When doing machine learning in production, the choice of the model is just one of the many important criteria. Equally important are the definition of the problem, gathering high-quality data and the architecture of the machine learning pipeline.
This article focuses on architecting a machine learning pipeline for a common problem: multiclass text classification. The pipeline takes labeled data, preprocess it, autotunes a fastText model and outputs metrics and predictions to iterate on.
All the code is available in this Github repository . I use Valohai to create a ML pipeline and version control each step. In the end, you can run the pipeline on the cloud with a few clicks and explore each intermediary result.
How ML in Production Differs from a Kaggle Competition
When competing on Kaggle, you work on a defined problem and a frozen dataset. You have an idea of what a good result is based on the leaderboard scores.
In real-world applications, datasets evolve and models are retrained periodically . For example, in text classification it’s common to add new labeled data and update the label space. Metrics and optimal parameters will change.

Machine learning pipeline components by Google [ source ].
Building a Production-Ready Baseline
In machine learning you deal with two kinds of labeled datasets: small datasets labeled by humans and bigger datasets with labels inferred by a different process.
In practice, training on a small dataset of higher quality can lead to better results compared to training on a bigger amount of data with errors . At least, s maller datasets and simple algorithms are easier to debug and faster to iterate on.
To architect the ML pipeline I use a dataset of 2225 documents from BBC News labeled in five topics: business, entertainment, politics, sport and tech. The dataset assigns a single label for each document, which is known as a multiclass problem.
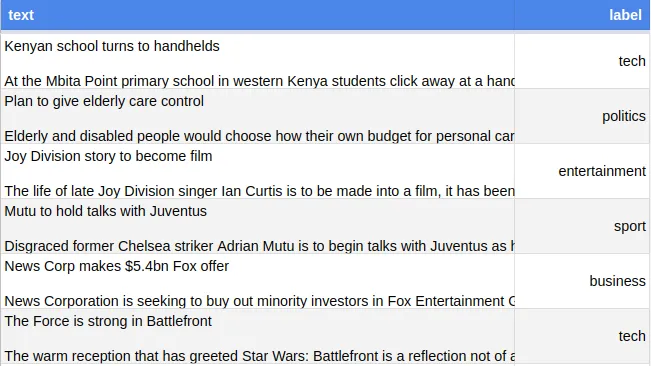
You can run the pipeline on any CSV file that contains two columns: text and label . If you want to train it for a multilabel problem, you can add two lines with the same text and different labels.
Using fastText for Text Classification
Facebook released fastText in 2016 as an efficient library for text classification and representation learning. Some of the benefits reported on the official fastText paper :
- Trains on a billion words in a few minutes on a standard multi-core CPU.
- Classifies half a million sentences among 312K classes in less than a minute.
- Creates subword vectors that are robust to misspellings.
- Includes an easy to use CLI and Python bindings.
In 2019, Facebook released automatic hyper-parameter tuning for fastText that I use as one of the steps in the pipeline.
Integrating ML Code for Production-Level Pipelines
You should start by writing a function for each ML step. Common strategies to industrialize machine learning executions include:
- Command-line interfaces (CLIs).
- Parametrized Jupyter notebooks.
- Decorating functions to integrate with specific ML libraries.
I have a background in web development and data engineering. I am used to writing CLIs and prefer avoiding learning a new pattern for each new practice. To create CLIs I use Click , a popular Python library that decorates functions to turn them into commands.
Integrating fastText with Valohai
I create a command for each ML step. Each command takes data and parameters as inputs and generates data and metrics as outputs . All the code is available on the arimbr/valohai-fasttext-example repository in Github.
For example, the autotune command trains several models on the train split to find the best parameters on the validation split.
View code on GitHubThe get_input_path and get_output_path functions return different paths locally and on the Valohai cloud environment. The train_supervised method accepts arguments to limit the duration of the training and size of the model. The best parameters are saved to later retrain the model on all data.
To execute the autotune command in the cloud, I declare it in the valohai.yaml.
View code on GitHubCreating a Machine Learning Pipeline
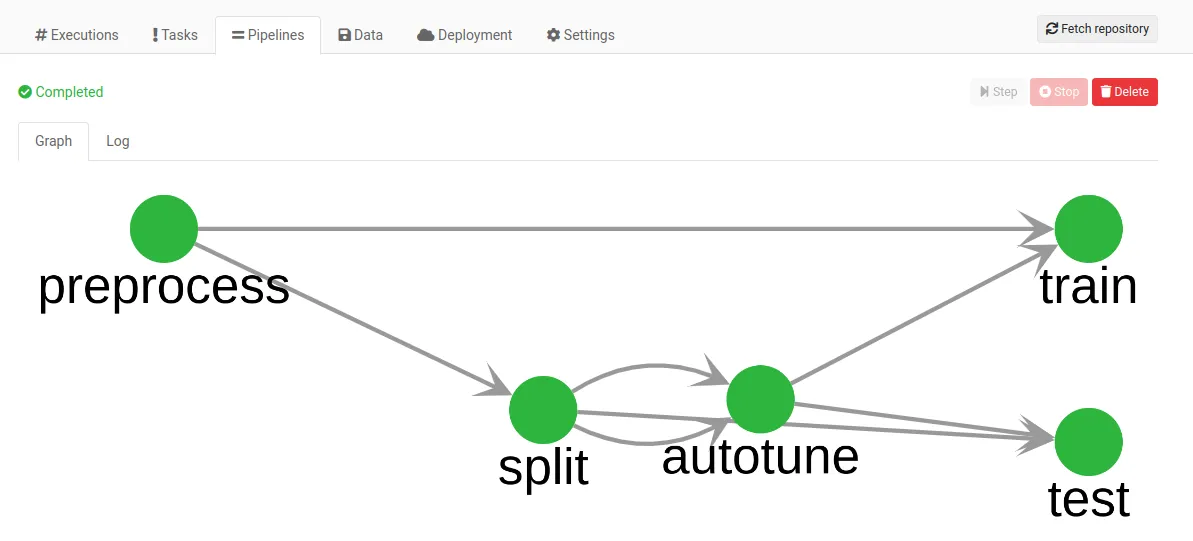
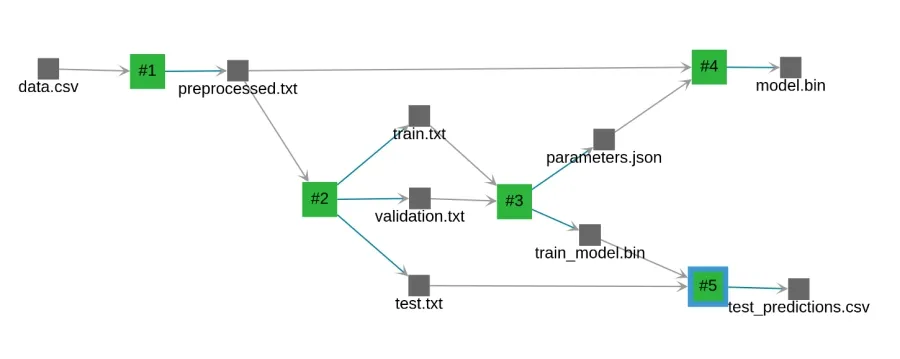
A Valohai pipeline is a version-controlled collection of steps represented as nodes in a graph. Each data dependency results in an edge between steps.
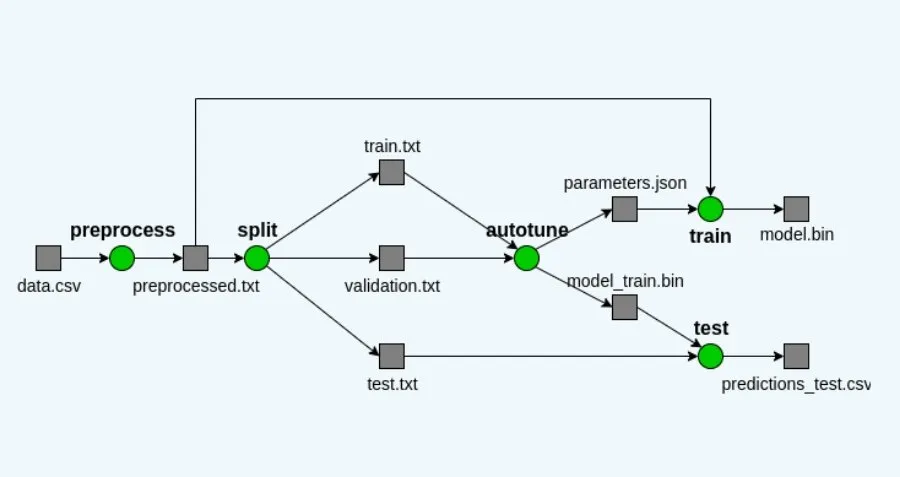
 The text classification pipeline has 5 steps:
The text classification pipeline has 5 steps:
- Preprocess : preprocess the raw data to be used by fastText.
- Split : split the preprocessed data into train, validation and test data.
- Autotune : find the best parameters on the validation data.
- Train : train the final model with the best parameters on all the data.
- Test : get metrics and predictions on test data.
Similar to executions, pipelines are declared in the valohai.yaml file in two sections: nodes and edges.
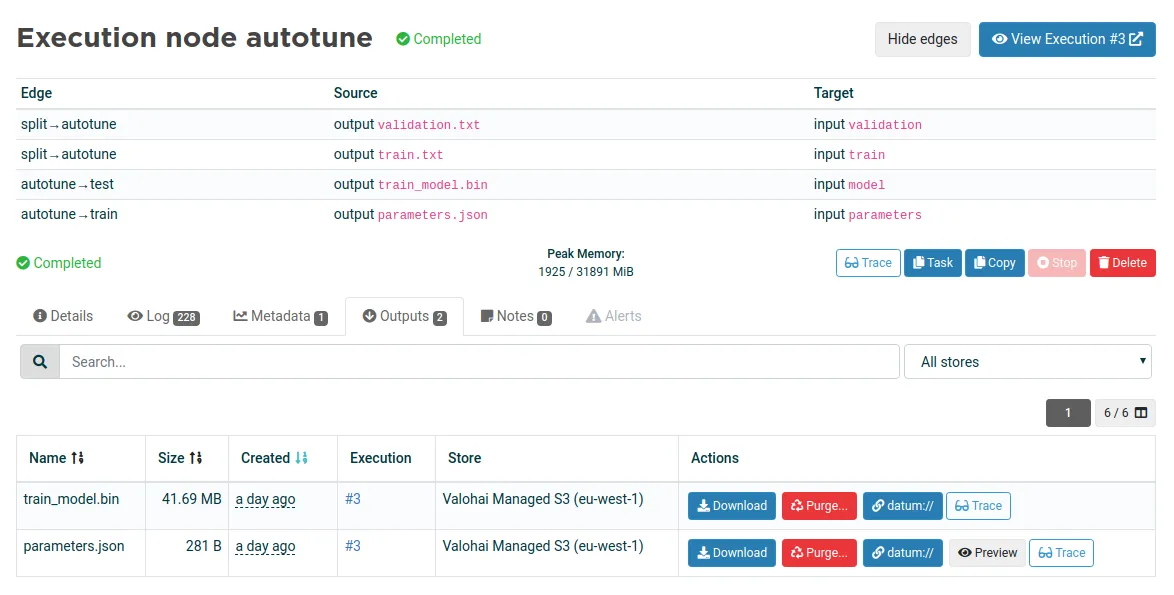
View code on GitHubOnce you have declared a pipeline, you can run it and inspect each pipeline node by clicking on it. Below you can see the details of the autotune node.
 Valohai pipelines are declarative, making it easy to integrate with your code. If you require dynamic pipelines you can integrate Valohai with Apache Airflow .
Valohai pipelines are declarative, making it easy to integrate with your code. If you require dynamic pipelines you can integrate Valohai with Apache Airflow .
Tracking Data Lineage Automatically
The data lineage graph displays the data dependencies between executions and artifacts. In Valohai, you can trace each dependency to debug your pipelines faster.
Iterating on the problem, data and model
The autotune step was key to achieve good results. The F1-score went from 0.3 with the default parameters to a final F1-score of 0.982 on the test dataset . Intermediary results are logged by the fastText autotune command and can be read in the Valohai logs. The final score is logged in JSON and stored by Valohai as an execution metric.
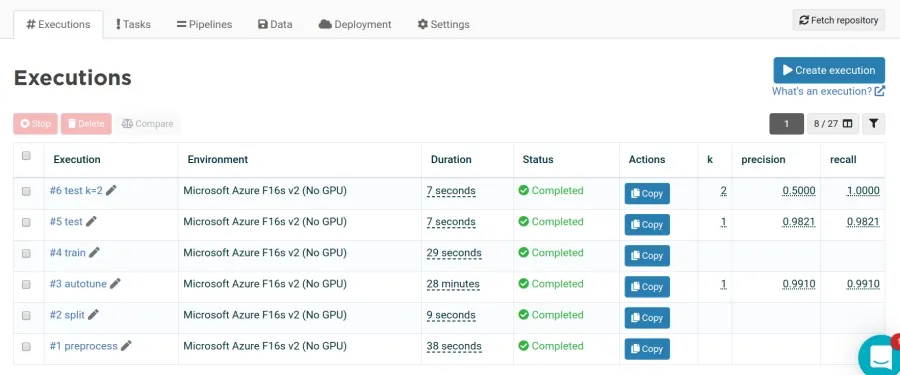 But only looking at a metric is not enough to know if your model works well . The most interesting information is in the test_predictions.csv file. It contains the 4 errors made by the model on the test dataset of 222 records.
But only looking at a metric is not enough to know if your model works well . The most interesting information is in the test_predictions.csv file. It contains the 4 errors made by the model on the test dataset of 222 records.
 The 4th error assigns a higher probability of 0.59 to the business label than the politics label with 0.39. Exploring the whole text reveals that the article talks about both topics. That observation may lead to iterating on the problem to become multilabel and assign all labels above a probability threshold.
The 4th error assigns a higher probability of 0.59 to the business label than the politics label with 0.39. Exploring the whole text reveals that the article talks about both topics. That observation may lead to iterating on the problem to become multilabel and assign all labels above a probability threshold.
Overall, the labeled data is of high quality. We could argue that some of the errors with higher p@1 are corrections to the labeled data. In another dataset with labeled data produced by a different process, the model predictions can be used to correct the labeled data .
If the final metrics are not satisfactory for your business case, new features can be added and a different model trained . But I would argue that is better to start with getting the problem and data right. Those are the ingredients of your ML pipeline.
Trying fastText on your own dataset with Valohai
It’s easy to run the pipeline yourself. The following button will invite you to register/login to your Valohai account and create a project to try this pipeline.
After you have created a new project, to run the pipeline on the default data:
- In the Settings tab > General tab, set the default environment to: “Microsoft Azure F16s v2 (No GPU)”.
- In the Pipeline tab, create a pipeline and select the blueprint: “fasttext-train” .
- Run the pipeline by clicking on the “Create pipeline”.
- While the pipeline is running, you can click on each node in the graph and explore the logs and outputs.
- When the pipeline is completed, you can click on a node and get the data lineage graph by clicking on the “Trace” button.
Congratulations, you’ve run your first ML pipeline! You can now try it with your own data to get a baseline for your text classification problem.
To run the pipeline on your own data:
- In the Data tab > Upload tab, upload your dataset. The dataset should be a CSV file with two columns: text and label.
- Before running the pipeline, click on the preprocess node. In the inputs section, replace the default input data with the data uploaded in step 1.
- Run the pipeline by clicking on the “Create pipeline”.
Conclusion and next steps
Organizing your ML code in multiple steps is important to create machine learning pipelines that are version controlled and easy to debug. CLIs are a popular choice for industrializing ML code and easy to integrate with Valohai pipelines.
For common problems such as text classification, fastText is a powerful library to build a baseline fast. With Valohai you get a version-controlled machine learning pipeline you can run with your data.
In the following article, I’ll add the extra steps to test the ML pipeline before releasing a new version and monitor the model predictions.