
We have seen a drastic uptake in software development delivery speed and rate over the years. Modern tooling and shared work methods (CI/CD, version control, microservices) have enabled companies to scale their throughput in software development exponentially.
A shared language enables new team members to hit the ground running and start contributing to existing projects as quickly as possible. There is very little to suggest that the same requirements for exponential delivery growth would not hold for machine learning too.
MLOps (machine learning operations) revolves around turning the process of creating a model into a machine learning pipeline. To achieve this, data scientists have to codify and componentize their work. While requiring extra effort compared to a single notebook and some manual actions, splitting work into components allows work to scale in a completely different way.
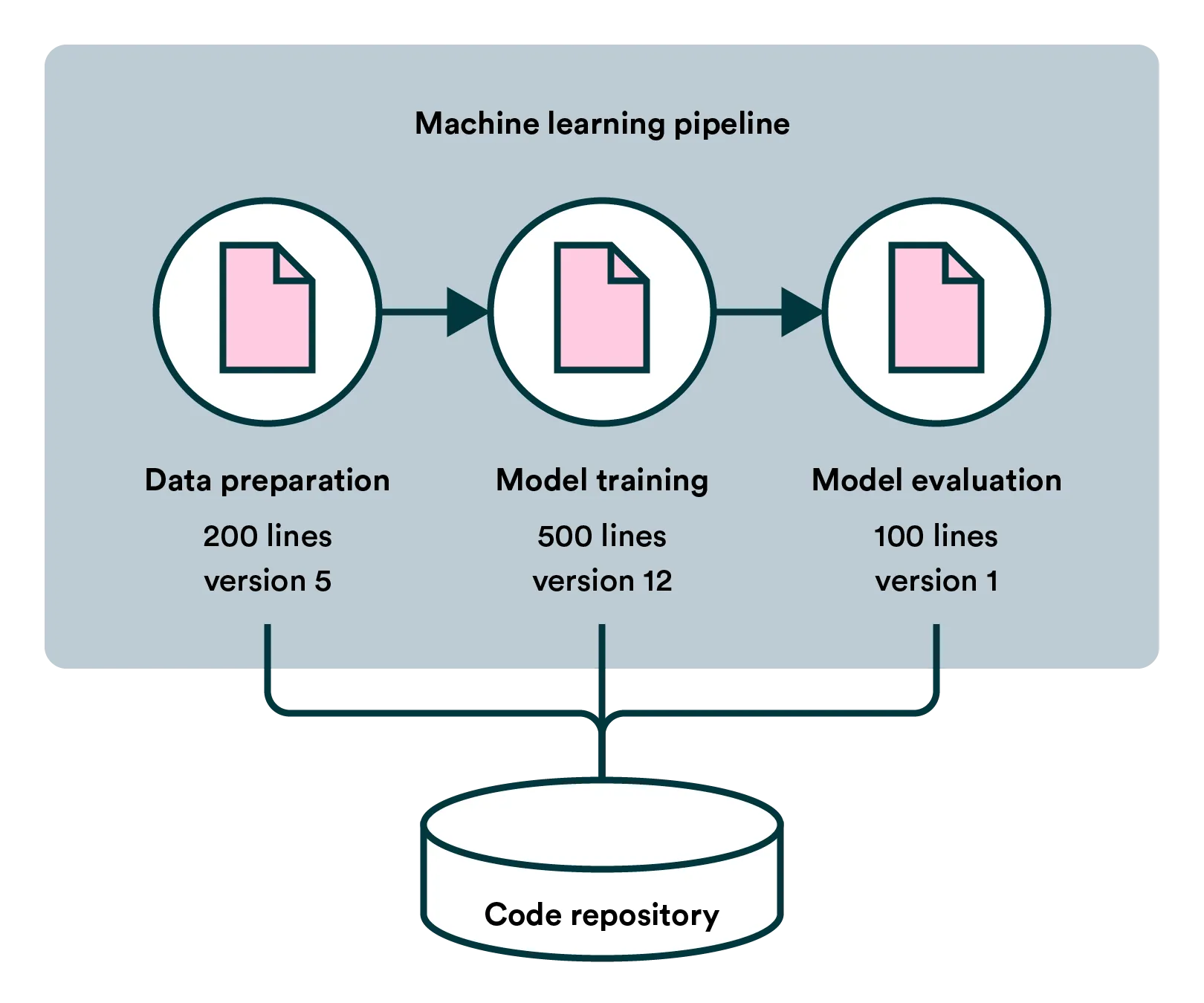
A single data scientist doesn’t need to create the whole pipeline, but rather a team can work on separate pieces such as data preprocessing, model training, and testing. These components can be shared across projects and iterated separately. As the complexity of model creation increases, so do the benefits of working around a shared pipeline.
This is very similar to what the microservice architecture has accomplished in larger development software projects. Smaller components are easier to understand, develop further, and release separately from other components.
Also, a pipeline consisting of various code pieces is inherently self-documenting — to some extent — and can be more easily handed to the next person than manual actions like interpreting data visualizations a certain way.
To learn more about machine learning pipelines, visit our deep dive on the topic, and for more on MLOps, download our free eBook.