
Let me preface this article by saying there isn’t a single accepted definition of a machine learning lifecycle. Most articles about the machine learning lifecycle tend to focus only on a small portion of the actual lifecycle: the Experimentation loop.
Typically a machine learning lifecycle is described (simplified):
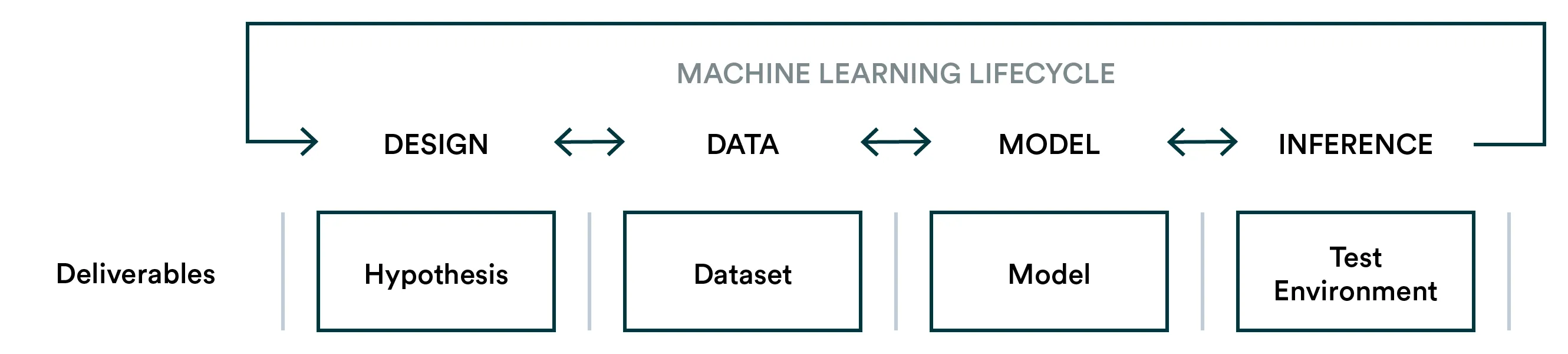
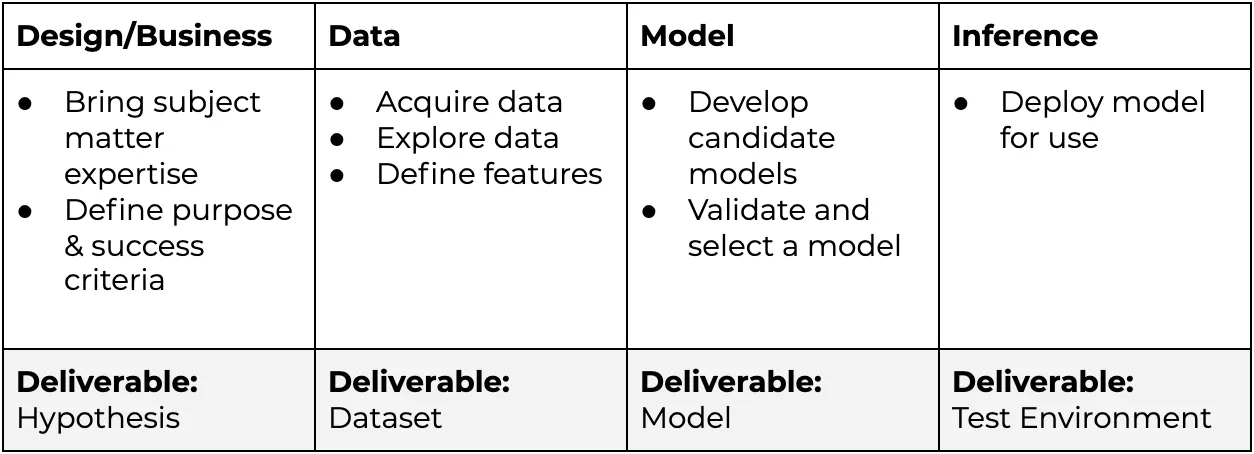
A diagram 👆 and table 👇 of a typical Machine Learning Lifecycle
Many practitioners approach machine learning from a research perspective where the purpose is to prove machine learning as a solution for a problem. However, establishing a worthwhile solution (i.e. Experimentation) is only the first milestone in applied machine learning.
Experimentation and productization are both part of the model lifecycle
For this reason, the machine learning lifecycle should look further and consider Productization as the second significant milestone.
-
Experimentation: Develop an algorithm that fulfills the business hypothesis.
-
Productization: Take the learnings from Experimentation and build a system that will continually drive business value.
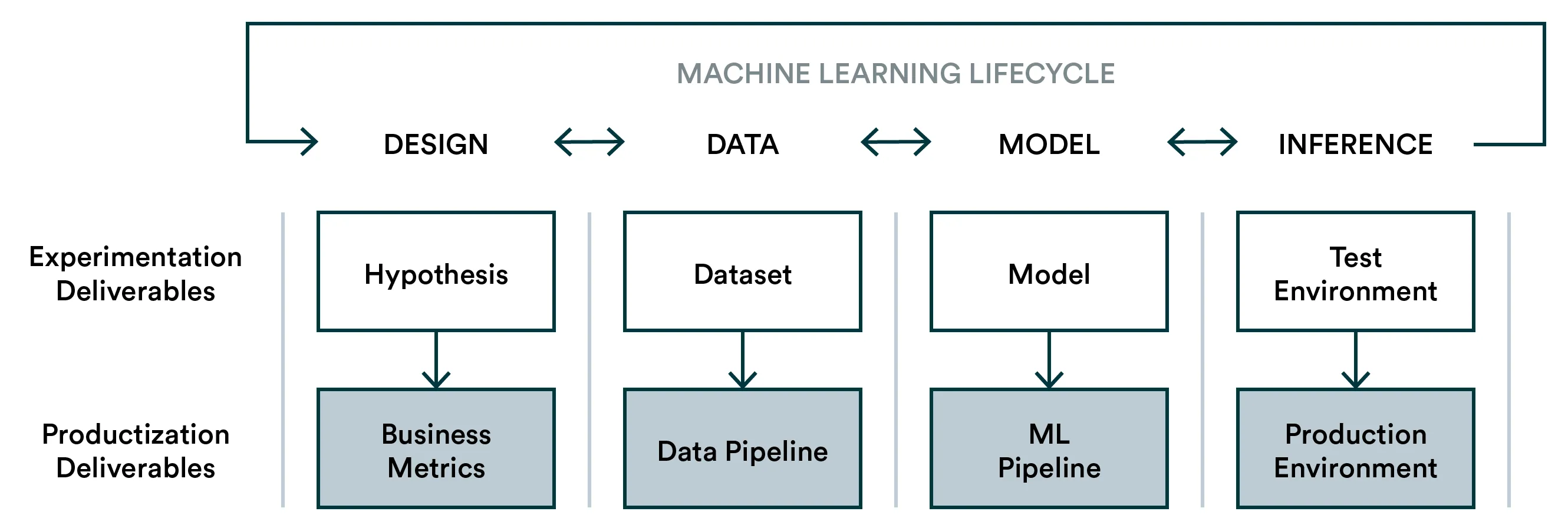
A diagram 👆 and table 👇 of a Machine Learning Lifecycle with Productization
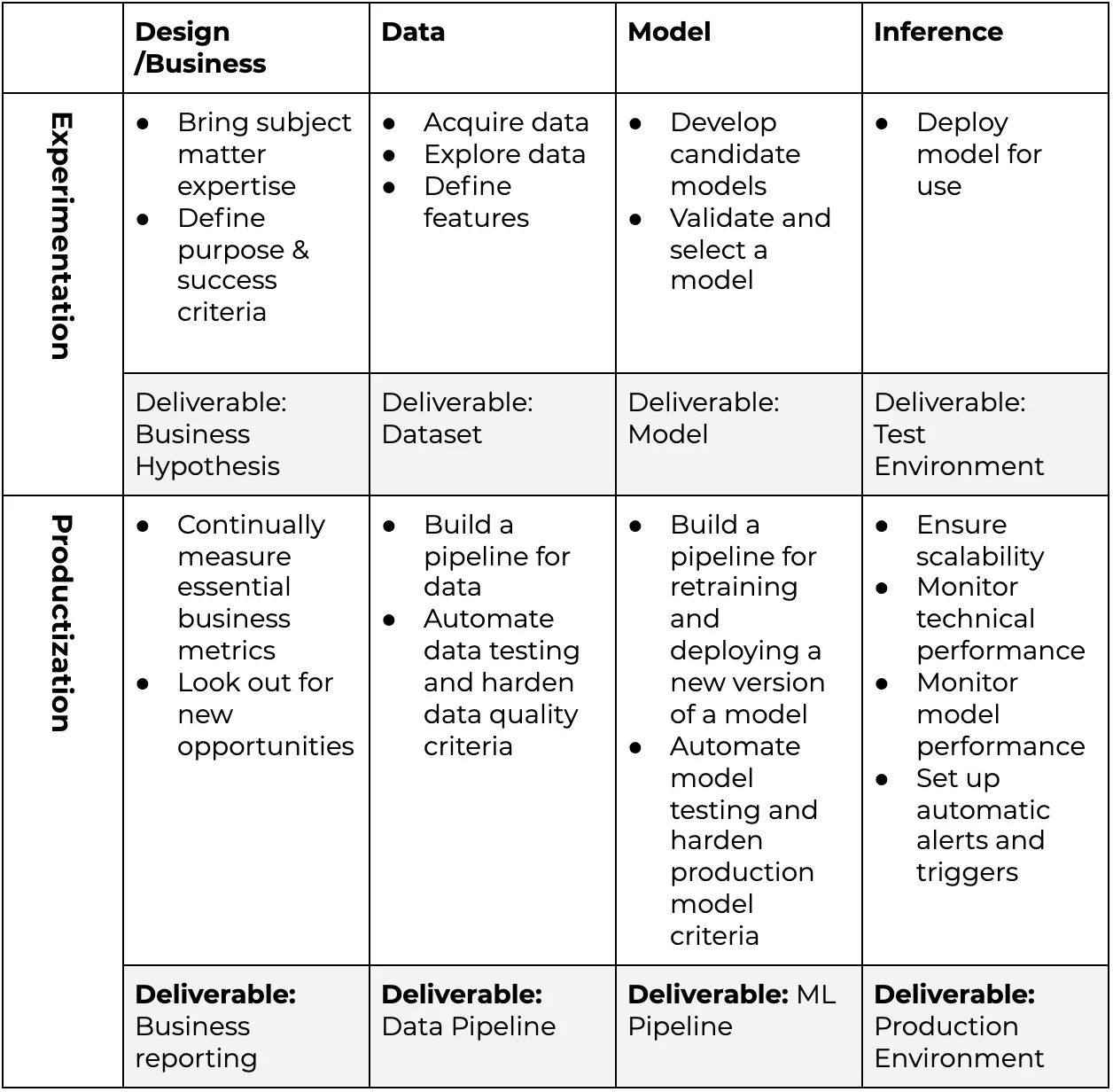
Productization should automate and harden everything related to the model lifecycle to ensure that machine learning can deliver value continuously similarly to any other product feature.
Let’s look at what this might mean in practice.
-
Design: The hypothesis might be that we can increase the average purchase size with a recommendation system. However, even after the hypothesis is proven correct, these metrics should still be available and perhaps expanded to show more underlying opportunities.
-
Data: A single dataset will provide value during the first iteration, but a productized machine learning system should continually produce high-quality data used in retraining. Furthermore, in real-world situations, the underlying data can change rapidly, for example, with trends.
-
Model: Similarly, model training should evolve to be more automatic (without risking quality) to avoid model degradation in production.
-
Inference: Initially, models may be deployed somewhat haphazardly or it may even be that data scientists test their model in isolation and leave the production for DevOps to handle. Ideally, data scientists should be involved with the production environment to ensure that the production model performance can be measured and actions can be taken if necessary.
How high-performing teams tackle the machine learning lifecycle
For some, considering the machine learning lifecycle as a production system is a no-brainer. The most efficient teams we see have built company-wide processes that ensure that every experiment is conducted with a clear path to production, and the steps may even happen simultaneously. In other words, data scientists are building pipelines from the get-go and DevOps are providing tools to make automation easy (and business is intimately involved).
The most pronounced difference between these two milestones happens at organizations that are early with their in-house data science team or work with consultants. Once an experiment shows signs of success, it becomes unclear who will own the process going forward and who needs to be involved.
An excellent example of tightly coupled experimentation and productization looks like at a company scale is Preligens’ write-up on their process: Part 1 and Part 2&3.
How Valohai makes the machine learning lifecycle easier to implement
Valohai is an MLOps platform with a focus on bridging the gap between experimentation and production.
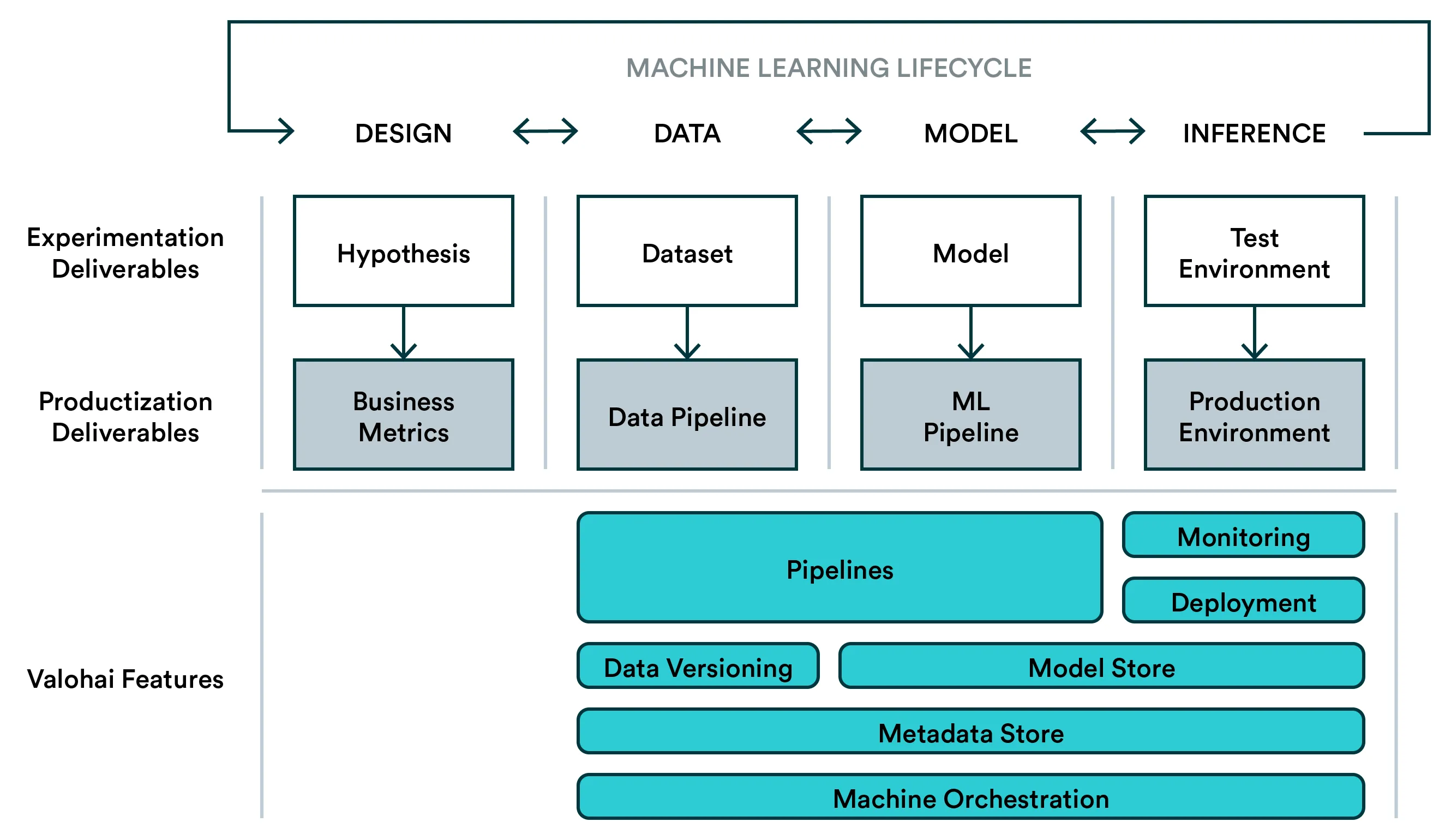
A diagram of a Machine Learning Lifecycle with Valohai features
Valohai provides value to the experimentation phase with experiment tracking and machine orchestration but at the same time enforces best practices such as ensuring dependencies. This will make moving from manual experimentation to automated production pipelines much easier.
For productization, Valohai allows you to build pipelines that contain anything from model training scripts with Tensorflow to synthetic data generation with Blender. And everything is versioned and stored as with individual experiments.