You might have heard that every individual subject to automated decision making by machine learning models has a right to an explanation of the result. I bet you feel drops of sweat forming on your forehead when you receive an inquiry from a manager saying that he needs details about how a certain decision was made. If thinking about this scenario gives you chills, you are in the right place. Read further and learn how to tackle the transparency issue.
What does the GDPR say about decisions made by machine learning?
There are a couple of sections in the General Data Protection Regulation to be aware of before going further.
Give meaningful information about the logic involved
Chapter 3; Section 2; Articles 13-15
The third chapter’s second section is about the rights of the data subject and each article covers different aspects of rights. Creators of AI applications, or data controllers as they are referred to in the GDPR, need to give information about the existence of automated decision-making, including profiling, and about meaningful information about the logic involved . This exact wording is used in each of the three articles.
Right to opt out
Chapter 3; Section 4; Articles 21 and 22
Briefly put, Article 21 describes data subjects’ rights to object to the processing of personal data. Article 22 describes the right not to be the subject to a decision based solely on automated processing, including profiling, which produces legal effects concerning him or her or similarly significantly affects him or her .
You need to consider if the model that you are working with produces legal effects that significantly affect the individual. While in a sense suggesting routes or restaurants affects an individual’s decisions, it does not obligate giving an explanation of the automatic decision making. For example, assessing an option for parole, making insurance decisions or recruitment is covered by these Articles.
“Candidates need to be informed if automated decision making, e.g. rejecting candidates automatically without human interaction, is used in recruitment”, says a virtual recruitment assistant TalentAdore ‘s Miira Leinonen.
Summary of the Articles concerning Machine Learning
These articles together mean that an individual(i.e. data subject), must
- be aware of automatic decision-making,
- have the right to gain information about the logic behind the machine learning model, and
- be able to deny the usage of automated decision-making for her,
if the machine learning models produce legal effects that significantly affect the individual.
GDPR says that an individual must have right to gain information about the logic behind the machine learning model and deny the usage of automated decision-making for her. — Click to tweet
What does “The logic behind the machine learning model” mean?
While the regulation does not clearly answer this, Recital 71 gives some pointers describing that in automated decision-making the data subject, a person, should have the right to obtain an explanation of the decision reached after such assessment and to challenge the decision.
It seems that the clarification for the transparency of the decisions is included in a non-binding part of the GDPR text because it is understood that it may be very hard to lay out how a certain decision was achieved. Are you able to explain how your model comes to a certain conclusion?
Especially when working with complex deep learning models, I bet that we agree, that it is impossible to track back the exact chain of reasoning. Instead, the binding Articles give more room for interpretation and AI application creators need to be able to transparently prove the the logic that caused the decision, not the explanation of exact chain of reasoning that happened inside the model.
Proving the logic of a deep learning model is not trivial
What is enough information for proving the logic behind a model? I believe that this will be clarified only after the first court case.
Meanwhile, there are best practices for data scientists to make sure that enough information of machine learning executions are stored. In some cases, the model might change rapidly and there are multiple variables that can vary between models. As a data scientist, you need to take responsibility of your and your team’s work, and be able to exactly tell which model was in production at the time of decision. A request from a customer about the logic behind the model might come months after the decision made and every team member needs to be able to trace what was done with the specific model.
There are various different things to store in each step of a machine learning experiment.
Input
- Training code
- Parameters
- Data set
Execution
- Used hardware
- Environment
- Experiment cost
Output
- Model
- Logs
- Results
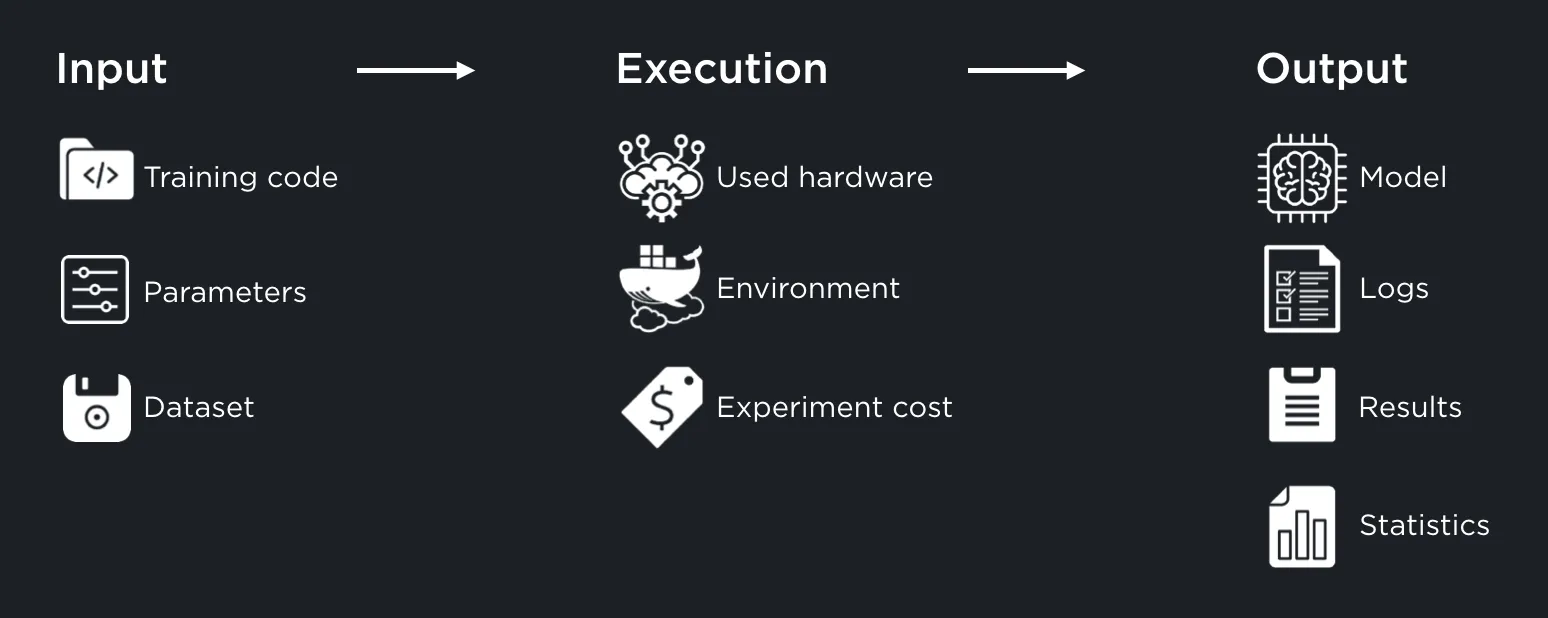
Experiment cost isn’t relevant from GDPRs point of view but it is arguably an important detail to store. Read more about the reasoning why each of these aspects need to be stored from our previous blogpost What to Store from a Machine Learning Experiment .
Regardless if you use a platform such as Valohai for automatically tracking your every experiment, or do it manually – in order to comply with GDPR you need to have full traceability and a waterproof audit trail for every experiment. Handmade jots in an excel sheet are not enough.