
This article was written by Xavier Moles Lopez and originally published here. Xavier is a senior data scientist and technical leader at Qim info in Switzerland. He has more than 10 years of experience implementing and leading Data and Analytics projects in multiple sectors.
Why a Machine Learning model is not a product if there is no MLOps.
In a previous post, we described the steps we took to implement a machine-learning solution to improve our core business. As a quick reminder, our goal is to help our colleagues from the recruitment department in their quest to find good candidates given a job description, which we formalized as follows:
“Recruiters want a system that takes a job description as input, and orders the CVs from our database by relevance”
Formulated in this way, the problem essentially boils down to a “sort by similarity”, which can be solved by constructing an adequate representation of the documents in a vector space.
In this post, we will describe the algorithm we chose to compute that similarity, why we chose it, and how we trained and evaluated it’s performance. However, training the model is only one of the many steps involved and we can confidently state that it is probably the best documented step.
Therefore, we will focus on the step 4 at the junction between the Implement and Operate stages of the MLOps cycle and expose our approach to implement the training as a reproducible process, and how this process intertwines with our CI/CD pipeline.
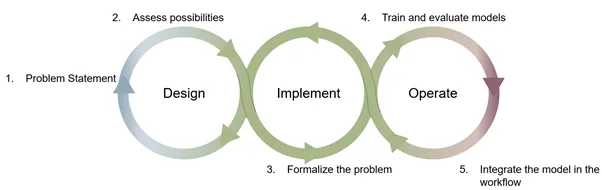
Figure 1: Mapping of the 5 steps presented to the MLOps cycle; Image by Author inspired by ml-ops.org
{kind=link}
It’s time to get our hands dirty!
Choosing an Embedding method
Among many, a very popular method of evaluating document similarity relies on word embeddings. In order to pick one of the several embedding algorithms that exist, we started by looking at our data, exclusively made of text extracted from CVs: sentences were very short, and many did not even contain verbs (e.g., lists of competences). Furthermore, the layout in a CV is very important, i.e., the content doesn’t necessarily speak for itself. In addition to the fact that CVs are not really written in “natural language”, they also contain many terms that are not “in the dictionary”, such as C#, .NET, BABOK, or CISSP.
Because of those two characteristics, we considered training a model from scratch. However, the size of our dataset was relatively small in terms of number of sentences, which is why we did not jump on large models such as those based on Transformers, but rather looked at more classical word-embedding representations. Among those, we picked Stanford’s GloVe word vector representation because of its construction based on the word-word co-occurrence count matrix [1], which we considered better suited to situations like ours where the text content is not made of “natural” sentences (lists of technologies, competences, or experiences).
The embedding pipeline
Unlike other embedding methods, GloVe requires the computation of a word-word co-occurrence count matrix (which will refer to as “co-occurrence matrix” for brevity). The co-occurrence matrix relies on the counting of words, which itself relies on the tokenization/text pre-processing stage (what do we consider as a “word”). Which can be summarized graphically as follows:
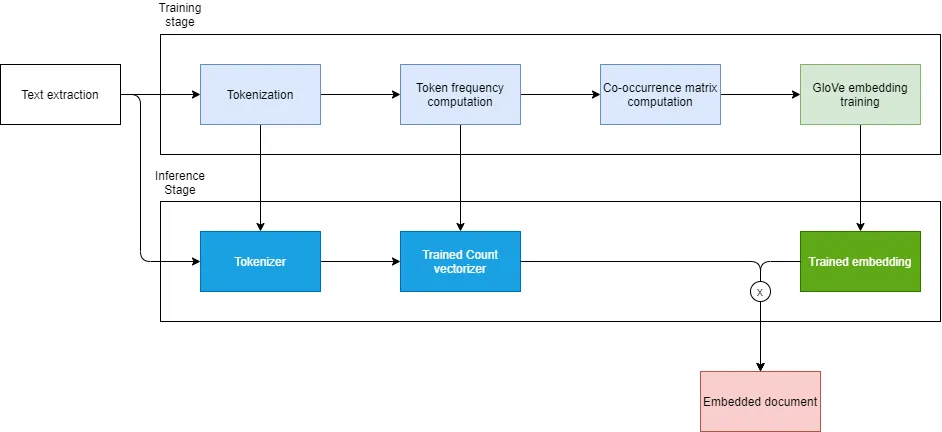
Figure 2: Steps of an embedding pipeline. Pre-processing steps are shown in blue and embedding step is shown in green. Produced artefact are shown in vivid colors. Image made by the author.
During the training stage, we divided the pipeline in two parts: the pre-processing stage illustrated in blue, and the embedding stage illustrated in green. Both pre-processing and embedding stages have hyper-parameters that may affect the results of the “sort by similarity” function we ultimately aim to build, and that is based on the cosine similarity between embedded document vectors, illustrated in red.
In order to evaluate the ranking produced using the cosine similarity distance on the embeddings that we just trained, we applied the Mean Average Precision and more generally the Mean Precision as described in the excellent article by Moussa Taifi [2].
Experiment tracking
Because there are many hyper-parameters and combinations thereof, we need an experiment tracking mechanism.

One of the go-to solution for experiment tracking is MLflow. Once that you have setup a server and a database, which is a must if you wish to collaborate on the creation of models, you can log the results of your experiments using their API. Many resources exist about how to setup and use MLflow for experiment tracking, and a very good summary was made by Quantum [3].
MLflow was a good solution when the objective was mainly to obtain a satisfying model for a PoC and helped us reach the target after only a few weeks of work. However, in order to apply our setup to a larger dataset and to a larger set of hyperparameters, it exposed us to a challenging issue: the API proposed by MLflow to track experiments is interfaced in such a way that the code which manages the tracking of models’ performances is the same than the code which manages the training. In concrete terms, this means that specific MLflow code needs to be added inside your training loop to benefit from the tracking.
This way of passing training outputs through the tracking API has two consequences:
1. It induces tight coupling between pre-processing and training steps.
The current API of MLflow does not embrace well the concept of pipeline (1). This limitation makes the tool not quite adequate for cases where the pre-processing stage has such a large impact on the results. In those cases, experiments must be designed so that they span the whole pipeline, hindering modularity. Solving this shortcoming requires developing a lot of custom code in order to reuse intermediate results of the pipelines and often ends up breaking the lineage of the results, ultimately making the deployment of so trained models difficult.
2. Training and evaluation scripts need to be adapted to enable the tracking.
Although it may be seen as a good practice to start your ML project with tracking in mind, you may want to train a model implementation from GitHub or elsewhere for comparison purpose, and that project may not be using MLflow. Henceforth, you must modify, build, and possibly maintain a fork of that other project for the time of your experiments.
Alternative solutions to scale-up the infrastructure: MLOps
Having not only these limitations but also our need to scale-up in mind (both in terms of data ingestion capacity and of ability to try different model architectures), we decided to test two alternatives: Kubeflow and Valohai.
Kubeflow is the most present of the two solutions. It relies heavily on Kubernetes and the fact that it embraces the concept of pipeline better fits our need of modularity. However, Kubeflow is more difficult to setup than MLflow and still suffers from the fact that its definition of pipelines relies on the use of an SDK (based on decorators), which makes code updates mandatory in order to manage training flows.
On the contrary, Valohai is a SaaS solution, hence very easy to setup. The pipelines are defined as steps in a dedicated YAML file (valohai.yaml) where you specify commands to be executed in Docker containers. In our case, the containers needed to run on a server configured with two high-end GPUs on-premises; the configuration to add our on-premises machine to the management interface of Valohai as a worker was very easy.
![]()
Valohai’s value proposition. Image source
Valohai also comes with a very intuitive CLI, which enabled us to fully automate the Continuous Integration process by linking our version control system (Gitlab) with Valohai and triggering events based on merge requests.
If you’re curious about what it takes to track a machine-learning project with Valohai, we prepared a public Github repository: the steps and the pipeline are defined in the valohai.yaml file, and execution of vh(Valohai’s CLI) are given in the README.md.
Hyperparameter tuning
Hyperparameters influence the output of each step of the pipeline, and consequently influence the final output of the pipeline. Similar to Kubeflow’s Katib, Valohai proposes a hyperparameter tuning component helping us to find the best hyperparameter values for each step of the pipeline. There are basically two search modes available: grid search and Bayesian optimization.
One current downside is that the range of values has to be specified in the Web UI, and therefore requires manual intervention, or by using Valohai’s REST API, at the expense of additional code. Ideally, this range could be provided in the valohai.yaml file, similarly to multistep definitions in MLflow (1).
In terms of parameter tuning, one extremely useful feature of Valohai is Tracing, which enables to analyze execution lineage visually. For example, in Figure 4, we see that pipeline 30 is constituted from executions #156 and #157, that these executions originate from commit 905a491dd5, that execution #156used a pickled glove embedder as input and then outputted the file embedded_cvs_labeled_df.json, which in turn was used as input for execution #157.
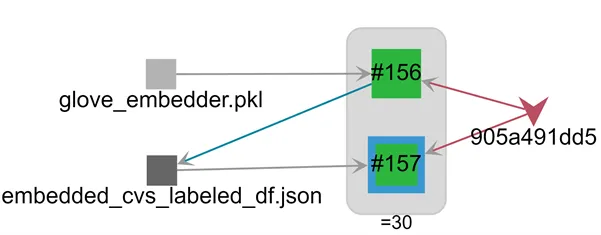
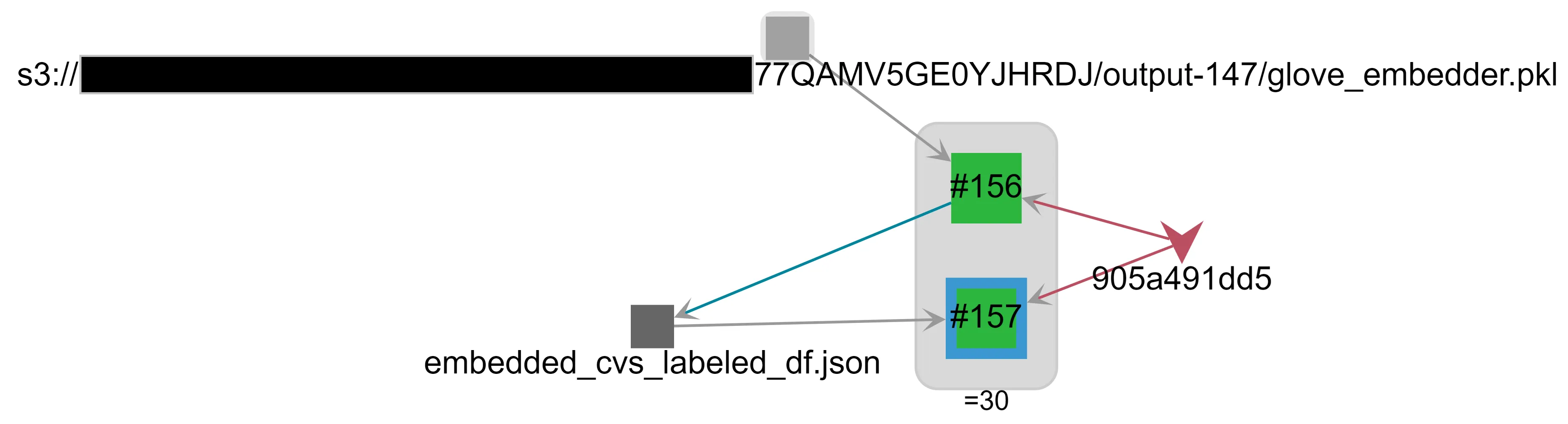
Figure 4: Visual information provided by the tracing module. Above: the simplified lineage information for pipeline 30 (description in the text). Below: hovering on the “glove_embedder.pkl” node shows were it comes from.
CI: Pipeline automation
As mentioned earlier, there is more to a model than the training: you need to add preprocessing methods, evaluation metrics, the boilerplate to manage the execution of related experimentations and the serialization of the model, and of course, the unit-tests. Needless to say, all this code is subject to change.
After having achieved a first PoC, we needed to optimize various steps to cope with the increased volume of data to build the final model, leading us to change some implementations to make good use of our on-premises GPUs.

Time to adapt the code to make good use of that hardware.
At this point, having a reliable way to run our experiments and integrate them in our CI/CD pipeline was more than a nice to have. In this regard, Valohai’s CLI was an extremely useful feature: it allowed us to simply run a few commands in Gitlab’s runner in order to update Valohai’s project and run the newly built docker images containing the latest code’s version and its dependencies on our on-premises ML rig!
In Figure 3, we illustrate our CI/CD pipeline based on 2 branches, the valohai branch, which triggers new runs of the training pipeline, and the master branch, which triggers the packaging and deployment on UAT environment for each new merge (and on PRD environment for each new version tag).
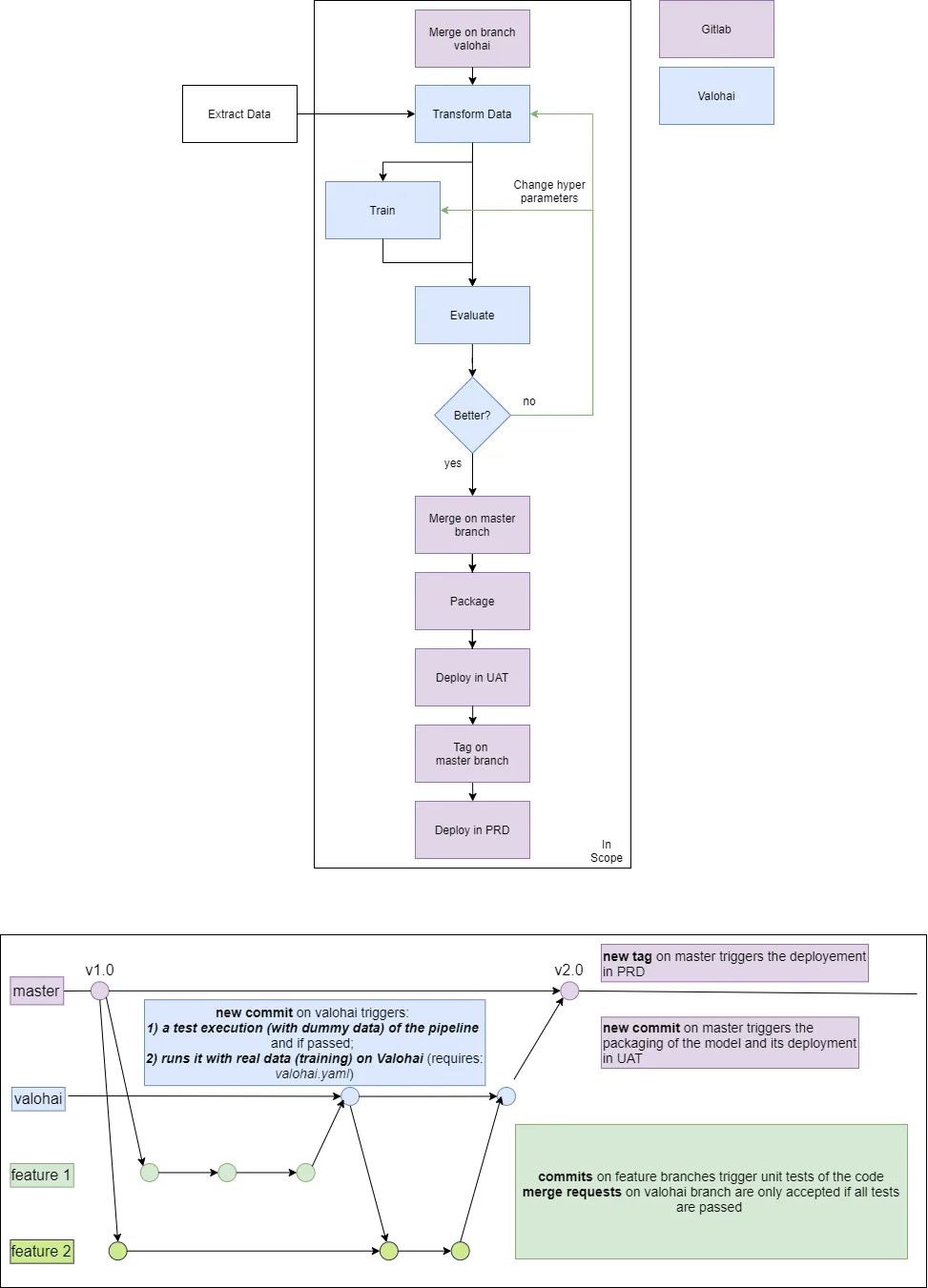
Figure 3: Above: CI / CD pipeline interconnecting Gitlab and Valohai. Below: steps of the CI/CD pipeline mapped to git events. Image made by the author.
An important thing to note, is the ability to perform ad-hoc execution on Valohai, which sends a local copy of the code to be executed on worker host without the need to push. This can be extremely handy when developing the training pipeline itself or testing some optimizations.
CD: Automated packaging and deployment
Even if Valohai offers an easy solution to deploy models, the deployment happens in a Kubernetes cluster, which can be managed by Valohai or yourself. As a reminder from our previous post, the purpose of our model is to be integrated in a business application managed internally. Therefore, it was easier for us to export and package the best performing model using an alternative tool, namely BentoML, with which we already had prior experience.
BentoML, which presents itself with the appealing statement of “Model Serving Made Easy”, is a library that really shines in packaging and deploying model to a variety of target infrastructures, such as Docker Container, AWS lambda, AWS ECS, Azure Function, and many more. Because we expect this pattern to be frequent for, e.g., deploying a model to a client’s network, we took the time to integrate BentoML into our CI/CD pipeline. The following snippet show how the code to retrieve the best model from Valohai and packaging it happens using BentoML framework.
View code on GitHubAfter packaging, we can deploy the model to one of the different targets proposed by BentoML. In our case, we used the Dockerfile generated by BentoML, and then built the image using Kaniko (for security reasons). The deployment to our AWS-based Kubernetes cluster is done via helm charts triggered by the Autodevops functionality of Gitlab that was properly configured by the DevOps team of Qim’s Center of Expertise.
Conclusion
Even when you are dealing with “simple” models, complexity augments rapidly with the number of pre-processing steps. Managing efficiently the different steps involved in the design and training of a model is an important building block for reproducible experimentation. Furthermore, a solution that preserves traceability even when reusing artefacts from older runs helps improving the pace of iterations.
Without these capabilities, building and maintaining a product based on machine learning in a collaborative, reproducible, and traceable way becomes really cumbersome and is nearly impossible in an ever-changing team such as ours. Of course, you can easily deliver a model, but auditing it and continuously improving it based on user feedbacks is a never-ending process that can only be sustainable if you have some level of automation and embrace MLOps practice.
We tested several solutions during our Proof of Concept: MLflow, Kubeflow, Valohai and BentoML each with their strength and weaknesses. Since our goal was to create a pipeline that would fit into our existing landscape for ease of maintenance, and still be generic enough to be used with our customers without loss of automation, we picked the tools that felt better suited for that goal.
The ability to link all the pieces together: code versioning, unit-testing, training, evaluation, packaging and deployment is not straightforward and requires mastering many of these tools. However, depending on your setup it may be possible that other tools are more integrated or covering a broader scope, which could ease this process. The solutions presented here are being actively developed, and some are still in beta at the time of writing this article. Therefore you might want to verify the status of these products before making your call.
Conflicts of interests disclosure
Qim info S.A. is not Valohai’s affiliate. The experimentations reported in this article were conducted during the trial period of Valohai’s MLOps platform.
Notes
(1) Multistep workflow capabilities do exist in MLflow, though it’s a more advanced feature. A good example of its usage can be found here. However, even though it reduces the coupling in the code, it does not yet offer the same level of abstraction as pipelines. A quick look at the main.py file, the script file responsible for gluing all the steps, shows that it is mainly made of boilerplate code needed to deal with orchestration, retries and so forth.
References
[2] Moussa Taifi, MRR vs MAP vs NDCG: Rank-Aware Evaluation Metrics And When To Use Them (2019)
[3] Quantum inc., Tracking Experiments with MLflow (2020)
Thanks to Julien Ruey.