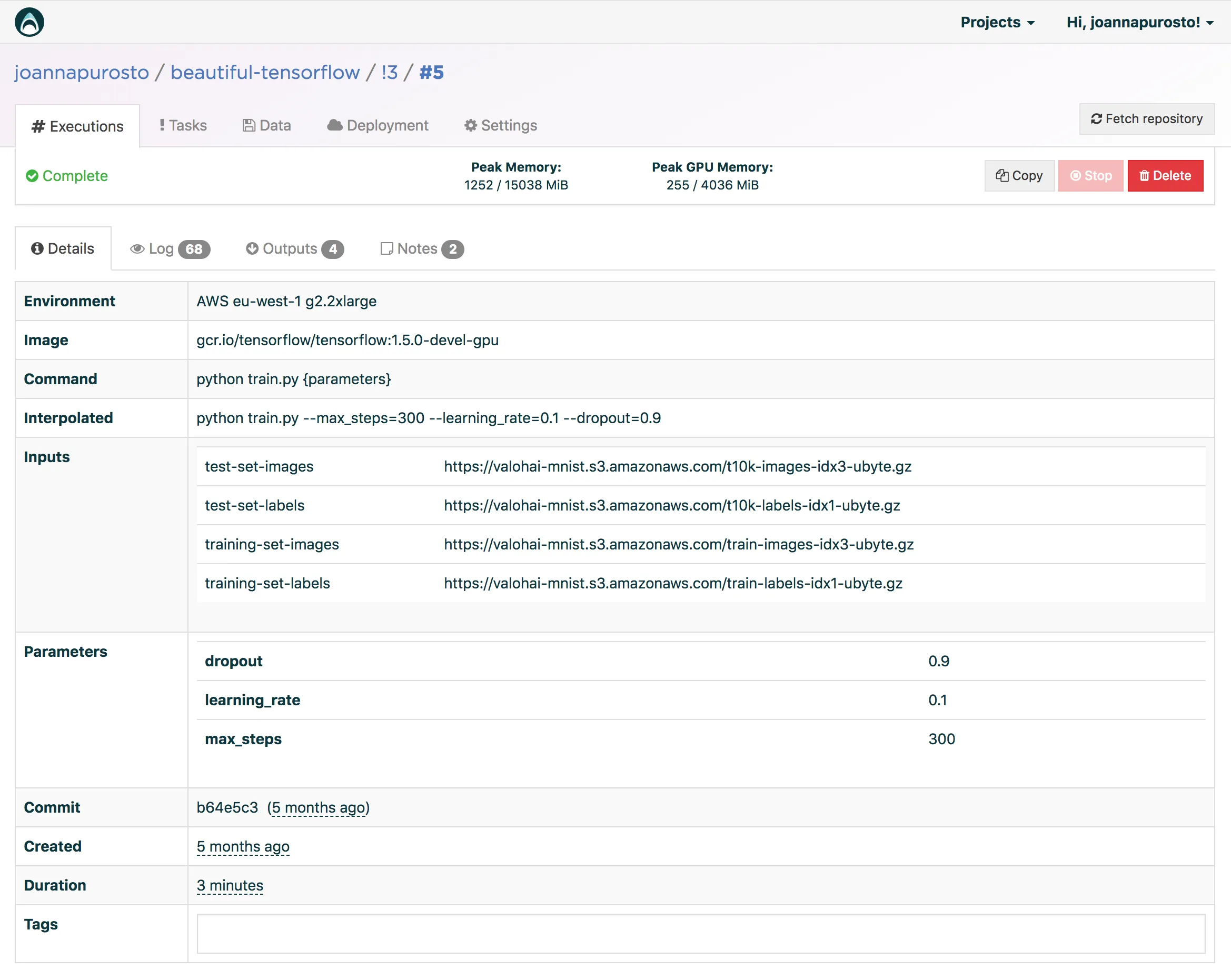
Valohai can turn the pain of versioning control and communication between data scientists and software developers into simple automated tasks. It is a complete scalable machine learning infrastructure service for teams from 1 to 1000 data scientists working with anything from on-premises installations to hybrid clouds and full cloud solutions in Microsoft Azure, AWS and Google Cloud. Valohai takes care of the machine orchestration for you and automatically keeps track of every experiment you or anybody in your company has ever conducted: data, code, hyperparameters, logs, software environment and libraries, hardware — you name it.
Valohai is built on an open API and integrates into your current workflow through a ready-made CLI, an intuitive Web UI, Jupyter notebooks integrations. And with automated pipelines you’re able to kick off a batch job and run every step of your training process without ever touching it manually. The interactive visualization of your metadata helps your team see what everyone else is doing and follow their models converge until they’re ready to push them into production themselves.
One might ask why I would go with the managed platform solution if I can build a custom machine learning infrastructure. That is a good one! If you want to learn more about the topic, we have a comprehensive comparison of open-source and managed platforms.
But to put it short, not only does it take several man-years to build the infrastructure yourself (believe us, we’ve got the history to back that up), but you’ll also need to continuously develop the platform as technologies evolve and new ones need to be supported. By investing in the managed platform now, you can cut down model development time by as much as 90% later.