
As you start incorporating machine learning models into your end-user applications, the question comes up: “When is the model good enough to deploy?”
There simply is no single right answer.
There is no clear-cut measure of when a machine learning model is ready to be put into production, but there are a set of thought experiments that you should go through for each new model.
Identify the Goal of the Machine Learning Model
When you are trying to decide if a machine learning model is ready for deployment, it is helpful to circle back to the algorithm’s original goal. Are you trying to predict customer churn, or when you should reach out to a client? Or is your intent to automatically approve or deny someone’s credit application?
The use case for the model will determine how stringent the requirements for deployment should be. For instance, if the machine learning model will simply be suggesting things to the user, the deployment requirements will be wildly different compared to an algorithm designed to make decisions automatically.
The autonomous driving space has, for example, illustrated this dilemma with six levels of autonomy. As you might imagine, each subsequent level would have stricter requirements.
 The 6 Levels of Vehicle Autonomy Explained
The 6 Levels of Vehicle Autonomy Explained
Simply put, depending on the type of model, you may be able to deploy it right away or potentially need to roll it out in stages. Different models will require different thresholds, and only you can decide what is appropriate on a case-by-case basis.
Strive for X
What metric or combination of metrics decides whether your model is ready for deployment depends on the use case. Accuracy is vital to any machine learning model and is the most often talked about. Without accurate predictions, there is no purpose for deploying the algorithm – so strive for the best accuracy you can within reasonable limitations.
However, depending on your use case, direct test accuracy might not be the only metric to use. It might not even be the most important one. For example, let’s imagine our model would decide whether someone needs surgery or not. It would be a problem if we don’t operate on all the sick people, but we could consider operating on a healthy patient to be a much more significant mistake. In cases like this where false positives are dangerous, metrics like precision, recall, and F1 score might be more appropriate.
But to keep it simple for this article, let’s focus on accuracy.
In practical terms, you’ll be confirming the accuracy of your model in two phases: during the training phase and a separate testing phase. To evaluate accuracy during the training phase, you’ll generally set aside a portion of your data set as validation data and use that set to validate your trained model. As training data, validation data can be used several times to find the optimal hyperparameters.
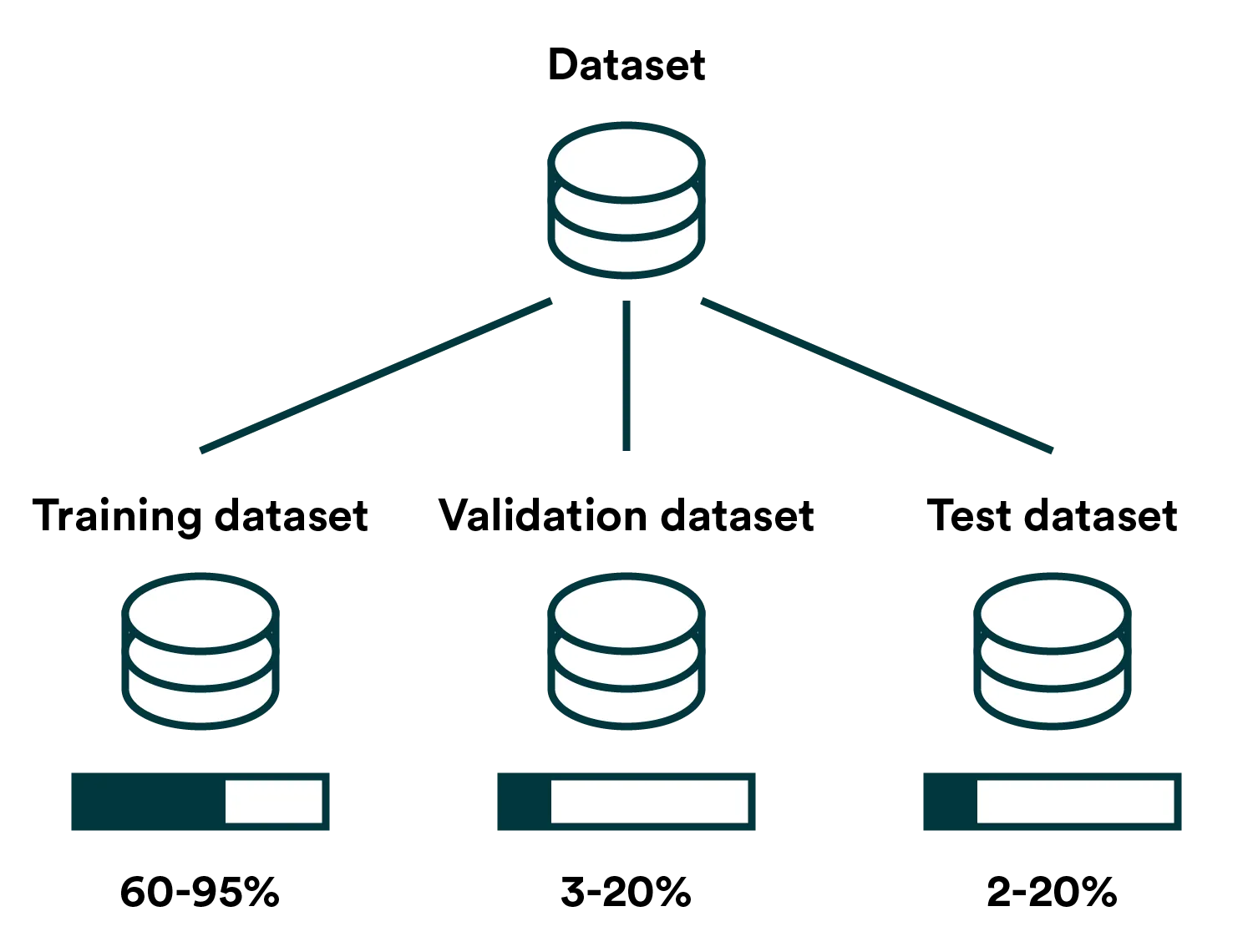 Michael McCourt (SigOpt) wrote about the data split in ‘Practical MLOps: How to Get Ready for Production Models’
Michael McCourt (SigOpt) wrote about the data split in ‘Practical MLOps: How to Get Ready for Production Models’
In the testing phase, you should again evaluate your trained model’s accuracy but using data that hasn’t been used during the training iterations. This is to test whether your model can generalize. In other words, can it produce accurate predictions with new data, or has your model just memorized the answers for the training and validation data? The term used here is overfitting for when a model performs well during training but fails in testing.
 Cassie Kozyrkov (Google) has done a fantastic, short explainer on Validating vs. Testing.
Cassie Kozyrkov (Google) has done a fantastic, short explainer on Validating vs. Testing.
Codify Your Decisions
From an engineering perspective, the criteria you set for your model are not as important as making sure that they are codified into your machine learning pipeline. The accuracy requirements should be written in as baselines within your machine learning pipeline so you can be sure that they are adhered to. Your newly deployed model should also serve as a benchmark for future models, and you may want to always compare your new iterations against the production model in the testing phase.
Similarly, how you perform the data split between training, validation, and testing data should be part of your training pipeline, rather than a manual process or a separate script. After all, in a production setting, the purpose is not to train and deploy a single model once but to build a system that can continuously retrain and maintain the model accuracy. The pipeline is the product – not the model.
If you are interested in learning more about machine learning pipelines and MLOps, consider our other related content.