
Machine Learning has created a paradigm shift in the tech world. Today, machines can learn from historical data to make informed decisions and as new data emerge, the decisions become more accurate. As companies continue to adopt ML, some key components to consider are Workflow and Pipelines.
A workflow in the ML process is a set of sequences of tasks, from data collection to model training to deployment. In many cases, the sequence of tasks in a workflow is the same and repetitive. Therefore, creating a medium (pipeline) to automate such workflow is necessary to save time and improve efficiency. As you may already know, the tools needed to manage such pipelines and workflows are known as ML orchestration tools.
There are two popular open-source tools for ML orchestration (Kubeflow and Metaflow) and other open-source orchestration tools that can be used for ML but not explicitly designed for it (Argo, Airflow). Of the two ML orchestration tools, Kubeflow is much broader and could be categorized as an end-to-end MLOps platform, while Metaflow sticks to orchestrating ML pipelines.
In this article, we will compare the fundamental differences and similarities between Kubeflow and Metaflow.
Components of Kubeflow
Kubeflow is a free and open-source ML platform that allows you to use ML pipelines to orchestrate complicated workflows running on Kubernetes. This solution was based on Google’s method of deploying TensorFlow models, that is, TensorFlow Extended. The logical components that makeup Kubeflow include the following:
-
Kubeflow Pipelines: Empower you to build and deploy portable, scalable machine learning workflows based on Docker containers. It consists of a user interface to manage jobs, an engine to schedule multi-step ML workflows, an SDK to define and manipulate pipelines, and notebooks to interact with the system via SDK.
-
KFServing: Enables serverless inferencing on Kubernetes. It also provides performant and high abstraction interfaces for ML frameworks like PyTorch, TensorFlow, scikit-learn, and XGBoost.
-
Multi-tenancy: Simplifies user operations to allow users to view and edit only the Kubeflow components and model artifacts in their configuration. Key concepts under this Kubeflow’s multi-user isolation include authentication, authorization, administrator, user and profile.
-
Training Operators: Enables you to train ML models through operators. For instance, it provides Tensorflow training (TFJob) that runs TensorFlow model training on Kubernetes, PyTorchJob for Pytorch model training, etc.
-
Notebooks: Kubeflow deployment provides services for managing and spawning Jupyter notebooks. Each Kubeflow deployment can include multiple notebook servers and each notebook server can include multiple notebooks.
Components of Metaflow
Metaflow is a Python library that helps teams to build production machine learning. It was developed at Netflix initially to improve the productivity of data scientists who build and maintain different types of machine learning models. However, as mentioned in the introduction, Metaflow is a much more focused tool and as such, the major concepts within it revolve around pipelines and orchestration.
The major components of the Metaflow architecture are discussed as follows:
-
Flow: A flow is simply the smallest unit of computation that can be scheduled for execution. It defines a workflow that pulls data from an external source as input, processes it, and produces output data. To implement a flow, users need to subclass FlowSpec and implement steps as methods, parameters or data triggers. The flow code and its external dependencies are encapsulated in the execution environment.
-
Graph: Metaflow deduces a directed acyclic graph (DAG) based on the transitions between step functions. These transitions are necessary to ensure that the graph is parsed statically from the source code of the flow.
-
Step: A step can be defined as a checkpoint that provides fault tolerance for the system. Metaflow typically takes a snapshot of the data produced by a step and uses it as input to the subsequent steps. Therefore, if a step fails, it can be resumed without having to rerun the preceding steps. Decorators can be used to modify the behavior of a step. The body of a step is known as step code.
-
Runtime (Scheduler): The runtime or scheduler executes a flow; that is, it executes and orchestrates tasks defined by steps in topological order. You can use the metaflow.client, a Python API, to access the results of runs.
-
Datastore: This is an object store where both data artifacts and code snapshots can be persisted. It can be accessible by all environments where the Metaflow code is executed.
Similarities between Kubeflow and Metaflow
Both Kubeflow and Metaflow are in the MLOps space (which is very broad and fuzzy still), but their approaches are quite different.
However, in this section, we will look at some of the similarities between Kubeflow and Metaflow.
-
The two platforms are open source tools and can be accessible by anyone from anywhere.
-
Both leverage Python; while you can define tasks using Python in Kubeflow, Metaflow is completely built as a Python library.
-
Both platforms can be used for orchestration similarly - with Directed Acyclic Graph (DAGs) using containerized runs packaged with their dependencies. The two tools also offer support for pipelines running in parallel.
-
Each platform has a user interface. In Kubeflow, the user interface is known as the central dashboard and it provides easy access to all Kubeflow components deployed in your cluster. On the other hand, Metaflow recently added a user interface as a separate add service.
Differences between Kubeflow and Metaflow
The most obvious difference between these tools is their scope. As mentioned before, Metaflow is focused on orchestrating pipelines. At the same time, Kubeflow tries to capture the entire ML development process with hosted notebooks, serving, etc. on top of pipeline automation.
- Scope: The difference in scope between these two MLOps tools raises the first big question: what do you need? Some teams have already adopted tools that they love for experimentation and model development but are looking for a tool to handle production pipelines. In these cases, Metaflow seems like a more viable option as it comes with less complexity than an end-to-end MLOps platform like Kubeflow.
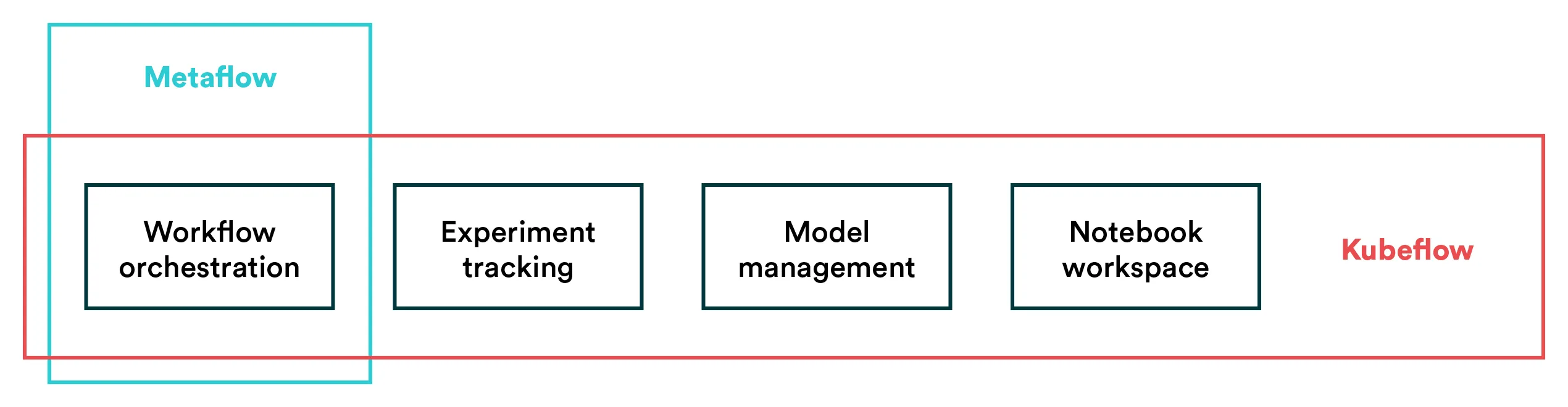
Metaflow is more focused in its scope while Kubeflow tries to capture the whole model lifecycle.
- Approach: Kubeflow and Metaflow have very different approaches to pipelines. Metaflow pipelines are essentially Python methods passing data to each other which makes them rather easy to build. The drawback is that Metaflow is very opinionated about the data in your pipeline and making it work with unconventional data may require workarounds. In Kubeflow pipelines, however, steps run in separate containers and communicate via files. This makes Kubeflow’s approach more versatile, because steps can have their own dependencies and any kind of data is easy to transfer in files. Which approach works better depends on your use case and preference.
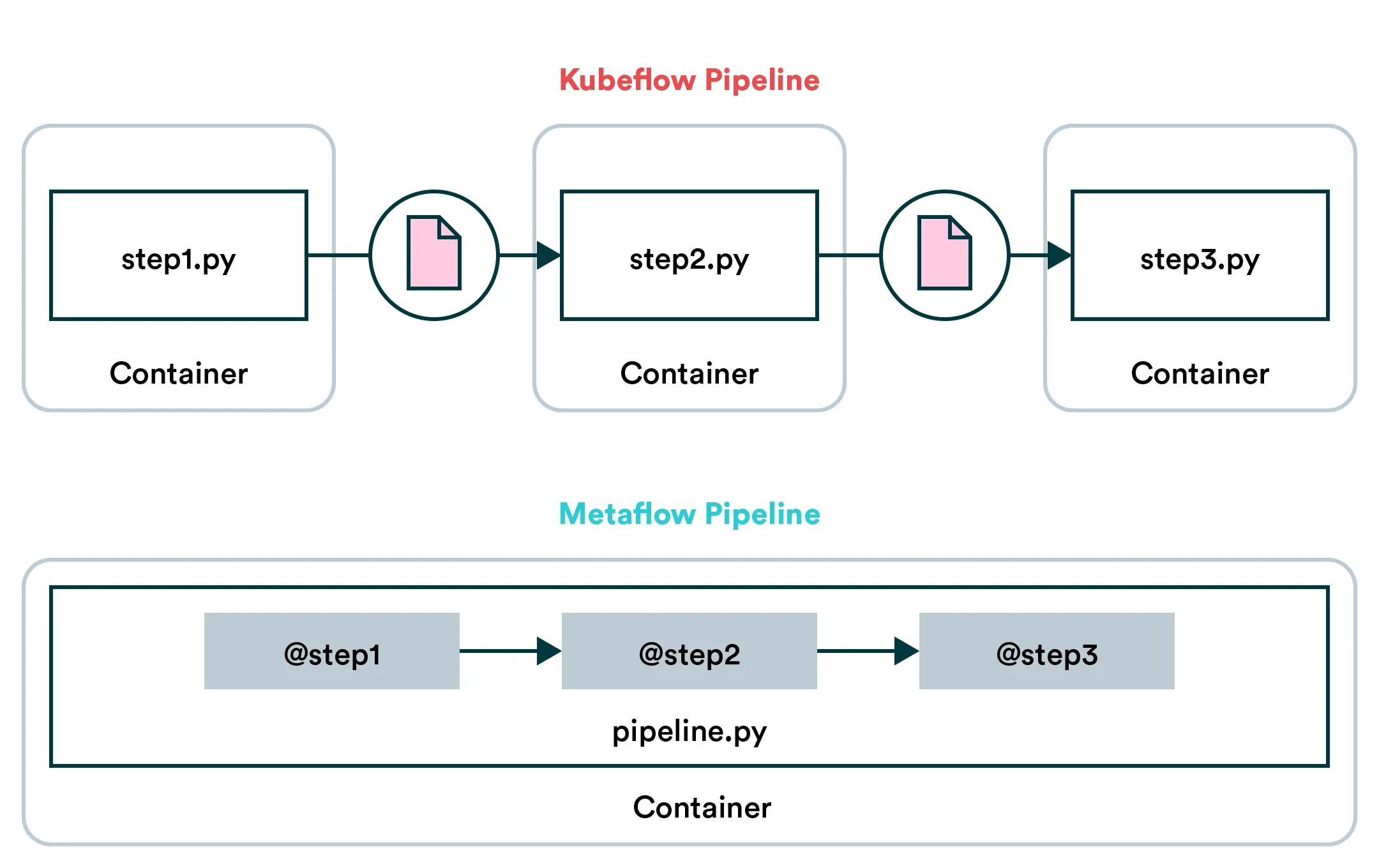
Metaflow’s opinionated approach simplifies building pipelines which makes it easier to adopt than Kubeflow.
Summary
In this comparison between Kubeflow and Metaflow, we highlighted some critical differences that can help you choose between the two platforms.
Suppose you have a large team interested in having a unified workspace where the whole team can experiment and ultimately productize machine learning models. In that case, Kubeflow may be the choice for you.
However, if you are more interested in creating production pipelines and you’ve already got a good set of tools for most things, Metaflow is a far easier choice than Kubeflow. The power of Metaflow is in the fact that it’s approach is opinionated. It may not fit every use case, but when it does, it is powerful and simple to work with.
Also, since Metaflow doesn’t require Kubernetes, the setup may be far easier if you aren’t k8s-savvy.
Valohai as an Alternative for Kubeflow and Metaflow
[CAUTION: Opinions ahead] We are big fans of Metaflow and Ville, who we’ve interviewed previously about machine learning infrastructure at Netflix. For many companies, though, we believe a managed alternative is better than either of the open-source options.

With Metaflow, you’ll likely be looking at building production pipelines with it and supplementing other areas with tools such as BentoML (model deployment) or MLflow (experiment tracking). This may be a good approach as you can adopt these parts as you need them, but ultimately adopting more open-source tools comes with more overhead.
With Kubeflow, you are looking at a hefty setup project that requires plenty of DevOps/IT resources. Kubeflow is a massive system and thus also massively complex, which is the biggest complaint the data science community has about it. Some companies, such as Spotify, have seen success with Kubeflow, but not everyone has the resources of Spotify.
If your objective is to build a full-fledged MLOps stack, both options laid out above are hefty investments in terms of time and effort. The third option you might not be considering is a managed MLOps platform, namely Valohai.
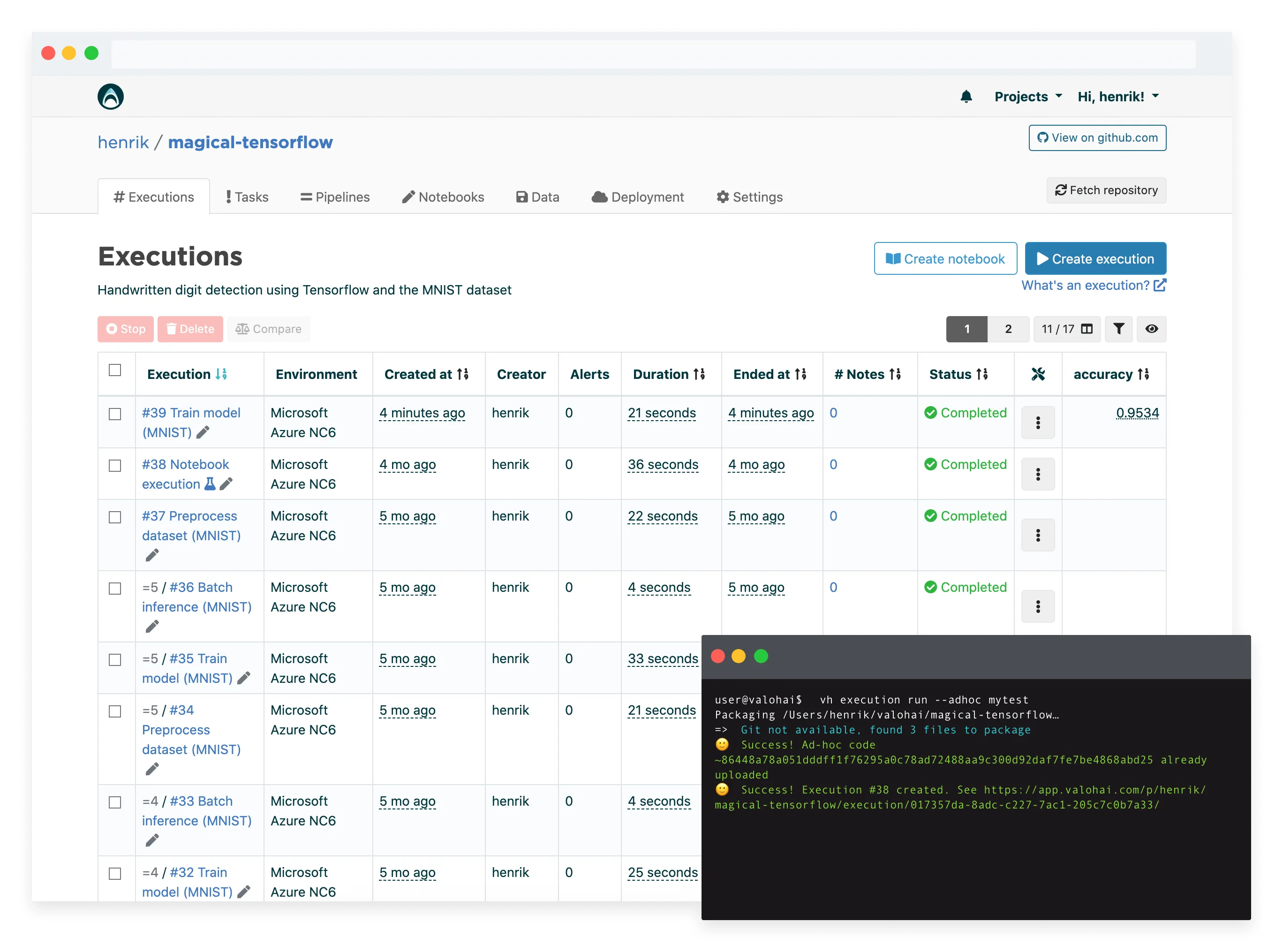
Valohai provides a similar feature set to Kubeflow in a managed service (i.e. you’ll skip the maintenance, the setup and user support). You can run any code, frameworks on most popular cloud platforms and on-premise machines – without Kubernetes.
So if you’re looking for an MLOps platform without the resources of a dedicated platforms team, Valohai should be on your list.

- Valohai Free Trial
- Valohai Product
- Valohai and Kubeflow Comparison
- MLOps Platform: Build vs Buy
- MLOps Platforms Compared
More Kubeflow comparisons
This article continues our series on common tools teams are comparing for various machine learning tasks. You can check out some of our previous Kubeflow comparison articles:
| Other Kubeflow comparison articles |
|---|
| Kubeflow and MLflow |
| Kubeflow and Airflow |
| Kubeflow and Metaflow |
| Kubeflow and Databricks |
| Kubeflow and SageMaker |
| Kubeflow and Argo |