Pointlessly staring at live logs and waiting for a miracle to happen is a huge time sink for data scientists everywhere. Instead, one should strive for an asynchronous workflow. In this article, we define asynchronous workflows, figure out some of the obstacles and finally guide you to a next article to look at a real-life example in action in Jupyter Notebooks.
What is a synchronous workflow?
Before we can say anything about asynchronous workflows, we have to define the synchronous counterpart. A synchronous workflow is the iterative cycle of creation & testing, where only one or the other is taking place at any one time. For example in software development, you write code, test it, then write some more code, then test that code, write even more code, test it again, code, test, code, test, code… repeat until IPO. Simple!
A synchronous workflow is often so ingrained into our way of doing things that we do not even recognize it as a thing. This is also the reason why it often isn’t even questioned. It is hard to question something that you don’t even realize exists.
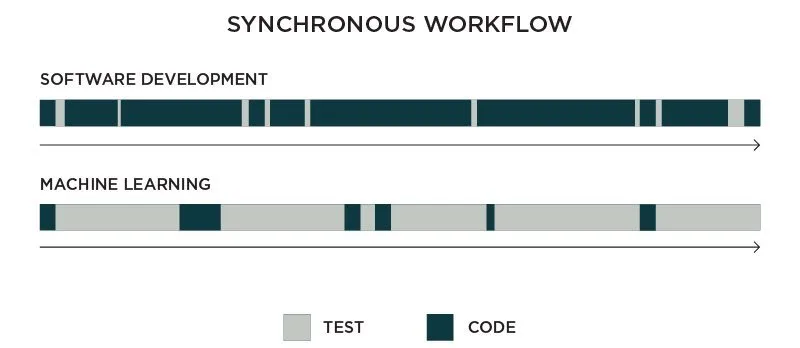 While the cycle is the same for both software development and machine learning, we can see that there is a huge difference between them.
While the cycle is the same for both software development and machine learning, we can see that there is a huge difference between them.
In software development, you usually get results quite fast. Imagine changing the layout of a web form or the physics formula of your mobile game. The time it takes to test the results is probably minuscule compared to the time it took to write the code. On the other hand, in machine learning, it is the inverse. The time it takes to change a few hyperparameters is often just a blink of an eye compared to the time it takes to see the training results.
The real measure of success is the number of experiments that can be crowded into 24 hours. – Thomas A. Edison
If we look at our timeline of machine learning from above and imagine it being 24 hours, it is obvious that we are not crowding many experiments into it. Waiting for training results is eating most of our time. Lucky for us, there is an important difference between coding and waiting:
One can only code one thing at a time, yet wait for infinite tests.
This is what we refer to as an asynchronous workflow.
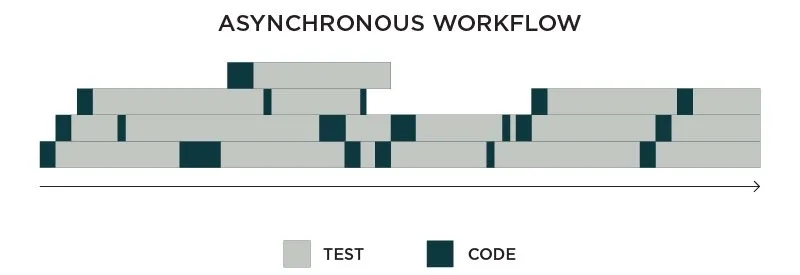 When you create a model and start training it, the point is not to get a cup of coffee and stare at the abyss of output logs for hours. Instead, start working on another experiment simultaneously, while the previous is still running. This is the asynchronous workflow for machine learning.
When you create a model and start training it, the point is not to get a cup of coffee and stare at the abyss of output logs for hours. Instead, start working on another experiment simultaneously, while the previous is still running. This is the asynchronous workflow for machine learning.
Why are we not doing it?
Why is it that people still stick with the synchronous cycle, while it is obvious that it is not optimal? There are a few common reasons:
Lack of tooling

Most of the tools are still made by software engineers for software engineers. In software engineering, the synchronous workflow is the norm. Write some code, press “play” and wait for results. If the core design philosophy of the tool is synchronous, then it is no wonder that workflows end up synchronous too.
Fear of losing work

When one starts branching out a lot and running dozens of things in parallel, there is increased mental chaos and fear of losing work or clicking the wrong thing. After all, doing just one thing at a time feels more straightforward and safer.
Too technical
 In some cases, the people who actually would prefer to work asynchronously, can’t do it. It requires extra skills like setting up servers or writing a lot of glue code, so they are forced to fall back to the default synchronous workflow.
In some cases, the people who actually would prefer to work asynchronously, can’t do it. It requires extra skills like setting up servers or writing a lot of glue code, so they are forced to fall back to the default synchronous workflow.
What would make us do it?
Given that we know that asynchronous workflows are the way to go and have listed some of the common barriers for it, what would be the requirements for a tool that makes us take the leap?
Simple tools

The tool needs to be as easy as the synchronous “competitor”. Imagine that you have two options for a tool that you’ll use all day long, every day. You are very likely to pick the easier one, even when you know that the more difficult to use would be more optimal. For example, if starting a new test is just one click for the synchronous tool, then doing the same with an asynchronous one can’t be three clicks and a CLI command. The pain of repeating that 30 times a day is going to make you fall back to your old ways.
Unintrusive

The shift from a single branch to dozens in parallel comes with an increased cognitive load. Just because it isn’t optimal to keep staring at the output logs of your live test, it doesn’t mean that you shouldn’t take a peek every now and then. On the other hand, you can’t have a constant stream of notification messages or dozen blinking lights on your screen while you are trying to code, either. A good asynchronous tool would take a backseat and be very careful in balancing your attention.
Safe
 The chaos of multiple simultaneous branches puts more pressure on bookkeeping. If the tool doesn’t organize and version control the avalanche of tests and experiments in a safe, straightforward and transparent way, you end up losing work or making cognitive errors along the way.
The chaos of multiple simultaneous branches puts more pressure on bookkeeping. If the tool doesn’t organize and version control the avalanche of tests and experiments in a safe, straightforward and transparent way, you end up losing work or making cognitive errors along the way.
Does the perfect tool exist?
Valohai is a machine learning platform that helps you execute on-demand experiments in the cloud with full version control. We have developed a Jupyter Notebook extension, which is specifically optimized to provide a smooth asynchronous workflow described in this article.
In the next blog post we’ll show you how Valohai’s Jupyter Notebook extension works in practice.