
If you are here, you are probably a data scientist, machine learning engineer, or generally interested in data science projects. As data continues to give intelligence to machines and help us automate repetitive tasks, the tools used to achieve this goal have been increasing rapidly in recent times.
From orchestration tools to MLOps platforms to data management tools and cloud platforms, it is undeniable that the data world is on the move. No team wants to be left behind!
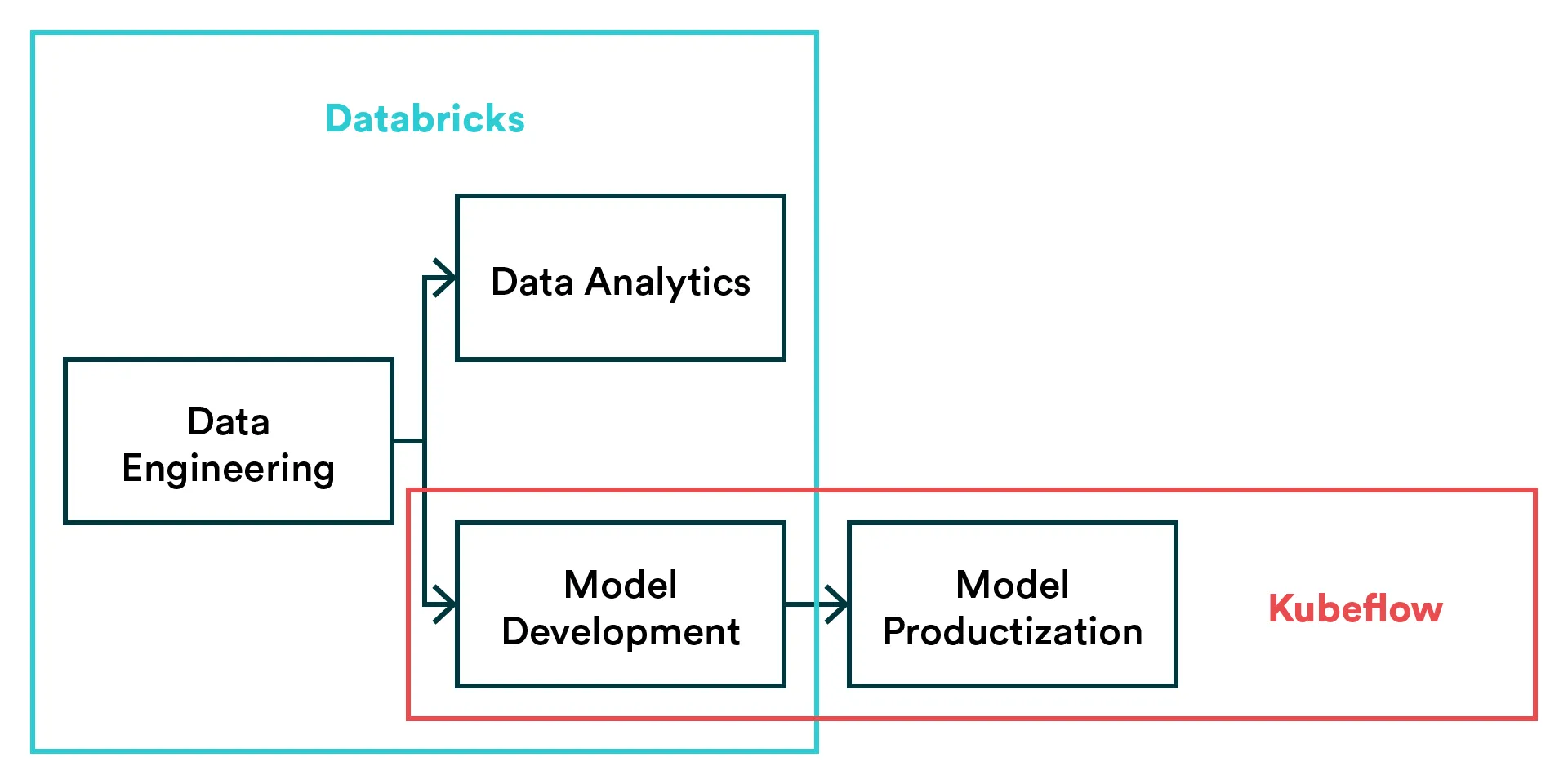
Databricks is a unified data analytics platform, while Kubeflow is an MLOps platform.
The data science scene is still at a point when terminology and the technology stack are still being defined. This often leads to comparisons between technologies that are almost entirely different with only some overlap. Kubeflow vs Databricks is one such comparison.
In this article, we will look at how they are comparable and how they are very different.
Components of Kubeflow
Kubeflow is a free and open-source ML platform that allows you to use ML pipelines to orchestrate complicated workflows running on Kubernetes. This solution was based on Google’s method of deploying TensorFlow models, that is, TensorFlow Extended. The logical components that make up Kubeflow include the following:
-
Kubeflow Pipelines: Empower you to build and deploy portable, scalable machine learning workflows based on Docker containers. It consists of a user interface to manage jobs, an engine to schedule multi-step ML workflows, an SDK to define and manipulate pipelines, and notebooks to interact with the system via SDK.
-
KFServing: Enables serverless inferencing on Kubernetes. It also provides performant and high abstraction interfaces for ML frameworks like PyTorch, TensorFlow, scikit-learn, and XGBoost.
-
Multi-tenancy: Simplifies user operations to allow each user to view and edit only the Kubeflow components and model artifacts in their configuration. Key concepts under this Kubeflow’s multi-user isolation include authentication, authorization, administrator, user and profile.
-
Training Operators: Enables you to train ML models through operators. For instance, it provides Tensorflow training (TFJob) that runs TensorFlow model training on Kubernetes, PyTorchJob for Pytorch model training, etc.
-
Notebooks: Kubeflow deployment provides services for managing and spawning Jupyter notebooks. Each Kubeflow deployment can include multiple notebook servers and each notebook server can include multiple notebooks.
Components of Databricks
Databricks is a cloud-based platform that allows you to perform SQL analytics and BI, data science and machine learning on top of a unified data lake. It was founded by researchers in the AMPLab at the University of California - Berkeley; the same lab that created Apache Spark. The components of Databricks can be categorized in different concepts namely Workspace, Data Management, Computation Management, and Machine Learning. They are discussed as follows:
-
Workspace: This is an environment where you can access all your Databricks assets. It organizes objects like notebooks, libraries, experiments and dashboards into folders and gives you access to computational resources and data objects. A notebook is a web-based interface to documents that contain runnable commands and visualizations. An experiment is the collection of MLflow runs needed to train the ML model.
-
Data Management: This involves all the components that hold the data on which you carry out analytics. The Databricks File System (DBFS) is a core component in this regard. It is a file system abstraction layer that contains dictionaries with files like images, data files and libraries. Another essential component is the Database, which is a collection of information organized to be easily accessed and managed. Finally, Metastore is another equally important component; it stores all structure information of different partitions and tables in the data warehouse.
-
Computational Management: This category contains components like cluster, pool, Databricks runtime and job. Cluster is a set of computation resources on which you run jobs and notebooks. Pool is a set of idle but ready-to-use instances that can help reduce cluster’s starting and auto-scaling times. Finally, Job is a non-interactive mechanism for running a library or notebook immediately or based on a schedule.
-
Machine Learning: This category contains components like experiments, feature stores, and models. A feature store enables the discovery and sharing of features across an organization. It also ensures that the same feature computation code is used both for model training and inference.
Similarities between Kubeflow and Databricks
Though it appears that there is a wide difference between Kubeflow and Databricks, the two still share some similarities.
-
Model Development: Data scientists can use both platforms to experiment and develop machine learning models.
-
Notebooks: The two platforms offer notebooks as a core part of the end-user experience — although, for Databricks, notebooks are perhaps the most important part.
-
Collaboration: They both offer a collaborative environment that empowers data teams to build solutions together.
Differences between Kubeflow and Databricks
Databricks is a data analytics platform for data engineering, machine learning, and data science, while Kubeflow can be classified as the ML toolkit for Kubernetes. The core differences between Kubeflow and Databricks include the following:
-
Data Layer: Databricks focuses on bringing the data layer and exploration under a unified user experience. It focuses on offering a managed notebook environment and data lake in a single platform that can handle projects that span data engineering, AI and data science. Kubeflow, on the other hand, doesn’t try to cover the data layer similarly.
-
MLOps: Kubeflow focuses on productization on machine learning, i.e. MLOps. It is used to create ML pipelines, orchestrate workflows and deploy models. Currently, Databricks doesn’t offer much in terms of productization but rather focuses on exploratory data science and analytics.
-
Open-Source: Kubeflow is an open-source platform that can be installed freely in your own environment. In contrast, Databricks is a managed enterprise platform that some individuals and companies may find expensive. That said, it should be noted that Databricks has created an open-source MLOps platform, MLflow, that you can use to perform some functions like Kubeflow. You can check out a comprehensive comparison between Kubeflow and MLflow here.
-
Kubernetes: Unlike Databricks, Kubeflow is completely built to run on Kubernetes. In practical terms, Kubeflow’s entire existence is based on Kubernetes. The same cannot be said about Databricks though it is good to point out that Databricks recently released Databricks on Google Kubernetes Engine.
Summary
Databricks is an enterprise software created by the founders of Apache Spark. Aside from its enterprise lakehouse platform, Databricks offers some open source platforms like MLflow, Delta Lake, and Koalas that can handle data and ML projects. On the other hand, Kubeflow basically offers a scalable way to train and deploy models on Kubernetes.
If you want a single platform that can allow your team to carry out everything from analytics to AI and data science, and you don’t mind the financial implication, Databricks might be the choice for you. However, if you want a platform to deploy ML workflows on Kubernetes in a portable and scalable way, Kubeflow might be an alternative to consider.
In fact, Kubeflow or other MLOps platform like Valohai are more complementary than comparable to Databricks.
Valohai as an Alternative for Kubeflow and Databricks
[CAUTION: Opinions ahead] If you’re looking for an MLOps platform, Databricks is not it – it’s something different altogether. We also think you can do better than Kubeflow (we’re biased though).

Let’s be clear, Kubeflow isn’t an alternative for Databricks, nor is Valohai. However, suppose your need is to unify how you and your team develop and release machine learning models. In that case, an MLOps platform like Valohai or Kubeflow is more appropriate.
Valohai offers a similar feature set to Kubeflow (experiment tracking, workflow automation, model deployment, etc.) but in a managed MLOps platform. The benefit of this is that you’ll be able to skip the setup and maintenance of the system and receive new features without having to install new packages to your setup. In short, Valohai enables you to move fast with much less engineering and DevOps effort than Kubeflow.
As for Databricks, Valohai complements the data lake and data engineering capabilities of Databricks and makes it easy to build ML pipelines that ingest data from Delta Lake and use it to train a model on cloud GPUs.
Databricks on its own may be sufficient for exploring traditional machine learning models, but when it comes to custom deep learning models, the Spark-based approach may become too limiting. On the other hand, if you are building more complicated ML pipelines, Databricks notebook-based approach quickly becomes another limiting factor. A dedicated MLOps platform can easily tackle these limitations.
So if you’re looking for an MLOps platform that is technology agnostic and has a transparent business model, Valohai should be on your list.

- Valohai Free Trial
- Valohai Product
- Valohai and Kubeflow Comparison
- Valohai and Databricks Comparison
- MLOps Platform: Build vs Buy
- MLOps Platforms Compared
More Kubeflow comparisons
This article continues our series on common tools teams are comparing for various machine learning tasks. You can check out some of our previous Kubeflow comparison articles:
| Other Kubeflow comparison articles |
|---|
| Kubeflow and MLflow |
| Kubeflow and Airflow |
| Kubeflow and Metaflow |
| Kubeflow and Databricks |
| Kubeflow and SageMaker |
| Kubeflow and Argo |