
Machine learning operations (MLOps) has only just become a widely recognized concept — albeit not necessarily widely understood or agreed upon. But if you’ve been in tech for long, you know the next new abbreviation is already buzzing behind the corner.
DLOps, deep learning operations, is an evolution of MLOps, looking to answer the unique operational challenges that deep learning sets. A skeptic may look at it as unnecessarily muddying the waters with a new buzzword, but it may be valuable to look at the reasoning behind how DLOps might diverge from MLOps.
For that, we should start by looking at the difference between machine learning and deep learning.
Differences between Machine Learning and Deep Learning
Deep learning is a concept within machine learning that involves deep neural networks.
Generally speaking, the significant difference between deep learning and traditional machine learning is that deep learning can solve problems where feature engineering is complex or impossible (most commonly, structured vs. unstructured data).
Let’s say you want to distinguish between sharks and dolphins. If you have tabular data about the animals, it’ll be easy for you to figure out that the weight, length, and perhaps a weight-to-length ratio are essential information. On the other hand, if you have a collection of pictures, it is much more difficult for you to decide which pixels, shapes, colors, etc. are essential information. In these cases, deep learning is preferred as “feature engineering” is left for the machine.
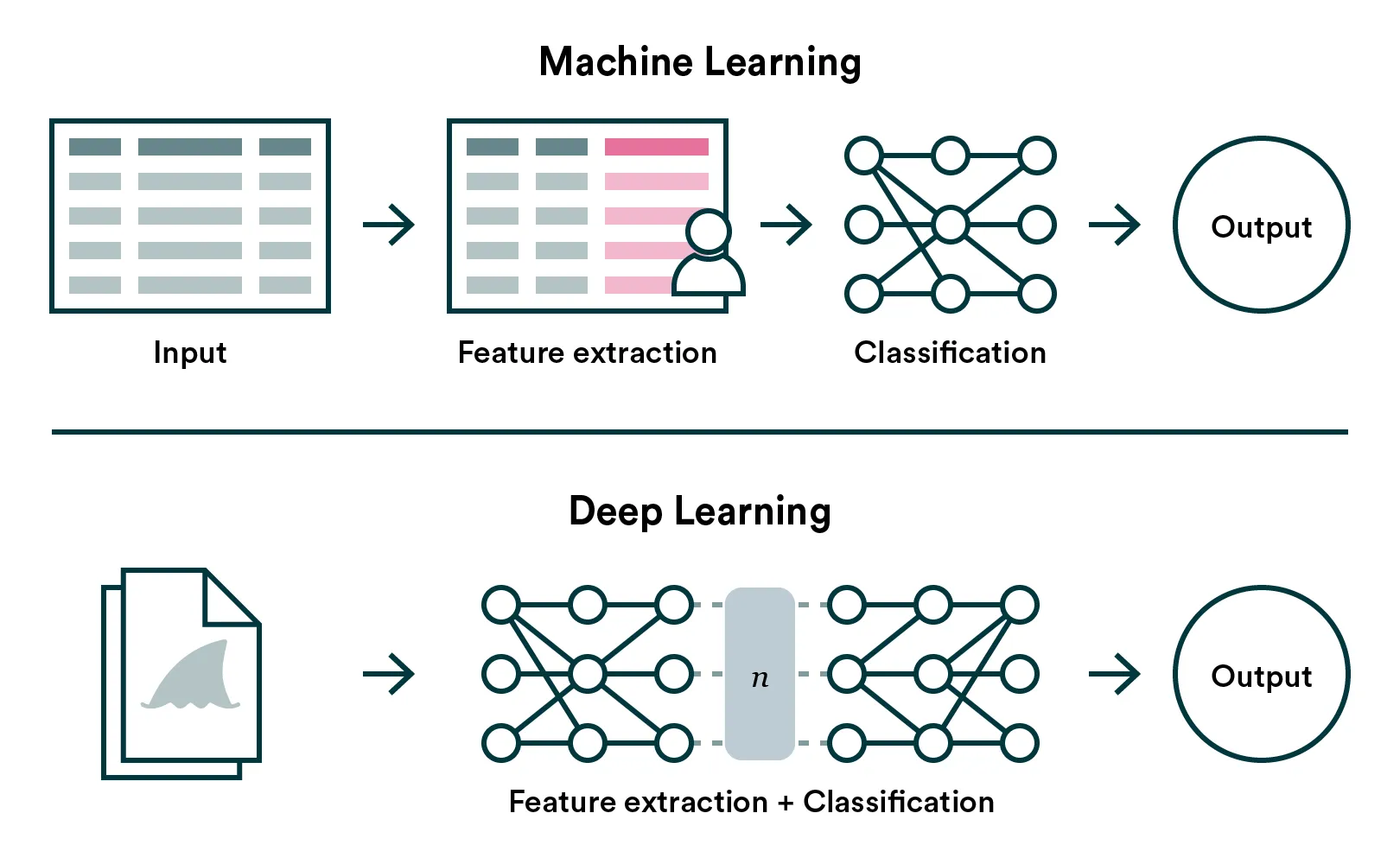
It’s safe to say that deep learning models are larger and tend to be more custom than traditional machine learning models. In addition to that a deep learning model often work in tandem with other deep learning models, making the model architecture and training pipelines much more complex.
This is not because of deep learning itself but rather that it is mainly applied to scenarios involving complex problems, such as natural language processing, speech recognition, and computer vision.
DLOps vs. MLOps
Back to the original topic, DLOps. Machine learning operations (MLOps) serves as an umbrella term for the processes and tools used to develop, release and maintain machine learning capabilities. So are deep learning models (compared to others) any different to develop, release and maintain?
Mostly, no. The same best practices tend to apply. Versioning everything from data, code and parameters is equally essential, and automating the workflow will yield similar benefits. There are, however, at least three areas in which deep learning puts its own unique spin:
-
Data infrastructure: Data processing and management may be entirely different. Most of the data space is focused on solving problems in structured data. For example, feature stores (which are all the rave in MLOps) are irrelevant for deep learning.
-
Training infrastructure: Training simple machine learning can be done with relatively small data and quickly on CPUs. On the other hand, deep learning involves large amounts of large files (such as images) and therefore requires much more computing power and/or time.
-
Model serving: Real-time online inference is a common paradigm for serving many machine learning models. For deep learning models, this paradigm can be either more difficult to implement or completely invalid. For example, face recognition should happen on edge to ensure functionality even with poor internet connectivity.
When building a technology stack for deep learning, your decisions may be different from someone working with traditional machine learning. For example, parallelization and GPU machines may not ever be relevant for machine learning, but they are helpful in developing deep learning from day 1.
On the other hand, certain technologies almost de facto for traditional machine learning (and structured data), such as AutoML and Spark, aren’t really utilized to develop deep learning models.
So is there enough of a difference to warrant new terminology? Probably not, but time will tell.
DLOps and Valohai
Valohai was originally built for deep learning in mind. We identified that access to compute resources was a significant stumbling block for data scientists working on deep learning. Therefore we put a considerable emphasis on machine orchestration. Today, we still see that flexibly utilizing the most powerful and most cost-effective machines is more valuable for deep learning use cases.
However, rather than positioning ourselves as a DLOps platform, we consider Valohai the best platform for teams building custom models. We emphasize technology agnosticism, machine orchestration, and automation for all use cases.