
Companies and organizations are investing in MLOps to enhance productivity and create best-in-class models. MLOps help to streamline the ML lifecycle by automating repeatable tasks. It also provides best practices to help the data science team effectively collaborate, communicate, and coordinate with other teams.
The machine learning pipeline is a critical concept in MLOps. Ideally, once a machine learning model goes into production, a system is built which can retrain the model as needed, and the system can be developed further instead of relying on ad-hoc workflows.
A significant concern for many firms is finding the most suitable platform to manage their automated workflows. Some are looking toward specific tools built for ML/MLOps, such as Kubeflow, while others are looking at more general-purpose orchestrators such as Argo or Airflow, which can be adapted for machine learning workflows.
In this article, we’ll look at comparing Kubeflow (an end-to-end MLOps platform) and Argo (a general-purpose workflow orchestrator).
Components of Kubeflow
Kubeflow is a free and open-source ML platform that allows you to use ML pipelines to orchestrate complicated workflows running on Kubernetes. This solution was based on Google’s method of deploying TensorFlow models, that is, TensorFlow Extended. The logical components that makeup Kubeflow include the following:
- Kubeflow Pipelines: Empower you to build and deploy portable, scalable machine learning workflows based on Docker containers. It consists of a user interface to manage jobs, an engine to schedule multi-step ML workflows, an SDK to define and manipulate pipelines, and notebooks to interact with the system via SDK.
- KFServing: Enables serverless inferencing on Kubernetes. It also provides performant and high abstraction interfaces for ML frameworks like PyTorch, TensorFlow, scikit-learn, and XGBoost.
- Multi-tenancy: Simplifies user operations to allow users to view and edit only the Kubeflow components and model artifacts in their configuration. Key concepts under this Kubeflow’s multi-user isolation include authentication, authorization, administrator, user and profile.
- Training Operators: Enables you to train ML models through operators. For instance, it provides Tensorflow training (TFJob) that runs TensorFlow model training on Kubernetes, PyTorchJob for Pytorch model training, etc.
- Notebooks: Kubeflow deployment provides services for managing and spawning Jupyter notebooks. Each Kubeflow deployment can include multiple notebook servers and each notebook server can include multiple notebooks.
Components of Argo
Argo is an open-source container-native workflow engine used for orchestrating parallel jobs on Kubernetes. It was created by Applatex, which is a subsidiary of Intuit. Argo can handle tens of thousands of workflows at once, with 1,000 steps each. These step-by-step procedures have dependencies and are referred to as Directed Acyclic Graphs. The major components of the Argo Workflows are discussed as follows:
-
Workflow: This is the most important component in Argo. It serves two primary functions; the first is to define the workflow to be executed and the second is to store the state of the workflow.
-
Templates: There are two major categories of templates, namely Template Definitions and Template Invocators. Template Definitions define the work to be done, usually in a Container. The types of templates under this category include Script, Containers, Resource and Suspend. The resource template is used to create, apply, replace, delete or patch resources on your cluster. The suspend template is used to stop execution for a specific duration. The template invocators are used to invoke or call other templates and provide execution control. The template types under this category include the Step template, which allows you to define tasks in a series of steps, and the DAG template, which allows you to define tasks as a graph of dependencies.
-
Workflow Executor: This is a method that executes a container. It conforms to a specific interface that enables Argo to carry out certain actions like collecting artifacts, managing container lifecycles, monitoring pod logs, etc.
-
Artifact Repository: This is a place where artifacts are stored. Remember that artifacts are files saved by a container.
Similarities between Kubeflow and Argo
Kubeflow and Argo have some things in common albeit built for different purposes. In this section, we will take a look at the similarities between the two platforms.
-
Both platforms have pipeline orchestration capabilities and they take a somewhat similar approach to pipelines. In both platforms, pipeline steps are essentially independent containers that are run, and data flow is defined in the pipeline configuration.
-
Defining pipelines in both will be very familiar to DevOps engineers who’ve built CI/CD systems. With both, you can define pipelines using YAML (a data serialization language often used for writing configuration files). Kubeflow, however, does allow you to use a Python interface for task definition in addition to YAML.
-
Kubeflow and Argo are open-source software. As a result, they can be easily accessed by anyone, from anywhere.
-
Both platforms require Kubernetes and you’ll have a much better time adopting them if you are already well-versed with k8s.
Differences between Kubeflow and Argo
Both platforms have their origins in large tech companies, with Kubeflow originating with Google and Argo originating with Intuit.
Kubeflow is an end-to-end MLOps platform for Kubernetes, while Argo is the workflow engine for Kubernetes. Meaning Argo is purely a pipeline orchestration platform used for any kind of DAGs (e.g. CI/CD). While it can be used to orchestrate ML pipelines, it doesn’t offer other ML-specific features such as experiment tracking or hyperparameter optimization. On the other hand, Kubeflow tries to capture the entire model lifecycle under a single platform which means it has the abovementioned features and many others.
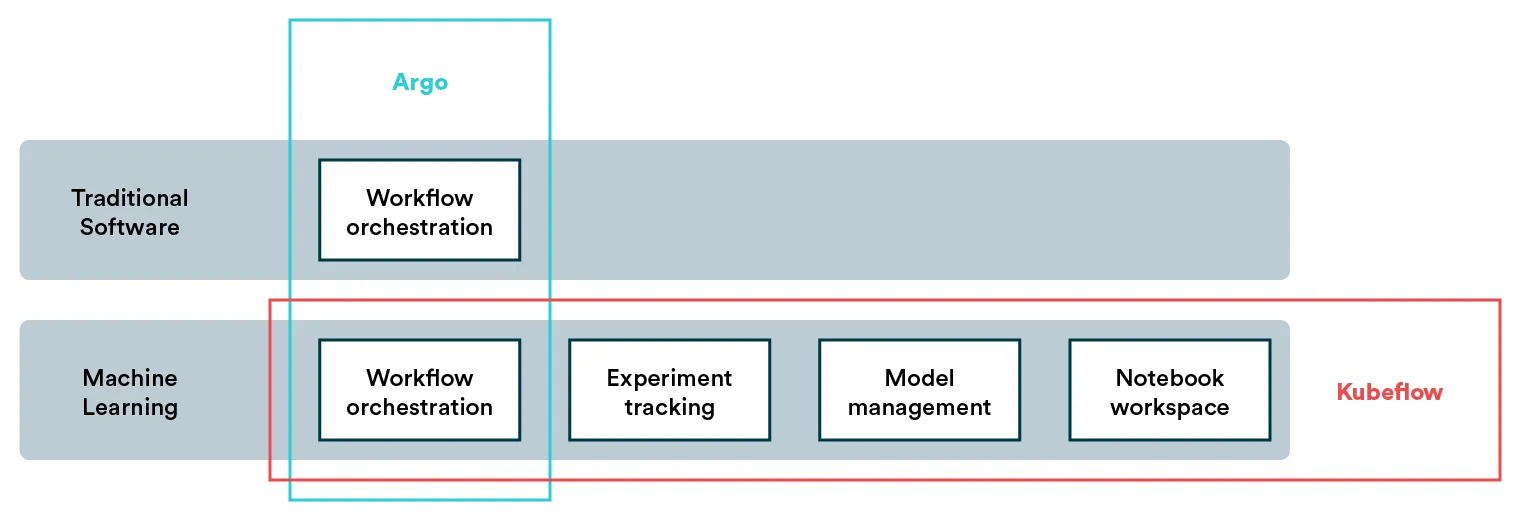
Kubeflow pipelines form a part of Kubeflow that can orchestrate tasks like Argo. In other words, Argo can be seen as a part of Kubeflow. To put it in a better perspective, a combination of Argo and MLflow can give a more comparable feature set to Kubeflow. Comparing the capabilities of the platforms, we can start doing some feature math in our head (this is, of course, not at all exhaustive):
MLflow + Argo = Kubeflow
Kubeflow - Kubeflow Pipelines = MLflow
Kubeflow Pipelines = ArgoSummary
A more comprehensive feature set is always enticing. When both solutions are open-source it might feel logical to adopt the one that comes with more capabilities, especially as they share Kubernetes as a core dependency. However, with features comes complexity.
Suppose you are already using Argo (or any other workflow orchestrator for that matter), and you are looking to implement one or two machine learning pipelines. In that case, the logical choice is to continue with your orchestrator of choice. Additionally, if you have some other ML tools that you love using, sticking to those and adding on Argo might make sense.
However, if you are looking for a comprehensive platform that centralizes everything and will yield benefits as your team grows, Kubeflow may be a better choice.
Valohai as an Alternative for Kubeflow and Argo
[CAUTION: Opinions ahead] As mentioned above, machine learning as a use case has much broader needs than pipeline orchestration. Albeit important, building and automating a machine learning pipeline is often a small portion of the work data scientists and machine learning engineers do.

You may be looking at two options for building out your MLOps stack:
-
First, implementing pipelines with Argo and supporting other aspects of data science work with tools like MLflow for experiment tracking and BentoML for model deployment.
-
Adopting the entire tool stack with Kubeflow (and possibly adopting Kubernetes for the first time too).
Now, I’m not going to argue against using tools like Argo to build a single workflow. That makes total sense. But if your objective is to create a full-fledged MLOps stack, both options laid out above are hefty investments in terms of time and effort. The third option you might not be considering is a managed MLOps platform, namely Valohai.
Valohai provides a similar feature set to Kubeflow in a managed service (i.e. you’ll skip the maintenance, the setup and user support). Like Kubeflow and Argo, Valohai has a similar container-level abstraction for pipelines, making it highly flexible for any use case. You can run any code, any framework on the most popular cloud platforms and on-premise machines.
So if you’re looking for an MLOps platform without the resources of a dedicated platforms team, Valohai should be on your list.

- Valohai Free Trial
- Valohai Product
- Valohai and Kubeflow Comparison
- MLOps Platform: Build vs Buy
- MLOps Platforms Compared
More Kubeflow comparisons
This article continues our series on common tools teams are comparing for various machine learning tasks. You can check out some of our previous Kubeflow comparison articles:
| Other Kubeflow comparison articles |
|---|
| Kubeflow and MLflow |
| Kubeflow and Airflow |
| Kubeflow and Metaflow |
| Kubeflow and Databricks |
| Kubeflow and SageMaker |
| Kubeflow and Argo |