Smart recommendation in apps and websites is not an additional feature that differentiates top industries from others. Most users take for granted that they will be suggested products that they like. Collaborative filtering has been widely used to predict the interests of a user by collecting preference and tastes information from many users. It is often combined with content-based filtering, especially for tackling the cold-start problem . In the following tutorial, we will walk through building a clothes detection system which forms the basis of a robust fashion recommender engine.
How to deliver relevant recommendations before having access to large customer databases
The cold-start problem is faced by most industries when trying to build a business from scratch. They have few or no users yet, but still have to predict their interests to deliver a great customer experience. In fashion, it translates to being able to recommend clothes similar to the ones a customer looked at, liked or purchased.
The visual aspects of clothes are the core information that influences customers’ behaviour in fashion, often above price, brand and fabric. It makes sense to base the recommendation on the picture of a clothing item. However, clothes are often shown as part of outfits on models. In order to automatically extract visual features from a clothing item, it has to be isolated from the rest of the outfit on an image.
Getting the bounding box of clothing items with deep learning
The object detection task involves not only recognizing and classifying every object in an image, but also localizing each one by determining the bounding box around it. Deep learning has been widely used for object detection.
Model
About a year ago, Google released a new object detection API for Tensorflow . With it came several pre-implemented architectures with pre-trained weights on the COCO (Common Objects in Context) dataset , such as:
- SSD (Single-Shot Multibox Detector) with MobileNets
- SSD with Inception V2
- R-FCN (Region-based Fully-Convolutional Networks) with Resnet 101
- Faster RCNN (Region-based Convolutional Neural Networks) with Resnet 101
- Faster RCNN with Inception Resnet v2
All these architectures are based on classification neural networks pre-trained on ImageNet . The architecture we choose to use for clothing item detection is Faster RCNN with Inception Resnet v2 , Tensorflow’s second slowest but most accurate model on the COCO dataset .
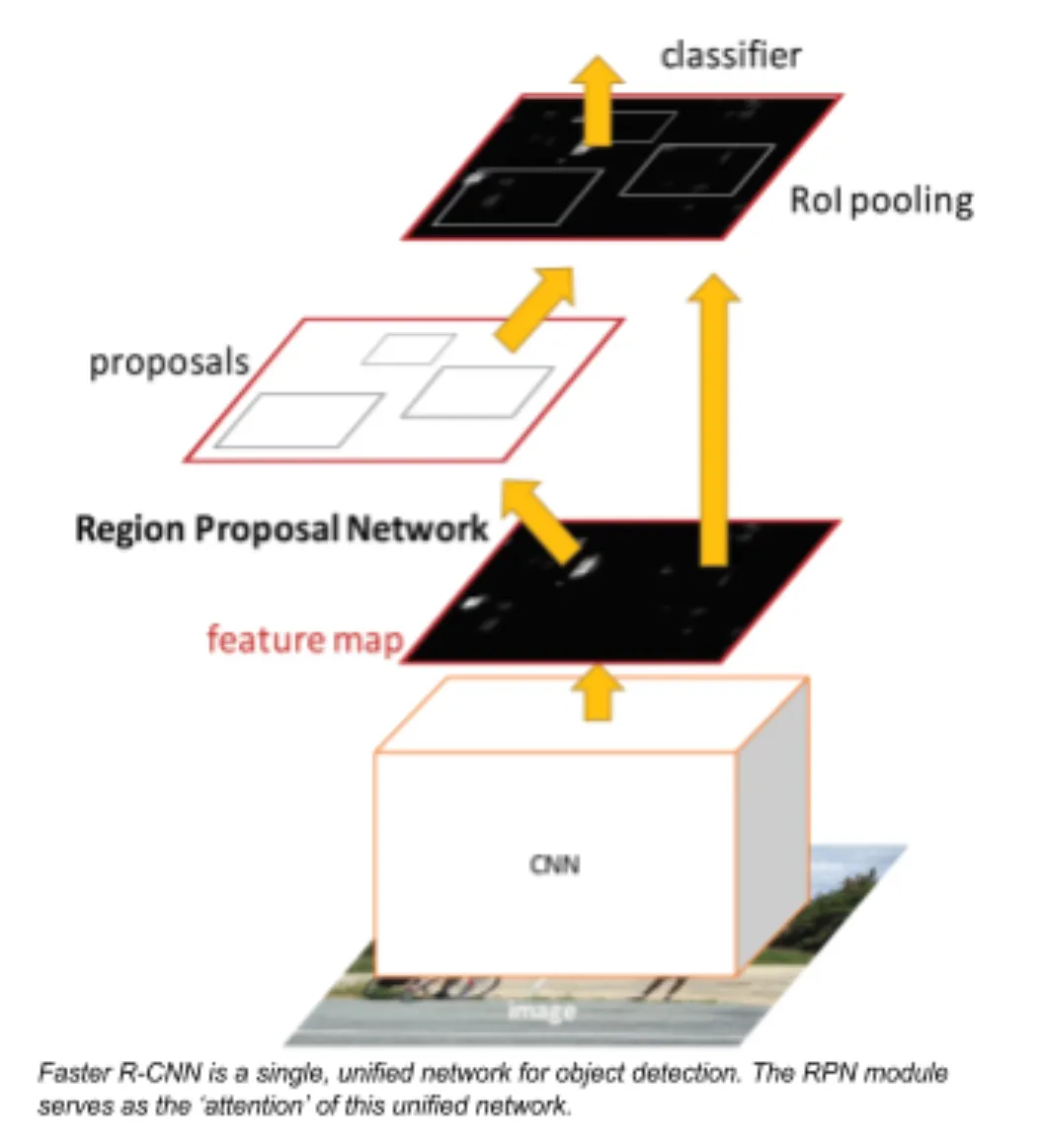
Faster RCNN is a state-of-the-art model for deep learning-based object detection. RCNNs depend on region proposal algorithms to hypothesize object locations and then run a convolutional neural net on top of each of these region proposals, with a softmax classifier at the end. Faster RCNNs introduced RPNs (Region Proposal Networks) that share full-image convolutional features with the detection network, thus enabling nearly cost-free region proposals.
For higher training and inference speed at the expense of accuracy, consider using SSD instead. SSD skips the region proposal step, and considers every bounding box in every location of the image simultaneously with its classification. Because it does everything in one step, it is one of the fastest deep learning model for object detection and still performs quite comparably as the state-of-the-art.
Dataset
The Multimedia Laboratory at the Chinese University of Hong Kong has put together DeepFashion : a large-scale fashion database . DeepFashion contains over 800 000 diverse fashion images ranging from well-posed shop images to unconstrained consumer photos. Each image in this dataset is labeled with 50 categories, 1000 descriptive attributes, bounding box and clothing landmarks.
The dataset has two levels of categories. The bottom level, composed of 50 categories, suffers from a high class imbalance, with some classes having less than 50 examples and others with more than 30000 examples. The top level has 3 generic categories:
- 1: “top” (upper-body clothes such as jackets, sweaters, tees, etc.)
- 2: “bottom” (lower-body clothes such as jeans, shorts, skirts, etc.)
- 3: “long” (full-body clothes such as dresses, coats, robes, etc.)

Since a fashion model on a picture often wears no more than one of each top-level category item, it is sufficient to predict bounding boxes of items belonging to the three top-level categories. This allows for a better class balance, therefore resulting in a more accurate model overall.
Installing Tensorflow’s object detection API
Tensorflow’s object detection API must be installed over a CPU/GPU Tensorflow installation. Instructions are provided on the Github repository , and we have built a Docker image for ease-of-use with Valohai . The Dockerfile is available on Github .
Formatting the data
The DeepFashion dataset already features a train/val/test partition of the images. The images are in JPEG format and the annotations in txt format which need to be merged into tfrecord files to be fed to the Tensorflow API. Tensorflow provides a generic script for the conversion which has been adapted for our specific dataset:
View code on GitHubBecause the DeepFashion dataset only has one bounding box annotation per image although several clothing items are often present on the same image, the images have to be cropped around the item of interest in the training and validation set. This is done by cropping randomly around the bounding box so that the width and height of the image are between 10% and 30% larger than those of the bounding box.
You can run this step on Valohai, named “Dataset preparation” in the “valohai.yaml” file .
Training the model
A default config file is provided in the object detection repository for the Faster RCNN with Inception Resnet v2 . At least the number of classes and paths to the tfrecord files must be adapted, and other training parameters can be modified such as the learning rates, the maximum number of steps, the data augmentation methods, etc. We provide a ready-to-use config file template for the DeepFashion dataset . A labelmap file must also be provided to account for the classes in our dataset .
The training script is the same as in the object detection repository. It has only be edited to output the Tensorflow logging to a “tensorflow.log” file as well as in the stderr channel of the terminal.
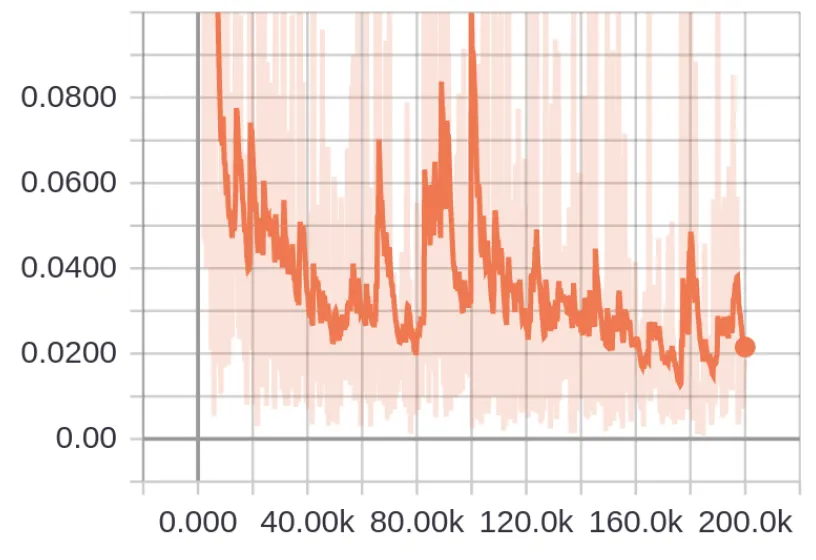
You can run this step on Valohai, named “Train model” in the “valohai.yaml” file . It takes as input the “train.record” and “val.record” files generated in the previous “Data preparation” step. The number of steps parameter “nsteps” is defaulted to 100 but must be set to higher values (around 200000) for the training to converge. The network has been trained 200 000 steps with a batch size of 1. The total loss of the network decreases as follows during training:
Resuming training
In case the number of steps for training is not sufficient and the training loss has not converged, it is possible to resume training from a previous model state, and continue training for another specified number of steps.
If needed, you can run this step on Valohai, named “Resume training” in the “valohai.yaml” file . It takes as input “fine_tuned_model.zip” (output of the “Train model” step) and outputs the same zipped file, with additional training done on the network.
Evaluating the model
The trained model is evaluated on the validation set, the AP (Average Precision) per category as well as the mAP (mean Average Precision) for a threshold of 0.5 IOU (Intersection Over Union) are tracked.
| Metrics | Values |
| AP@0.5IOU/top | 0.9799 |
| AP@0.5IOU/bottom | 0.9913 |
| AP@0.5IOU/long | 0.9640 |
| mAP@0.5IOU | 0.9784 |
AP computes the average value of precision as a function of recall over the interval from 0 to 1 for the recall. mAP is the mean of AP for all the categories. AP can be seen as a measure of retrieval effectiveness. For instance, if we retrieved pictures of tops using our model, about 97.99% of them would actually be pictures of tops.
You can run this step on Valohai, named “Evaluate model” in the “valohai.yaml” file . It takes as input “fine_tuned_model.zip” (output of the “Train model” or “Resume training” step) as well as the validation or test set in tfrecord format and prints the evaluation metrics. The output zipped folder “eval_val.zip” can be downloaded to visualize the detected bounding boxes on images with tensorboard.
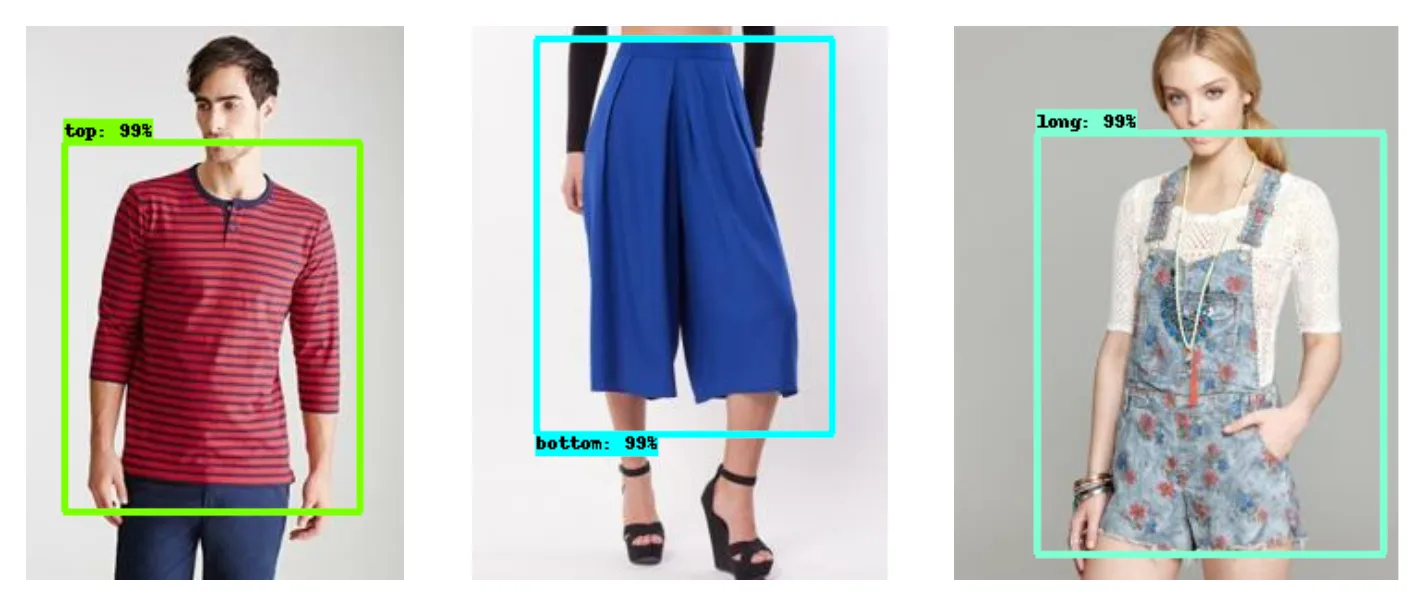
Here are some examples of detections on the test set:
Conclusion
Developing a recommender system from scratch can often seem overwhelming, especially when no database about users is yet accessible. It is not uncommon to default models behaviour to dummy recommendations (like most popular clothes) when tackling the cold-start problem . Therefore, being able to isolate clothing items from an outfit to perform more advanced queries at an early stage of development of a recommender engine proves itself irreplaceable.
Another major use case of the clothes detector is to be able to show information about a specific clothing item part of an outfit when the user hovers or clicks on it in an app or website. The same trained network can be used for this purpose.
Training object detection networks on the cloud such as Faster RCNN has never been easier than with Valohai. It takes 24 hours to train on the DeepFashion dataset with a p3.2xlarge instance (I didn’t even dare measure how much time it would have taken to train it locally), and the code from the repository can be adapted to train an object detector on your own dataset!